 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUndesirable Memorization in Large Language Models: A Survey
Oct 03, 2024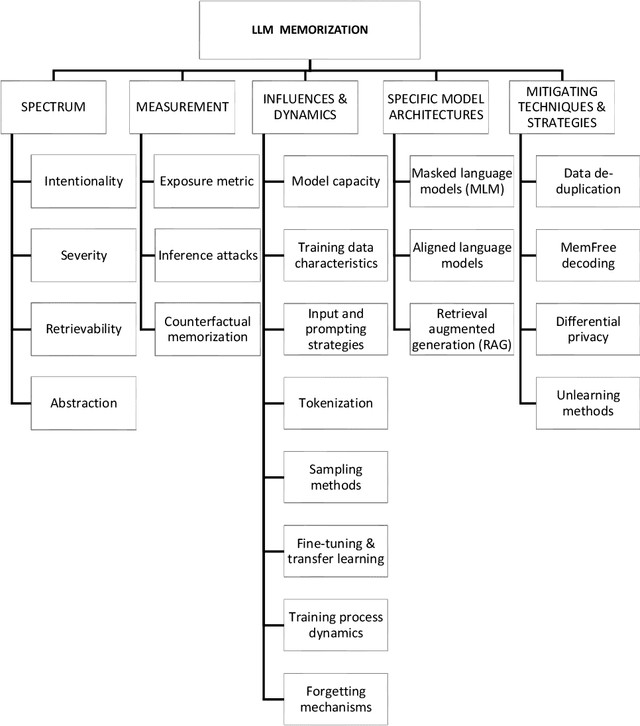


While recent research increasingly showcases the remarkable capabilities of Large Language Models (LLMs), it's vital to confront their hidden pitfalls. Among these challenges, the issue of memorization stands out, posing significant ethical and legal risks. In this paper, we presents a Systematization of Knowledge (SoK) on the topic of memorization in LLMs. Memorization is the effect that a model tends to store and reproduce phrases or passages from the training data and has been shown to be the fundamental issue to various privacy and security attacks against LLMs. We begin by providing an overview of the literature on the memorization, exploring it across five key dimensions: intentionality, degree, retrievability, abstraction, and transparency. Next, we discuss the metrics and methods used to measure memorization, followed by an analysis of the factors that contribute to memorization phenomenon. We then examine how memorization manifests itself in specific model architectures and explore strategies for mitigating these effects. We conclude our overview by identifying potential research topics for the near future: to develop methods for balancing performance and privacy in LLMs, and the analysis of memorization in specific contexts, including conversational agents, retrieval-augmented generation, multilingual language models, and diffusion language models.
A Change of Heart: Improving Speech Emotion Recognition through Speech-to-Text Modality Conversion
Jul 21, 2023

Speech Emotion Recognition (SER) is a challenging task. In this paper, we introduce a modality conversion concept aimed at enhancing emotion recognition performance on the MELD dataset. We assess our approach through two experiments: first, a method named Modality-Conversion that employs automatic speech recognition (ASR) systems, followed by a text classifier; second, we assume perfect ASR output and investigate the impact of modality conversion on SER, this method is called Modality-Conversion++. Our findings indicate that the first method yields substantial results, while the second method outperforms state-of-the-art (SOTA) speech-based approaches in terms of SER weighted-F1 (WF1) score on the MELD dataset. This research highlights the potential of modality conversion for tasks that can be conducted in alternative modalities.