 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlip-Flop Consistency: Unsupervised Training for Robustness to Prompt Perturbations in LLMs
Oct 16, 2025Large Language Models (LLMs) often produce inconsistent answers when faced with different phrasings of the same prompt. In this paper, we propose Flip-Flop Consistency ($F^2C$), an unsupervised training method that improves robustness to such perturbations. $F^2C$ is composed of two key components. The first, Consensus Cross-Entropy (CCE), uses a majority vote across prompt variations to create a hard pseudo-label. The second is a representation alignment loss that pulls lower-confidence and non-majority predictors toward the consensus established by high-confidence, majority-voting variations. We evaluate our method on 11 datasets spanning four NLP tasks, with 4-15 prompt variations per dataset. On average, $F^2C$ raises observed agreement by 11.62%, improves mean $F_1$ by 8.94%, and reduces performance variance across formats by 3.29%. In out-of-domain evaluations, $F^2C$ generalizes effectively, increasing $\overline{F_1}$ and agreement while decreasing variance across most source-target pairs. Finally, when trained on only a subset of prompt perturbations and evaluated on held-out formats, $F^2C$ consistently improves both performance and agreement while reducing variance. These findings highlight $F^2C$ as an effective unsupervised method for enhancing LLM consistency, performance, and generalization under prompt perturbations. Code is available at https://github.com/ParsaHejabi/Flip-Flop-Consistency-Unsupervised-Training-for-Robustness-to-Prompt-Perturbations-in-LLMs.
Evaluating Creativity and Deception in Large Language Models: A Simulation Framework for Multi-Agent Balderdash
Nov 15, 2024
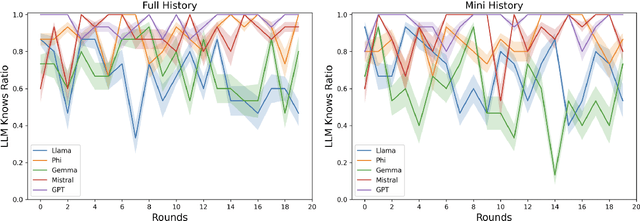
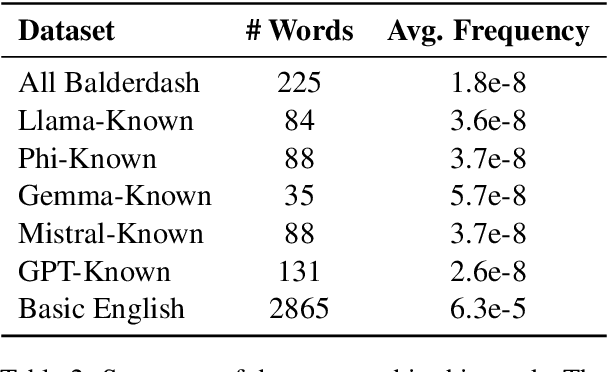

Large Language Models (LLMs) have shown impressive capabilities in complex tasks and interactive environments, yet their creativity remains underexplored. This paper introduces a simulation framework utilizing the game Balderdash to evaluate both the creativity and logical reasoning of LLMs. In Balderdash, players generate fictitious definitions for obscure terms to deceive others while identifying correct definitions. Our framework enables multiple LLM agents to participate in this game, assessing their ability to produce plausible definitions and strategize based on game rules and history. We implemented a centralized game engine featuring various LLMs as participants and a judge LLM to evaluate semantic equivalence. Through a series of experiments, we analyzed the performance of different LLMs, examining metrics such as True Definition Ratio, Deception Ratio, and Correct Guess Ratio. The results provide insights into the creative and deceptive capabilities of LLMs, highlighting their strengths and areas for improvement. Specifically, the study reveals that infrequent vocabulary in LLMs' input leads to poor reasoning on game rules and historical context (https://github.com/ParsaHejabi/Simulation-Framework-for-Multi-Agent-Balderdash).
A Multi-Perspective Machine Learning Approach to Evaluate Police-Driver Interaction in Los Angeles
Feb 08, 2024Interactions between the government officials and civilians affect public wellbeing and the state legitimacy that is necessary for the functioning of democratic society. Police officers, the most visible and contacted agents of the state, interact with the public more than 20 million times a year during traffic stops. Today, these interactions are regularly recorded by body-worn cameras (BWCs), which are lauded as a means to enhance police accountability and improve police-public interactions. However, the timely analysis of these recordings is hampered by a lack of reliable automated tools that can enable the analysis of these complex and contested police-public interactions. This article proposes an approach to developing new multi-perspective, multimodal machine learning (ML) tools to analyze the audio, video, and transcript information from this BWC footage. Our approach begins by identifying the aspects of communication most salient to different stakeholders, including both community members and police officers. We move away from modeling approaches built around the existence of a single ground truth and instead utilize new advances in soft labeling to incorporate variation in how different observers perceive the same interactions. We argue that this inclusive approach to the conceptualization and design of new ML tools is broadly applicable to the study of communication and development of analytic tools across domains of human interaction, including education, medicine, and the workplace.