 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLPL SHROOM at SemEval2024 Task 06: A comprehensive study on models ability to detect hallucination
Apr 09, 2024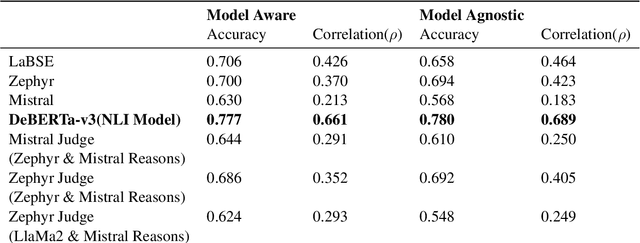
Language models, particularly generative models, are susceptible to hallucinations, generating outputs that contradict factual knowledge or the source text. This study explores methods for detecting hallucinations in three SemEval-2024 Task 6 tasks: Machine Translation, Definition Modeling, and Paraphrase Generation. We evaluate two methods: semantic similarity between the generated text and factual references, and an ensemble of language models that judge each other's outputs. Our results show that semantic similarity achieves moderate accuracy and correlation scores in trial data, while the ensemble method offers insights into the complexities of hallucination detection but falls short of expectations. This work highlights the challenges of hallucination detection and underscores the need for further research in this critical area.
Imaginations of WALL-E : Reconstructing Experiences with an Imagination-Inspired Module for Advanced AI Systems
Aug 20, 2023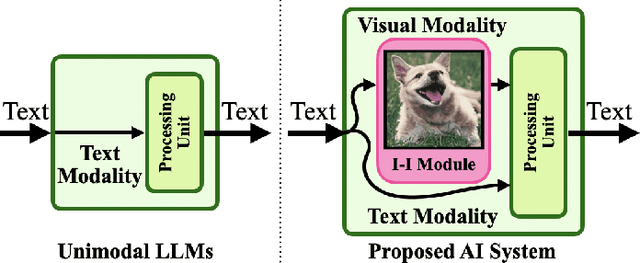



In this paper, we introduce a novel Artificial Intelligence (AI) system inspired by the philosophical and psychoanalytical concept of imagination as a ``Re-construction of Experiences". Our AI system is equipped with an imagination-inspired module that bridges the gap between textual inputs and other modalities, enriching the derived information based on previously learned experiences. A unique feature of our system is its ability to formulate independent perceptions of inputs. This leads to unique interpretations of a concept that may differ from human interpretations but are equally valid, a phenomenon we term as ``Interpretable Misunderstanding". We employ large-scale models, specifically a Multimodal Large Language Model (MLLM), enabling our proposed system to extract meaningful information across modalities while primarily remaining unimodal. We evaluated our system against other large language models across multiple tasks, including emotion recognition and question-answering, using a zero-shot methodology to ensure an unbiased scenario that may happen by fine-tuning. Significantly, our system outperformed the best Large Language Models (LLM) on the MELD, IEMOCAP, and CoQA datasets, achieving Weighted F1 (WF1) scores of 46.74%, 25.23%, and Overall F1 (OF1) score of 17%, respectively, compared to 22.89%, 12.28%, and 7% from the well-performing LLM. The goal is to go beyond the statistical view of language processing and tie it to human concepts such as philosophy and psychoanalysis. This work represents a significant advancement in the development of imagination-inspired AI systems, opening new possibilities for AI to generate deep and interpretable information across modalities, thereby enhancing human-AI interaction.
naab: A ready-to-use plug-and-play corpus for Farsi
Aug 29, 2022



Huge corpora of textual data are always known to be a crucial need for training deep models such as transformer-based ones. This issue is emerging more in lower resource languages - like Farsi. We propose naab, the biggest cleaned and ready-to-use open-source textual corpus in Farsi. It contains about 130GB of data, 250 million paragraphs, and 15 billion words. The project name is derived from the Farsi word NAAB K which means pure and high grade. We also provide the raw version of the corpus called naab-raw and an easy-to-use preprocessor that can be employed by those who wanted to make a customized corpus.