 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchGuard: Adversarially Robust Anomaly Detection and Localization through Vision Transformers and Pseudo Anomalies
Jun 10, 2025Anomaly Detection (AD) and Anomaly Localization (AL) are crucial in fields that demand high reliability, such as medical imaging and industrial monitoring. However, current AD and AL approaches are often susceptible to adversarial attacks due to limitations in training data, which typically include only normal, unlabeled samples. This study introduces PatchGuard, an adversarially robust AD and AL method that incorporates pseudo anomalies with localization masks within a Vision Transformer (ViT)-based architecture to address these vulnerabilities. We begin by examining the essential properties of pseudo anomalies, and follow it by providing theoretical insights into the attention mechanisms required to enhance the adversarial robustness of AD and AL systems. We then present our approach, which leverages Foreground-Aware Pseudo-Anomalies to overcome the deficiencies of previous anomaly-aware methods. Our method incorporates these crafted pseudo-anomaly samples into a ViT-based framework, with adversarial training guided by a novel loss function designed to improve model robustness, as supported by our theoretical analysis. Experimental results on well-established industrial and medical datasets demonstrate that PatchGuard significantly outperforms previous methods in adversarial settings, achieving performance gains of $53.2\%$ in AD and $68.5\%$ in AL, while also maintaining competitive accuracy in non-adversarial settings. The code repository is available at https://github.com/rohban-lab/PatchGuard .
Scanning Trojaned Models Using Out-of-Distribution Samples
Jan 28, 2025



Scanning for trojan (backdoor) in deep neural networks is crucial due to their significant real-world applications. There has been an increasing focus on developing effective general trojan scanning methods across various trojan attacks. Despite advancements, there remains a shortage of methods that perform effectively without preconceived assumptions about the backdoor attack method. Additionally, we have observed that current methods struggle to identify classifiers trojaned using adversarial training. Motivated by these challenges, our study introduces a novel scanning method named TRODO (TROjan scanning by Detection of adversarial shifts in Out-of-distribution samples). TRODO leverages the concept of "blind spots"--regions where trojaned classifiers erroneously identify out-of-distribution (OOD) samples as in-distribution (ID). We scan for these blind spots by adversarially shifting OOD samples towards in-distribution. The increased likelihood of perturbed OOD samples being classified as ID serves as a signature for trojan detection. TRODO is both trojan and label mapping agnostic, effective even against adversarially trained trojaned classifiers. It is applicable even in scenarios where training data is absent, demonstrating high accuracy and adaptability across various scenarios and datasets, highlighting its potential as a robust trojan scanning strategy.
Mitigating Spurious Negative Pairs for Robust Industrial Anomaly Detection
Jan 26, 2025



Despite significant progress in Anomaly Detection (AD), the robustness of existing detection methods against adversarial attacks remains a challenge, compromising their reliability in critical real-world applications such as autonomous driving. This issue primarily arises from the AD setup, which assumes that training data is limited to a group of unlabeled normal samples, making the detectors vulnerable to adversarial anomaly samples during testing. Additionally, implementing adversarial training as a safeguard encounters difficulties, such as formulating an effective objective function without access to labels. An ideal objective function for adversarial training in AD should promote strong perturbations both within and between the normal and anomaly groups to maximize margin between normal and anomaly distribution. To address these issues, we first propose crafting a pseudo-anomaly group derived from normal group samples. Then, we demonstrate that adversarial training with contrastive loss could serve as an ideal objective function, as it creates both inter- and intra-group perturbations. However, we notice that spurious negative pairs compromise the conventional contrastive loss to achieve robust AD. Spurious negative pairs are those that should be closely mapped but are erroneously separated. These pairs introduce noise and misguide the direction of inter-group adversarial perturbations. To overcome the effect of spurious negative pairs, we define opposite pairs and adversarially pull them apart to strengthen inter-group perturbations. Experimental results demonstrate our superior performance in both clean and adversarial scenarios, with a 26.1% improvement in robust detection across various challenging benchmark datasets. The implementation of our work is available at: https://github.com/rohban-lab/COBRA.
Emo3D: Metric and Benchmarking Dataset for 3D Facial Expression Generation from Emotion Description
Oct 02, 2024
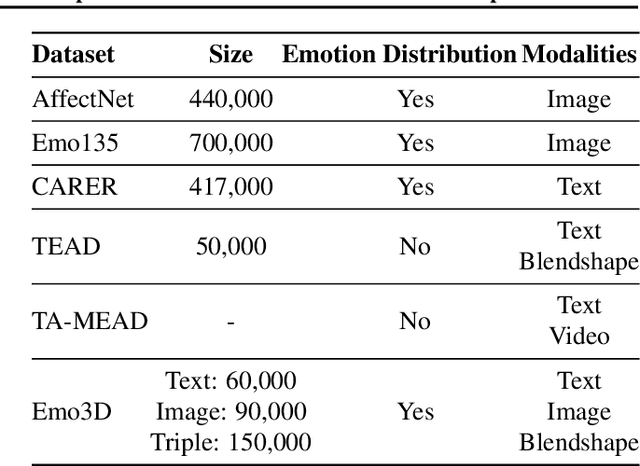

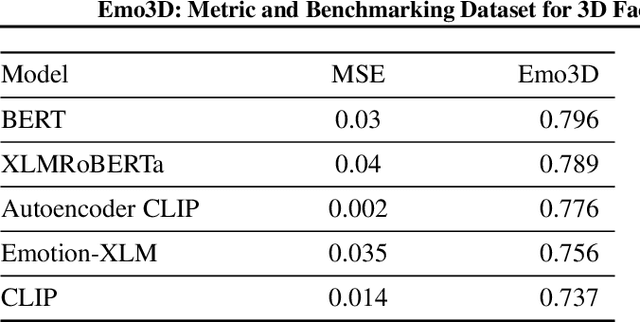
Existing 3D facial emotion modeling have been constrained by limited emotion classes and insufficient datasets. This paper introduces "Emo3D", an extensive "Text-Image-Expression dataset" spanning a wide spectrum of human emotions, each paired with images and 3D blendshapes. Leveraging Large Language Models (LLMs), we generate a diverse array of textual descriptions, facilitating the capture of a broad spectrum of emotional expressions. Using this unique dataset, we conduct a comprehensive evaluation of language-based models' fine-tuning and vision-language models like Contranstive Language Image Pretraining (CLIP) for 3D facial expression synthesis. We also introduce a new evaluation metric for this task to more directly measure the conveyed emotion. Our new evaluation metric, Emo3D, demonstrates its superiority over Mean Squared Error (MSE) metrics in assessing visual-text alignment and semantic richness in 3D facial expressions associated with human emotions. "Emo3D" has great applications in animation design, virtual reality, and emotional human-computer interaction.
Universal Novelty Detection Through Adaptive Contrastive Learning
Aug 20, 2024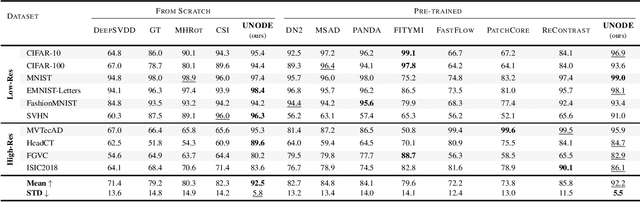
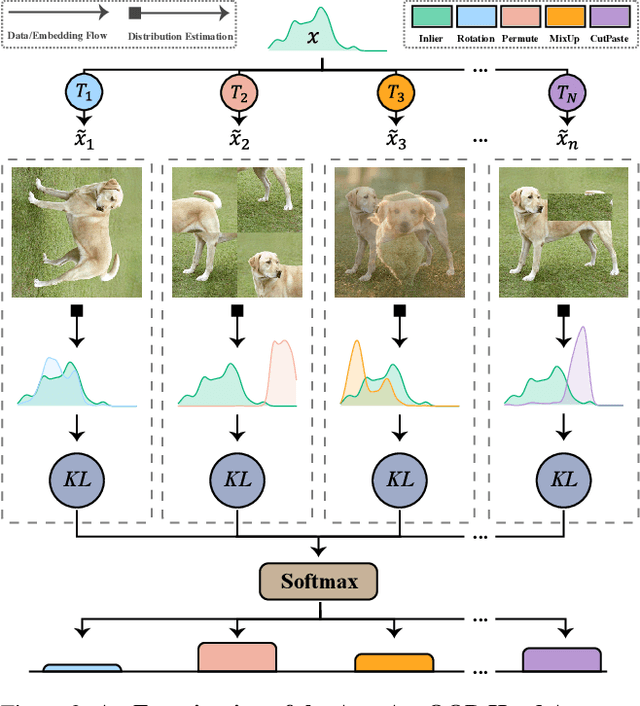


Novelty detection is a critical task for deploying machine learning models in the open world. A crucial property of novelty detection methods is universality, which can be interpreted as generalization across various distributions of training or test data. More precisely, for novelty detection, distribution shifts may occur in the training set or the test set. Shifts in the training set refer to cases where we train a novelty detector on a new dataset and expect strong transferability. Conversely, distribution shifts in the test set indicate the methods' performance when the trained model encounters a shifted test sample. We experimentally show that existing methods falter in maintaining universality, which stems from their rigid inductive biases. Motivated by this, we aim for more generalized techniques that have more adaptable inductive biases. In this context, we leverage the fact that contrastive learning provides an efficient framework to easily switch and adapt to new inductive biases through the proper choice of augmentations in forming the negative pairs. We propose a novel probabilistic auto-negative pair generation method AutoAugOOD, along with contrastive learning, to yield a universal novelty detector method. Our experiments demonstrate the superiority of our method under different distribution shifts in various image benchmark datasets. Notably, our method emerges universality in the lens of adaptability to different setups of novelty detection, including one-class, unlabeled multi-class, and labeled multi-class settings. Code: https://github.com/mojtaba-nafez/UNODE
ClusterSeq: Enhancing Sequential Recommender Systems with Clustering based Meta-Learning
Jul 25, 2023In practical scenarios, the effectiveness of sequential recommendation systems is hindered by the user cold-start problem, which arises due to limited interactions for accurately determining user preferences. Previous studies have attempted to address this issue by combining meta-learning with user and item-side information. However, these approaches face inherent challenges in modeling user preference dynamics, particularly for "minor users" who exhibit distinct preferences compared to more common or "major users." To overcome these limitations, we present a novel approach called ClusterSeq, a Meta-Learning Clustering-Based Sequential Recommender System. ClusterSeq leverages dynamic information in the user sequence to enhance item prediction accuracy, even in the absence of side information. This model preserves the preferences of minor users without being overshadowed by major users, and it capitalizes on the collective knowledge of users within the same cluster. Extensive experiments conducted on various benchmark datasets validate the effectiveness of ClusterSeq. Empirical results consistently demonstrate that ClusterSeq outperforms several state-of-the-art meta-learning recommenders. Notably, compared to existing meta-learning methods, our proposed approach achieves a substantial improvement of 16-39% in Mean Reciprocal Rank (MRR).
A Novel Experts Advice Aggregation Framework Using Deep Reinforcement Learning for Portfolio Management
Dec 29, 2022


Solving portfolio management problems using deep reinforcement learning has been getting much attention in finance for a few years. We have proposed a new method using experts signals and historical price data to feed into our reinforcement learning framework. Although experts signals have been used in previous works in the field of finance, as far as we know, it is the first time this method, in tandem with deep RL, is used to solve the financial portfolio management problem. Our proposed framework consists of a convolutional network for aggregating signals, another convolutional network for historical price data, and a vanilla network. We used the Proximal Policy Optimization algorithm as the agent to process the reward and take action in the environment. The results suggested that, on average, our framework could gain 90 percent of the profit earned by the best expert.
Tag Recommendation for Online Q&A Communities based on BERT Pre-Training Technique
Oct 10, 2020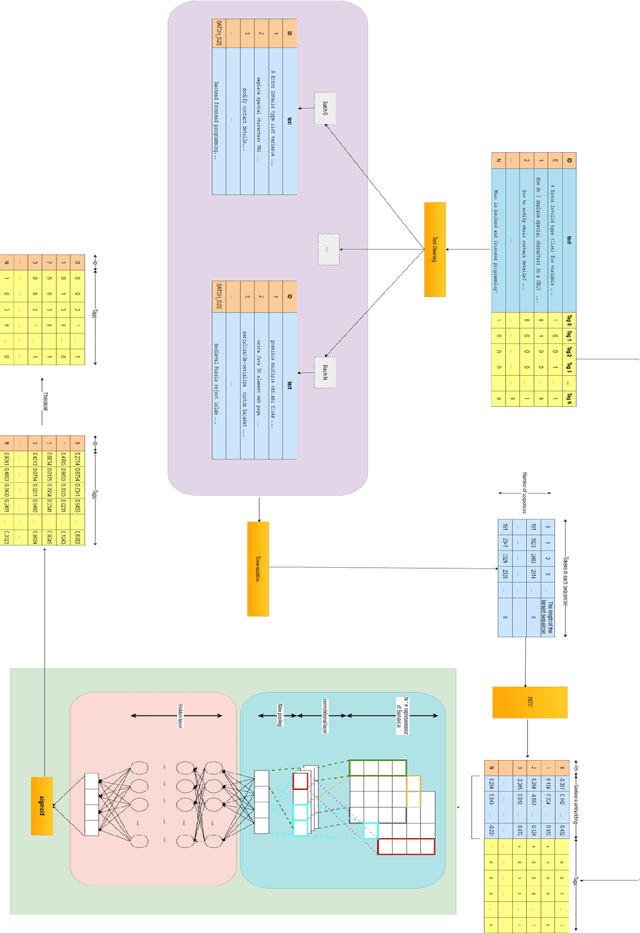
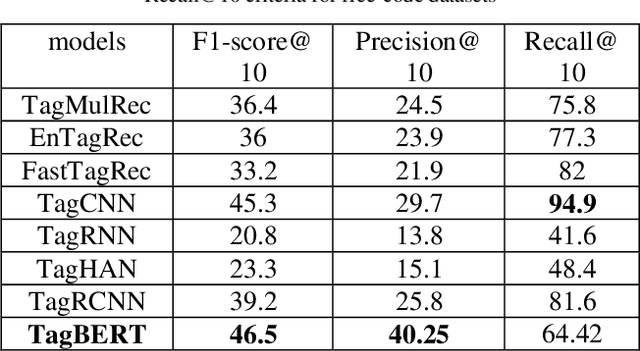
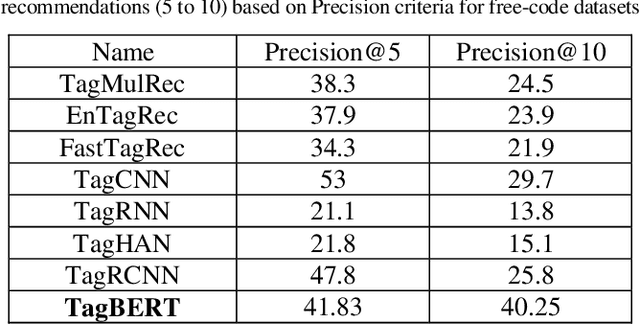
Online Q&A and open source communities use tags and keywords to index, categorize, and search for specific content. The most obvious advantage of tag recommendation is the correct classification of information. In this study, we used the BERT pre-training technique in tag recommendation task for online Q&A and open-source communities for the first time. Our evaluation on freecode datasets show that the proposed method, called TagBERT, is more accurate compared to deep learning and other baseline methods. Moreover, our model achieved a high stability by solving the problem of previous researches, where increasing the number of tag recommendations significantly reduced model performance.
Using Experts' Opinions in Machine Learning Tasks
Aug 10, 2020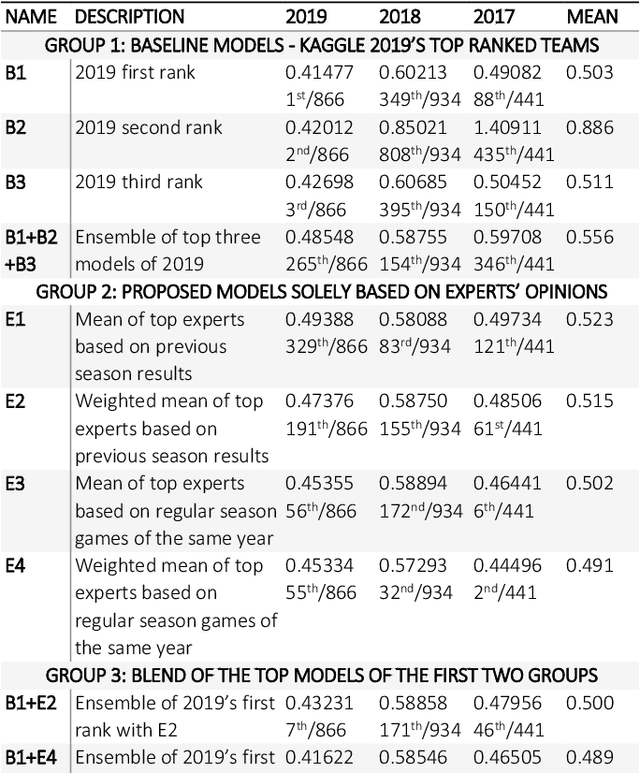
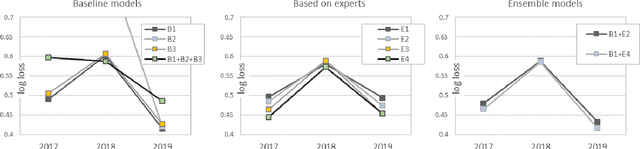
In machine learning tasks, especially in the tasks of prediction, scientists tend to rely solely on available historical data and disregard unproven insights, such as experts' opinions, polls, and betting odds. In this paper, we propose a general three-step framework for utilizing experts' insights in machine learning tasks and build four concrete models for a sports game prediction case study. For the case study, we have chosen the task of predicting NCAA Men's Basketball games, which has been the focus of a group of Kaggle competitions in recent years. Results highly suggest that the good performance and high scores of the past models are a result of chance, and not because of a good-performing and stable model. Furthermore, our proposed models can achieve more steady results with lower log loss average (best at 0.489) compared to the top solutions of the 2019 competition (>0.503), and reach the top 1%, 10% and 1% in the 2017, 2018 and 2019 leaderboards, respectively.
Predicting Subjective Features from Questions on QA Websites using BERT
Mar 25, 2020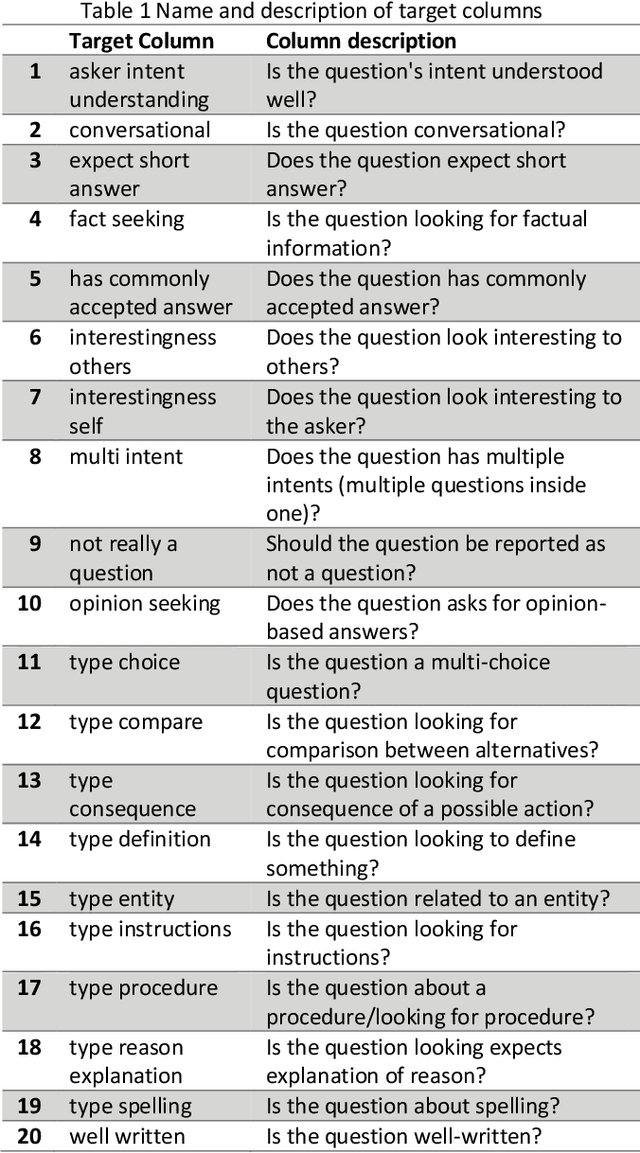
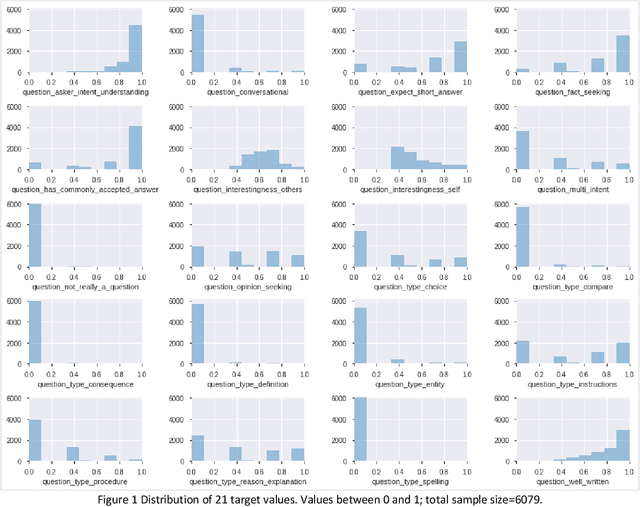
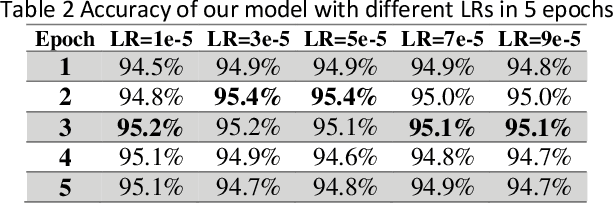
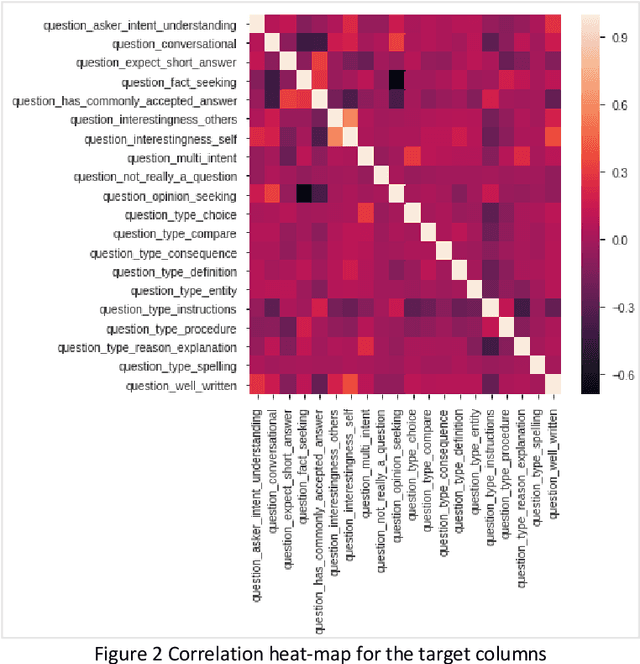
Community Question-Answering websites, such as StackOverflow and Quora, expect users to follow specific guidelines in order to maintain content quality. These systems mainly rely on community reports for assessing contents, which has serious problems such as the slow handling of violations, the loss of normal and experienced users' time, the low quality of some reports, and discouraging feedback to new users. Therefore, with the overall goal of providing solutions for automating moderation actions in Q&A websites, we aim to provide a model to predict 20 quality or subjective aspects of questions in QA websites. To this end, we used data gathered by the CrowdSource team at Google Research in 2019 and fine-tuned pre-trained BERT model on our problem. Based on evaluation by Mean-Squared-Error (MSE), model achieved the value of 0.046 after 2 epochs of training, which did not improve substantially in the next ones. Results confirm that by simple fine-tuning, we can achieve accurate models in little time and on less amount of data.