 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstraction as a Memory-Efficient Inductive Bias for Continual Learning
Mar 17, 2026The real world is non-stationary and infinitely complex, requiring intelligent agents to learn continually without the prohibitive cost of retraining from scratch. While online continual learning offers a framework for this setting, learning new information often interferes with previously acquired knowledge, causes forgetting and degraded generalization. To address this, we propose Abstraction-Augmented Training (AAT), a loss-level modification encouraging models to capture the latent relational structure shared across examples. By jointly optimizing over concrete instances and their abstract representations, AAT introduces a memory-efficient inductive bias that stabilizes learning in strictly online data streams, eliminating the need for a replay buffer. To capture the multi-faceted nature of abstraction, we introduce and evaluate AAT on two benchmarks: a controlled relational dataset where abstraction is realized through entity masking, and a narrative dataset where abstraction is expressed through shared proverbs. Our results show that AAT achieves performance comparable to or exceeding strong experience replay (ER) baselines, despite requiring zero additional memory and only minimal changes to the training objective. This work highlights structural abstraction as a powerful, memory-free alternative to ER.
The Subjectivity of Respect in Police Traffic Stops: Modeling Community Perspectives in Body-Worn Camera Footage
Feb 10, 2026Traffic stops are among the most frequent police-civilian interactions, and body-worn cameras (BWCs) provide a unique record of how these encounters unfold. Respect is a central dimension of these interactions, shaping public trust and perceived legitimacy, yet its interpretation is inherently subjective and shaped by lived experience, rendering community-specific perspectives a critical consideration. Leveraging unprecedented access to Los Angeles Police Department BWC footage, we introduce the first large-scale traffic-stop dataset annotated with respect ratings and free-text rationales from multiple perspectives. By sampling annotators from police-affiliated, justice-system-impacted, and non-affiliated Los Angeles residents, we enable the systematic study of perceptual differences across diverse communities. To this end, we (i) develop a domain-specific evaluation rubric grounded in procedural justice theory, LAPD training materials, and extensive fieldwork; (ii) introduce a rubric-driven preference data construction framework for perspective-consistent alignment; and (iii) propose a perspective-aware modeling framework that predicts personalized respect ratings and generates annotator-specific rationales for both officers and civilian drivers from traffic-stop transcripts. Across all three annotator groups, our approach improves both rating prediction performance and rationale alignment. Our perspective-aware framework enables law enforcement to better understand diverse community expectations, providing a vital tool for building public trust and procedural legitimacy.
Flip-Flop Consistency: Unsupervised Training for Robustness to Prompt Perturbations in LLMs
Oct 16, 2025
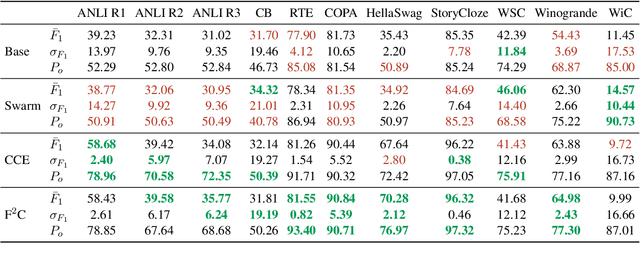


Large Language Models (LLMs) often produce inconsistent answers when faced with different phrasings of the same prompt. In this paper, we propose Flip-Flop Consistency ($F^2C$), an unsupervised training method that improves robustness to such perturbations. $F^2C$ is composed of two key components. The first, Consensus Cross-Entropy (CCE), uses a majority vote across prompt variations to create a hard pseudo-label. The second is a representation alignment loss that pulls lower-confidence and non-majority predictors toward the consensus established by high-confidence, majority-voting variations. We evaluate our method on 11 datasets spanning four NLP tasks, with 4-15 prompt variations per dataset. On average, $F^2C$ raises observed agreement by 11.62%, improves mean $F_1$ by 8.94%, and reduces performance variance across formats by 3.29%. In out-of-domain evaluations, $F^2C$ generalizes effectively, increasing $\overline{F_1}$ and agreement while decreasing variance across most source-target pairs. Finally, when trained on only a subset of prompt perturbations and evaluated on held-out formats, $F^2C$ consistently improves both performance and agreement while reducing variance. These findings highlight $F^2C$ as an effective unsupervised method for enhancing LLM consistency, performance, and generalization under prompt perturbations. Code is available at https://github.com/ParsaHejabi/Flip-Flop-Consistency-Unsupervised-Training-for-Robustness-to-Prompt-Perturbations-in-LLMs.
CoCo-CoLa: Evaluating Language Adherence in Multilingual LLMs
Feb 18, 2025Multilingual Large Language Models (LLMs) develop cross-lingual abilities despite being trained on limited parallel data. However, they often struggle to generate responses in the intended language, favoring high-resource languages such as English. In this work, we introduce CoCo-CoLa (Correct Concept - Correct Language), a novel metric to evaluate language adherence in multilingual LLMs. Using fine-tuning experiments on a closed-book QA task across seven languages, we analyze how training in one language affects others' performance. Our findings reveal that multilingual models share task knowledge across languages but exhibit biases in the selection of output language. We identify language-specific layers, showing that final layers play a crucial role in determining output language. Accordingly, we propose a partial training strategy that selectively fine-tunes key layers, improving language adherence while significantly reducing computational cost. Our method achieves comparable or superior performance to full fine-tuning, particularly for low-resource languages, offering a more efficient multilingual adaptation.
Evaluating Creativity and Deception in Large Language Models: A Simulation Framework for Multi-Agent Balderdash
Nov 15, 2024
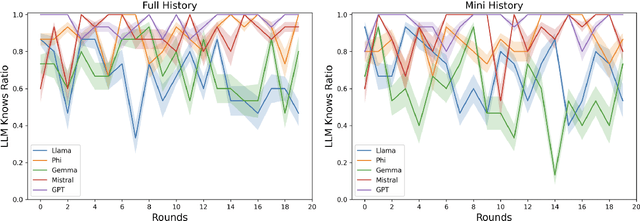
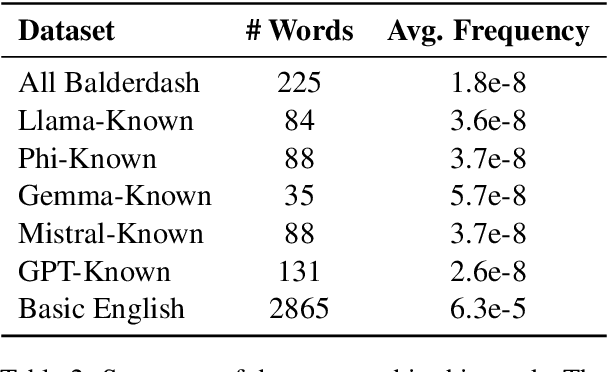

Large Language Models (LLMs) have shown impressive capabilities in complex tasks and interactive environments, yet their creativity remains underexplored. This paper introduces a simulation framework utilizing the game Balderdash to evaluate both the creativity and logical reasoning of LLMs. In Balderdash, players generate fictitious definitions for obscure terms to deceive others while identifying correct definitions. Our framework enables multiple LLM agents to participate in this game, assessing their ability to produce plausible definitions and strategize based on game rules and history. We implemented a centralized game engine featuring various LLMs as participants and a judge LLM to evaluate semantic equivalence. Through a series of experiments, we analyzed the performance of different LLMs, examining metrics such as True Definition Ratio, Deception Ratio, and Correct Guess Ratio. The results provide insights into the creative and deceptive capabilities of LLMs, highlighting their strengths and areas for improvement. Specifically, the study reveals that infrequent vocabulary in LLMs' input leads to poor reasoning on game rules and historical context (https://github.com/ParsaHejabi/Simulation-Framework-for-Multi-Agent-Balderdash).
naab: A ready-to-use plug-and-play corpus for Farsi
Aug 29, 2022



Huge corpora of textual data are always known to be a crucial need for training deep models such as transformer-based ones. This issue is emerging more in lower resource languages - like Farsi. We propose naab, the biggest cleaned and ready-to-use open-source textual corpus in Farsi. It contains about 130GB of data, 250 million paragraphs, and 15 billion words. The project name is derived from the Farsi word NAAB K which means pure and high grade. We also provide the raw version of the corpus called naab-raw and an easy-to-use preprocessor that can be employed by those who wanted to make a customized corpus.