 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWith Argus Eyes: Assessing Retrieval Gaps via Uncertainty Scoring to Detect and Remedy Retrieval Blind Spots
Feb 10, 2026Reliable retrieval-augmented generation (RAG) systems depend fundamentally on the retriever's ability to find relevant information. We show that neural retrievers used in RAG systems have blind spots, which we define as the failure to retrieve entities that are relevant to the query, but have low similarity to the query embedding. We investigate the training-induced biases that cause such blind spot entities to be mapped to inaccessible parts of the embedding space, resulting in low retrievability. Using a large-scale dataset constructed from Wikidata relations and first paragraphs of Wikipedia, and our proposed Retrieval Probability Score (RPS), we show that blind spot risk in standard retrievers (e.g., CONTRIEVER, REASONIR) can be predicted pre-index from entity embedding geometry, avoiding expensive retrieval evaluations. To address these blind spots, we introduce ARGUS, a pipeline that enables the retrievability of high-risk (low-RPS) entities through targeted document augmentation from a knowledge base (KB), first paragraphs of Wikipedia, in our case. Extensive experiments on BRIGHT, IMPLIRET, and RAR-B show that ARGUS achieves consistent improvements across all evaluated retrievers (averaging +3.4 nDCG@5 and +4.5 nDCG@10 absolute points), with substantially larger gains in challenging subsets. These results establish that preemptively remedying blind spots is critical for building robust and trustworthy RAG systems (Code and Data).
ImpliRet: Benchmarking the Implicit Fact Retrieval Challenge
Jun 17, 2025Retrieval systems are central to many NLP pipelines, but often rely on surface-level cues such as keyword overlap and lexical semantic similarity. To evaluate retrieval beyond these shallow signals, recent benchmarks introduce reasoning-heavy queries; however, they primarily shift the burden to query-side processing techniques -- like prompting or multi-hop retrieval -- that can help resolve complexity. In contrast, we present ImpliRet, a benchmark that shifts the reasoning challenge to document-side processing: The queries are simple, but relevance depends on facts stated implicitly in documents through temporal (e.g., resolving "two days ago"), arithmetic, and world knowledge relationships. We evaluate a range of sparse and dense retrievers, all of which struggle in this setting: the best nDCG@10 is only 15.07%. We also test whether long-context models can overcome this limitation. But even with a short context of only ten documents, including the positive document, GPT-4.1 scores only 35.06%, showing that document-side reasoning remains a challenge. Our codes are available at github.com/ZeinabTaghavi/IMPLIRET.Contribution.
Scanning Trojaned Models Using Out-of-Distribution Samples
Jan 28, 2025



Scanning for trojan (backdoor) in deep neural networks is crucial due to their significant real-world applications. There has been an increasing focus on developing effective general trojan scanning methods across various trojan attacks. Despite advancements, there remains a shortage of methods that perform effectively without preconceived assumptions about the backdoor attack method. Additionally, we have observed that current methods struggle to identify classifiers trojaned using adversarial training. Motivated by these challenges, our study introduces a novel scanning method named TRODO (TROjan scanning by Detection of adversarial shifts in Out-of-distribution samples). TRODO leverages the concept of "blind spots"--regions where trojaned classifiers erroneously identify out-of-distribution (OOD) samples as in-distribution (ID). We scan for these blind spots by adversarially shifting OOD samples towards in-distribution. The increased likelihood of perturbed OOD samples being classified as ID serves as a signature for trojan detection. TRODO is both trojan and label mapping agnostic, effective even against adversarially trained trojaned classifiers. It is applicable even in scenarios where training data is absent, demonstrating high accuracy and adaptability across various scenarios and datasets, highlighting its potential as a robust trojan scanning strategy.
A Contrastive Teacher-Student Framework for Novelty Detection under Style Shifts
Jan 28, 2025



There have been several efforts to improve Novelty Detection (ND) performance. However, ND methods often suffer significant performance drops under minor distribution shifts caused by changes in the environment, known as style shifts. This challenge arises from the ND setup, where the absence of out-of-distribution (OOD) samples during training causes the detector to be biased toward the dominant style features in the in-distribution (ID) data. As a result, the model mistakenly learns to correlate style with core features, using this shortcut for detection. Robust ND is crucial for real-world applications like autonomous driving and medical imaging, where test samples may have different styles than the training data. Motivated by this, we propose a robust ND method that crafts an auxiliary OOD set with style features similar to the ID set but with different core features. Then, a task-based knowledge distillation strategy is utilized to distinguish core features from style features and help our model rely on core features for discriminating crafted OOD and ID sets. We verified the effectiveness of our method through extensive experimental evaluations on several datasets, including synthetic and real-world benchmarks, against nine different ND methods.
Killing it with Zero-Shot: Adversarially Robust Novelty Detection
Jan 25, 2025



Novelty Detection (ND) plays a crucial role in machine learning by identifying new or unseen data during model inference. This capability is especially important for the safe and reliable operation of automated systems. Despite advances in this field, existing techniques often fail to maintain their performance when subject to adversarial attacks. Our research addresses this gap by marrying the merits of nearest-neighbor algorithms with robust features obtained from models pretrained on ImageNet. We focus on enhancing the robustness and performance of ND algorithms. Experimental results demonstrate that our approach significantly outperforms current state-of-the-art methods across various benchmarks, particularly under adversarial conditions. By incorporating robust pretrained features into the k-NN algorithm, we establish a new standard for performance and robustness in the field of robust ND. This work opens up new avenues for research aimed at fortifying machine learning systems against adversarial vulnerabilities. Our implementation is publicly available at https://github.com/rohban-lab/ZARND.
Sharif-STR at SemEval-2024 Task 1: Transformer as a Regression Model for Fine-Grained Scoring of Textual Semantic Relations
Jul 17, 2024



Semantic Textual Relatedness holds significant relevance in Natural Language Processing, finding applications across various domains. Traditionally, approaches to STR have relied on knowledge-based and statistical methods. However, with the emergence of Large Language Models, there has been a paradigm shift, ushering in new methodologies. In this paper, we delve into the investigation of sentence-level STR within Track A (Supervised) by leveraging fine-tuning techniques on the RoBERTa transformer. Our study focuses on assessing the efficacy of this approach across different languages. Notably, our findings indicate promising advancements in STR performance, particularly in Latin languages. Specifically, our results demonstrate notable improvements in English, achieving a correlation of 0.82 and securing a commendable 19th rank. Similarly, in Spanish, we achieved a correlation of 0.67, securing the 15th position. However, our approach encounters challenges in languages like Arabic, where we observed a correlation of only 0.38, resulting in a 20th rank.
* 10 pages, 9 figures, 4 tables
Sharif-MGTD at SemEval-2024 Task 8: A Transformer-Based Approach to Detect Machine Generated Text
Jul 16, 2024Detecting Machine-Generated Text (MGT) has emerged as a significant area of study within Natural Language Processing. While language models generate text, they often leave discernible traces, which can be scrutinized using either traditional feature-based methods or more advanced neural language models. In this research, we explore the effectiveness of fine-tuning a RoBERTa-base transformer, a powerful neural architecture, to address MGT detection as a binary classification task. Focusing specifically on Subtask A (Monolingual-English) within the SemEval-2024 competition framework, our proposed system achieves an accuracy of 78.9% on the test dataset, positioning us at 57th among participants. Our study addresses this challenge while considering the limited hardware resources, resulting in a system that excels at identifying human-written texts but encounters challenges in accurately discerning MGTs.
Imaginations of WALL-E : Reconstructing Experiences with an Imagination-Inspired Module for Advanced AI Systems
Aug 20, 2023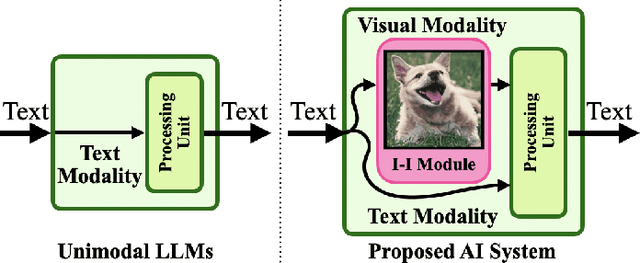



In this paper, we introduce a novel Artificial Intelligence (AI) system inspired by the philosophical and psychoanalytical concept of imagination as a ``Re-construction of Experiences". Our AI system is equipped with an imagination-inspired module that bridges the gap between textual inputs and other modalities, enriching the derived information based on previously learned experiences. A unique feature of our system is its ability to formulate independent perceptions of inputs. This leads to unique interpretations of a concept that may differ from human interpretations but are equally valid, a phenomenon we term as ``Interpretable Misunderstanding". We employ large-scale models, specifically a Multimodal Large Language Model (MLLM), enabling our proposed system to extract meaningful information across modalities while primarily remaining unimodal. We evaluated our system against other large language models across multiple tasks, including emotion recognition and question-answering, using a zero-shot methodology to ensure an unbiased scenario that may happen by fine-tuning. Significantly, our system outperformed the best Large Language Models (LLM) on the MELD, IEMOCAP, and CoQA datasets, achieving Weighted F1 (WF1) scores of 46.74%, 25.23%, and Overall F1 (OF1) score of 17%, respectively, compared to 22.89%, 12.28%, and 7% from the well-performing LLM. The goal is to go beyond the statistical view of language processing and tie it to human concepts such as philosophy and psychoanalysis. This work represents a significant advancement in the development of imagination-inspired AI systems, opening new possibilities for AI to generate deep and interpretable information across modalities, thereby enhancing human-AI interaction.
A Change of Heart: Improving Speech Emotion Recognition through Speech-to-Text Modality Conversion
Jul 21, 2023

Speech Emotion Recognition (SER) is a challenging task. In this paper, we introduce a modality conversion concept aimed at enhancing emotion recognition performance on the MELD dataset. We assess our approach through two experiments: first, a method named Modality-Conversion that employs automatic speech recognition (ASR) systems, followed by a text classifier; second, we assume perfect ASR output and investigate the impact of modality conversion on SER, this method is called Modality-Conversion++. Our findings indicate that the first method yields substantial results, while the second method outperforms state-of-the-art (SOTA) speech-based approaches in terms of SER weighted-F1 (WF1) score on the MELD dataset. This research highlights the potential of modality conversion for tasks that can be conducted in alternative modalities.