 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIMA at SemEval-2024 Task 10: History-Based Emotion Recognition in Hindi-English Code-Mixed Conversations
Jan 19, 2025

In this study, we introduce a solution to the SemEval 2024 Task 10 on subtask 1, dedicated to Emotion Recognition in Conversation (ERC) in code-mixed Hindi-English conversations. ERC in code-mixed conversations presents unique challenges, as existing models are typically trained on monolingual datasets and may not perform well on code-mixed data. To address this, we propose a series of models that incorporate both the previous and future context of the current utterance, as well as the sequential information of the conversation. To facilitate the processing of code-mixed data, we developed a Hinglish-to-English translation pipeline to translate the code-mixed conversations into English. We designed four different base models, each utilizing powerful pre-trained encoders to extract features from the input but with varying architectures. By ensembling all of these models, we developed a final model that outperforms all other baselines.
AIMA at SemEval-2024 Task 3: Simple Yet Powerful Emotion Cause Pair Analysis
Jan 19, 2025The SemEval-2024 Task 3 presents two subtasks focusing on emotion-cause pair extraction within conversational contexts. Subtask 1 revolves around the extraction of textual emotion-cause pairs, where causes are defined and annotated as textual spans within the conversation. Conversely, Subtask 2 extends the analysis to encompass multimodal cues, including language, audio, and vision, acknowledging instances where causes may not be exclusively represented in the textual data. Our proposed model for emotion-cause analysis is meticulously structured into three core segments: (i) embedding extraction, (ii) cause-pair extraction & emotion classification, and (iii) cause extraction using QA after finding pairs. Leveraging state-of-the-art techniques and fine-tuning on task-specific datasets, our model effectively unravels the intricate web of conversational dynamics and extracts subtle cues signifying causality in emotional expressions. Our team, AIMA, demonstrated strong performance in the SemEval-2024 Task 3 competition. We ranked as the 10th in subtask 1 and the 6th in subtask 2 out of 23 teams.
Emo3D: Metric and Benchmarking Dataset for 3D Facial Expression Generation from Emotion Description
Oct 02, 2024
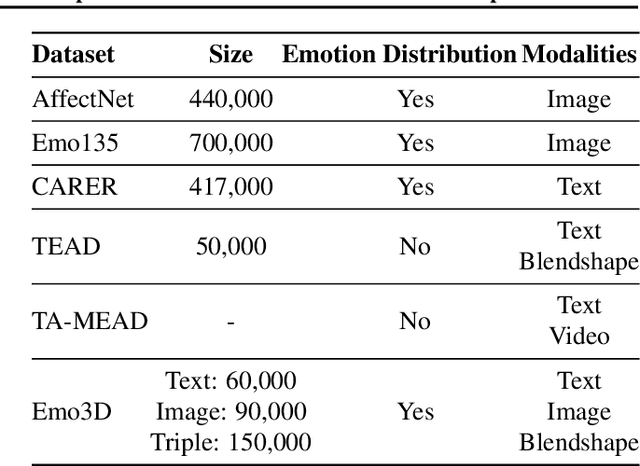

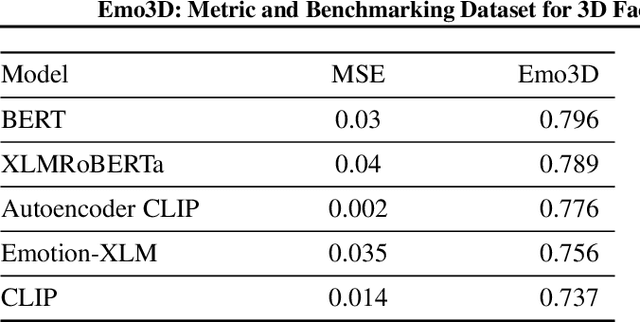
Existing 3D facial emotion modeling have been constrained by limited emotion classes and insufficient datasets. This paper introduces "Emo3D", an extensive "Text-Image-Expression dataset" spanning a wide spectrum of human emotions, each paired with images and 3D blendshapes. Leveraging Large Language Models (LLMs), we generate a diverse array of textual descriptions, facilitating the capture of a broad spectrum of emotional expressions. Using this unique dataset, we conduct a comprehensive evaluation of language-based models' fine-tuning and vision-language models like Contranstive Language Image Pretraining (CLIP) for 3D facial expression synthesis. We also introduce a new evaluation metric for this task to more directly measure the conveyed emotion. Our new evaluation metric, Emo3D, demonstrates its superiority over Mean Squared Error (MSE) metrics in assessing visual-text alignment and semantic richness in 3D facial expressions associated with human emotions. "Emo3D" has great applications in animation design, virtual reality, and emotional human-computer interaction.