 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Language Models Prioritize Contextual Grammatical Cues?
Oct 04, 2024Transformer-based language models have shown an excellent ability to effectively capture and utilize contextual information. Although various analysis techniques have been used to quantify and trace the contribution of single contextual cues to a target task such as subject-verb agreement or coreference resolution, scenarios in which multiple relevant cues are available in the context remain underexplored. In this paper, we investigate how language models handle gender agreement when multiple gender cue words are present, each capable of independently disambiguating a target gender pronoun. We analyze two widely used Transformer-based models: BERT, an encoder-based, and GPT-2, a decoder-based model. Our analysis employs two complementary approaches: context mixing analysis, which tracks information flow within the model, and a variant of activation patching, which measures the impact of cues on the model's prediction. We find that BERT tends to prioritize the first cue in the context to form both the target word representations and the model's prediction, while GPT-2 relies more on the final cue. Our findings reveal striking differences in how encoder-based and decoder-based models prioritize and use contextual information for their predictions.
data2lang2vec: Data Driven Typological Features Completion
Sep 25, 2024Language typology databases enhance multi-lingual Natural Language Processing (NLP) by improving model adaptability to diverse linguistic structures. The widely-used lang2vec toolkit integrates several such databases, but its coverage remains limited at 28.9\%. Previous work on automatically increasing coverage predicts missing values based on features from other languages or focuses on single features, we propose to use textual data for better-informed feature prediction. To this end, we introduce a multi-lingual Part-of-Speech (POS) tagger, achieving over 70\% accuracy across 1,749 languages, and experiment with external statistical features and a variety of machine learning algorithms. We also introduce a more realistic evaluation setup, focusing on likely to be missing typology features, and show that our approach outperforms previous work in both setups.
Imaginations of WALL-E : Reconstructing Experiences with an Imagination-Inspired Module for Advanced AI Systems
Aug 20, 2023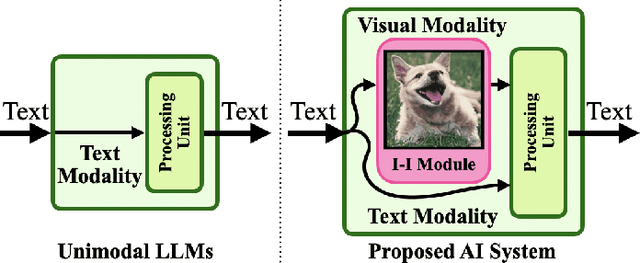



In this paper, we introduce a novel Artificial Intelligence (AI) system inspired by the philosophical and psychoanalytical concept of imagination as a ``Re-construction of Experiences". Our AI system is equipped with an imagination-inspired module that bridges the gap between textual inputs and other modalities, enriching the derived information based on previously learned experiences. A unique feature of our system is its ability to formulate independent perceptions of inputs. This leads to unique interpretations of a concept that may differ from human interpretations but are equally valid, a phenomenon we term as ``Interpretable Misunderstanding". We employ large-scale models, specifically a Multimodal Large Language Model (MLLM), enabling our proposed system to extract meaningful information across modalities while primarily remaining unimodal. We evaluated our system against other large language models across multiple tasks, including emotion recognition and question-answering, using a zero-shot methodology to ensure an unbiased scenario that may happen by fine-tuning. Significantly, our system outperformed the best Large Language Models (LLM) on the MELD, IEMOCAP, and CoQA datasets, achieving Weighted F1 (WF1) scores of 46.74%, 25.23%, and Overall F1 (OF1) score of 17%, respectively, compared to 22.89%, 12.28%, and 7% from the well-performing LLM. The goal is to go beyond the statistical view of language processing and tie it to human concepts such as philosophy and psychoanalysis. This work represents a significant advancement in the development of imagination-inspired AI systems, opening new possibilities for AI to generate deep and interpretable information across modalities, thereby enhancing human-AI interaction.