 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Perspective Machine Learning Approach to Evaluate Police-Driver Interaction in Los Angeles
Feb 08, 2024Interactions between the government officials and civilians affect public wellbeing and the state legitimacy that is necessary for the functioning of democratic society. Police officers, the most visible and contacted agents of the state, interact with the public more than 20 million times a year during traffic stops. Today, these interactions are regularly recorded by body-worn cameras (BWCs), which are lauded as a means to enhance police accountability and improve police-public interactions. However, the timely analysis of these recordings is hampered by a lack of reliable automated tools that can enable the analysis of these complex and contested police-public interactions. This article proposes an approach to developing new multi-perspective, multimodal machine learning (ML) tools to analyze the audio, video, and transcript information from this BWC footage. Our approach begins by identifying the aspects of communication most salient to different stakeholders, including both community members and police officers. We move away from modeling approaches built around the existence of a single ground truth and instead utilize new advances in soft labeling to incorporate variation in how different observers perceive the same interactions. We argue that this inclusive approach to the conceptualization and design of new ML tools is broadly applicable to the study of communication and development of analytic tools across domains of human interaction, including education, medicine, and the workplace.
MM-AU:Towards Multimodal Understanding of Advertisement Videos
Aug 27, 2023Advertisement videos (ads) play an integral part in the domain of Internet e-commerce as they amplify the reach of particular products to a broad audience or can serve as a medium to raise awareness about specific issues through concise narrative structures. The narrative structures of advertisements involve several elements like reasoning about the broad content (topic and the underlying message) and examining fine-grained details involving the transition of perceived tone due to the specific sequence of events and interaction among characters. In this work, to facilitate the understanding of advertisements along the three important dimensions of topic categorization, perceived tone transition, and social message detection, we introduce a multimodal multilingual benchmark called MM-AU composed of over 8.4K videos (147 hours) curated from multiple web sources. We explore multiple zero-shot reasoning baselines through the application of large language models on the ads transcripts. Further, we demonstrate that leveraging signals from multiple modalities, including audio, video, and text, in multimodal transformer-based supervised models leads to improved performance compared to unimodal approaches.
Robust Self Supervised Speech Embeddings for Child-Adult Classification in Interactions involving Children with Autism
Jul 31, 2023We address the problem of detecting who spoke when in child-inclusive spoken interactions i.e., automatic child-adult speaker classification. Interactions involving children are richly heterogeneous due to developmental differences. The presence of neurodiversity e.g., due to Autism, contributes additional variability. We investigate the impact of additional pre-training with more unlabelled child speech on the child-adult classification performance. We pre-train our model with child-inclusive interactions, following two recent self-supervision algorithms, Wav2vec 2.0 and WavLM, with a contrastive loss objective. We report 9 - 13% relative improvement over the state-of-the-art baseline with regards to classification F1 scores on two clinical interaction datasets involving children with Autism. We also analyze the impact of pre-training under different conditions by evaluating our model on interactions involving different subgroups of children based on various demographic factors.
FedMultimodal: A Benchmark For Multimodal Federated Learning
Jun 20, 2023Over the past few years, Federated Learning (FL) has become an emerging machine learning technique to tackle data privacy challenges through collaborative training. In the Federated Learning algorithm, the clients submit a locally trained model, and the server aggregates these parameters until convergence. Despite significant efforts that have been made to FL in fields like computer vision, audio, and natural language processing, the FL applications utilizing multimodal data streams remain largely unexplored. It is known that multimodal learning has broad real-world applications in emotion recognition, healthcare, multimedia, and social media, while user privacy persists as a critical concern. Specifically, there are no existing FL benchmarks targeting multimodal applications or related tasks. In order to facilitate the research in multimodal FL, we introduce FedMultimodal, the first FL benchmark for multimodal learning covering five representative multimodal applications from ten commonly used datasets with a total of eight unique modalities. FedMultimodal offers a systematic FL pipeline, enabling end-to-end modeling framework ranging from data partition and feature extraction to FL benchmark algorithms and model evaluation. Unlike existing FL benchmarks, FedMultimodal provides a standardized approach to assess the robustness of FL against three common data corruptions in real-life multimodal applications: missing modalities, missing labels, and erroneous labels. We hope that FedMultimodal can accelerate numerous future research directions, including designing multimodal FL algorithms toward extreme data heterogeneity, robustness multimodal FL, and efficient multimodal FL. The datasets and benchmark results can be accessed at: https://github.com/usc-sail/fed-multimodal.
Understanding Spoken Language Development of Children with ASD Using Pre-trained Speech Embeddings
May 23, 2023Speech processing techniques are useful for analyzing speech and language development in children with Autism Spectrum Disorder (ASD), who are often varied and delayed in acquiring these skills. Early identification and intervention are crucial, but traditional assessment methodologies such as caregiver reports are not adequate for the requisite behavioral phenotyping. Natural Language Sample (NLS) analysis has gained attention as a promising complement. Researchers have developed benchmarks for spoken language capabilities in children with ASD, obtainable through the analysis of NLS. This paper proposes applications of speech processing technologies in support of automated assessment of children's spoken language development by classification between child and adult speech and between speech and nonverbal vocalization in NLS, with respective F1 macro scores of 82.6% and 67.8%, underscoring the potential for accurate and scalable tools for ASD research and clinical use.
TrustSER: On the Trustworthiness of Fine-tuning Pre-trained Speech Embeddings For Speech Emotion Recognition
May 18, 2023Recent studies have explored the use of pre-trained embeddings for speech emotion recognition (SER), achieving comparable performance to conventional methods that rely on low-level knowledge-inspired acoustic features. These embeddings are often generated from models trained on large-scale speech datasets using self-supervised or weakly-supervised learning objectives. Despite the significant advancements made in SER through the use of pre-trained embeddings, there is a limited understanding of the trustworthiness of these methods, including privacy breaches, unfair performance, vulnerability to adversarial attacks, and computational cost, all of which may hinder the real-world deployment of these systems. In response, we introduce TrustSER, a general framework designed to evaluate the trustworthiness of SER systems using deep learning methods, with a focus on privacy, safety, fairness, and sustainability, offering unique insights into future research in the field of SER. Our code is publicly available under: https://github.com/usc-sail/trust-ser.
Contextually-rich human affect perception using multimodal scene information
Mar 13, 2023
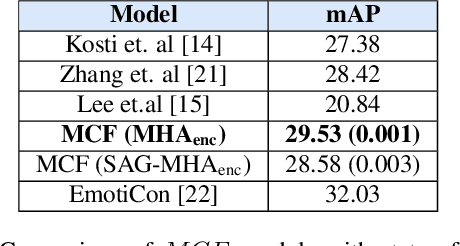
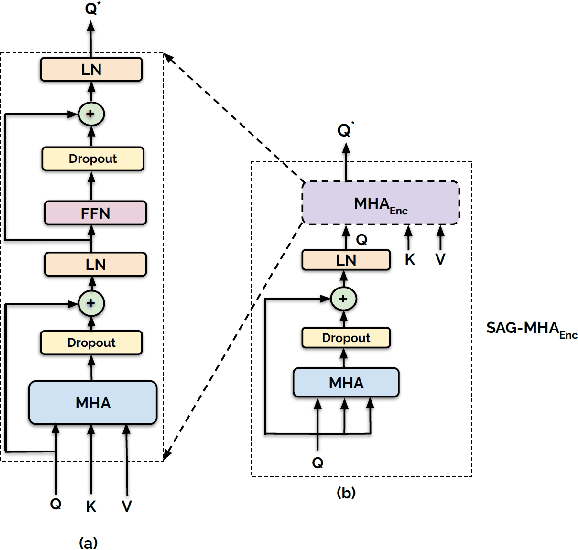
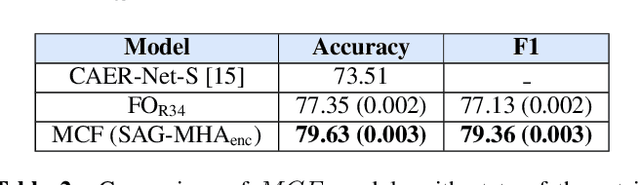
The process of human affect understanding involves the ability to infer person specific emotional states from various sources including images, speech, and language. Affect perception from images has predominantly focused on expressions extracted from salient face crops. However, emotions perceived by humans rely on multiple contextual cues including social settings, foreground interactions, and ambient visual scenes. In this work, we leverage pretrained vision-language (VLN) models to extract descriptions of foreground context from images. Further, we propose a multimodal context fusion (MCF) module to combine foreground cues with the visual scene and person-based contextual information for emotion prediction. We show the effectiveness of our proposed modular design on two datasets associated with natural scenes and TV shows.
A dataset for Audio-Visual Sound Event Detection in Movies
Feb 14, 2023

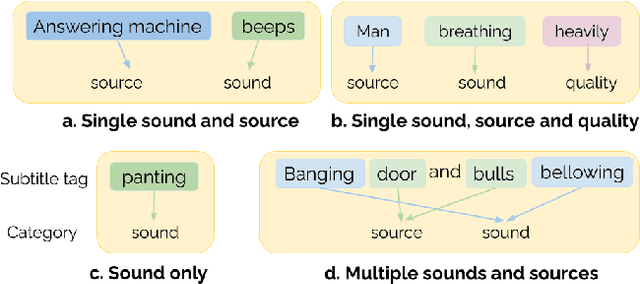

Audio event detection is a widely studied audio processing task, with applications ranging from self-driving cars to healthcare. In-the-wild datasets such as Audioset have propelled research in this field. However, many efforts typically involve manual annotation and verification, which is expensive to perform at scale. Movies depict various real-life and fictional scenarios which makes them a rich resource for mining a wide-range of audio events. In this work, we present a dataset of audio events called Subtitle-Aligned Movie Sounds (SAM-S). We use publicly-available closed-caption transcripts to automatically mine over 110K audio events from 430 movies. We identify three dimensions to categorize audio events: sound, source, quality, and present the steps involved to produce a final taxonomy of 245 sounds. We discuss the choices involved in generating the taxonomy, and also highlight the human-centered nature of sounds in our dataset. We establish a baseline performance for audio-only sound classification of 34.76% mean average precision and show that incorporating visual information can further improve the performance by about 5%. Data and code are made available for research at https://github.com/usc-sail/mica-subtitle-aligned-movie-sounds
A Review of Speech-centric Trustworthy Machine Learning: Privacy, Safety, and Fairness
Dec 18, 2022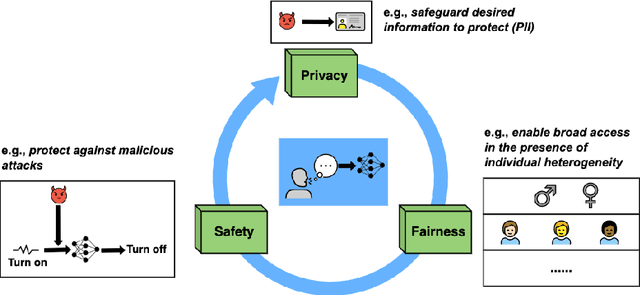
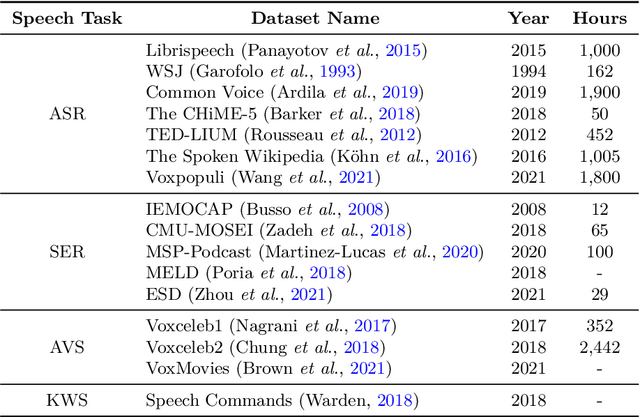
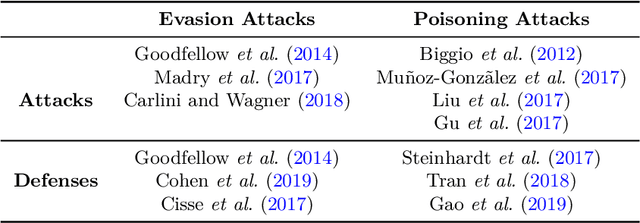
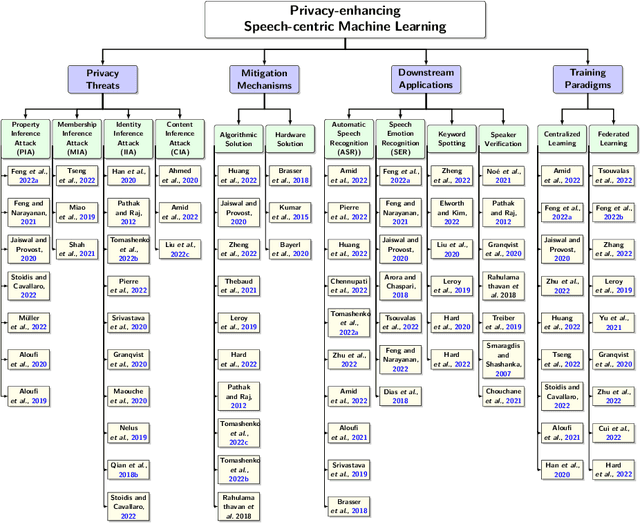
Speech-centric machine learning systems have revolutionized many leading domains ranging from transportation and healthcare to education and defense, profoundly changing how people live, work, and interact with each other. However, recent studies have demonstrated that many speech-centric ML systems may need to be considered more trustworthy for broader deployment. Specifically, concerns over privacy breaches, discriminating performance, and vulnerability to adversarial attacks have all been discovered in ML research fields. In order to address the above challenges and risks, a significant number of efforts have been made to ensure these ML systems are trustworthy, especially private, safe, and fair. In this paper, we conduct the first comprehensive survey on speech-centric trustworthy ML topics related to privacy, safety, and fairness. In addition to serving as a summary report for the research community, we point out several promising future research directions to inspire the researchers who wish to explore further in this area.
Attribute Inference Attack of Speech Emotion Recognition in Federated Learning Settings
Dec 26, 2021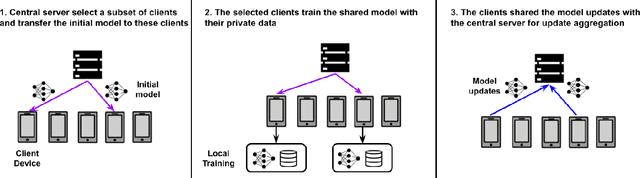
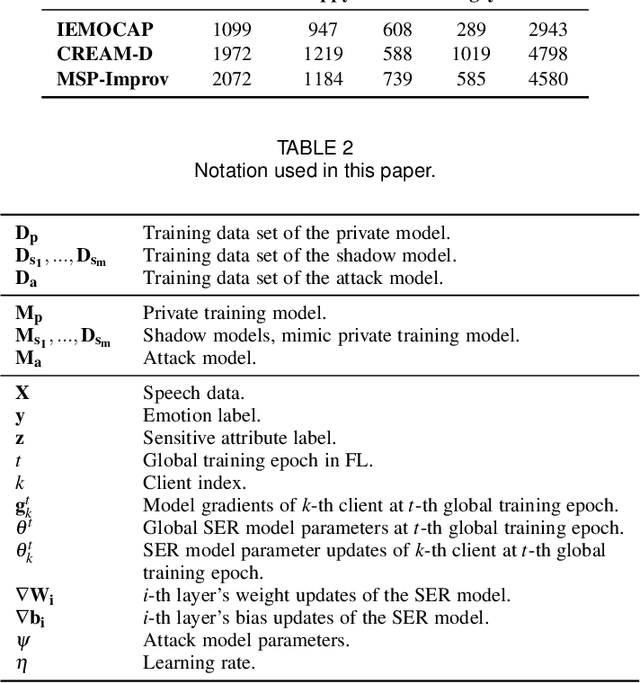
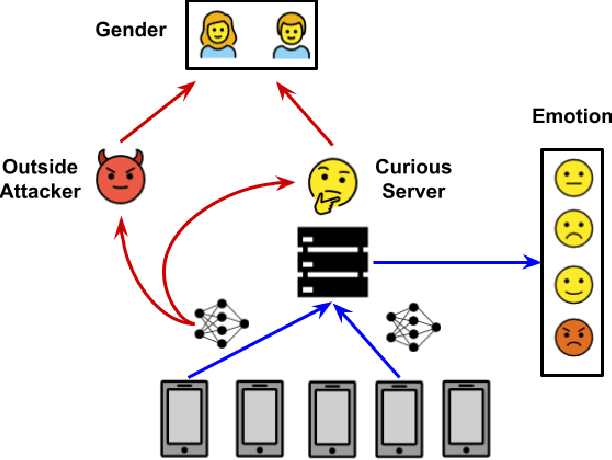
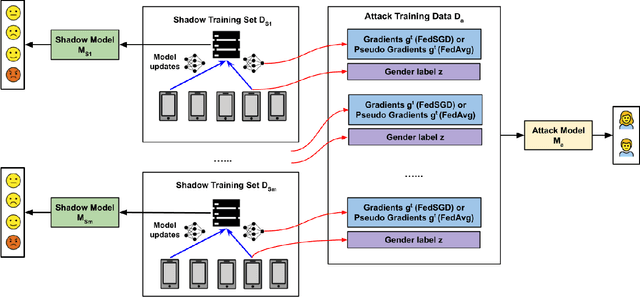
Speech emotion recognition (SER) processes speech signals to detect and characterize expressed perceived emotions. Many SER application systems often acquire and transmit speech data collected at the client-side to remote cloud platforms for inference and decision making. However, speech data carry rich information not only about emotions conveyed in vocal expressions, but also other sensitive demographic traits such as gender, age and language background. Consequently, it is desirable for SER systems to have the ability to classify emotion constructs while preventing unintended/improper inferences of sensitive and demographic information. Federated learning (FL) is a distributed machine learning paradigm that coordinates clients to train a model collaboratively without sharing their local data. This training approach appears secure and can improve privacy for SER. However, recent works have demonstrated that FL approaches are still vulnerable to various privacy attacks like reconstruction attacks and membership inference attacks. Although most of these have focused on computer vision applications, such information leakages exist in the SER systems trained using the FL technique. To assess the information leakage of SER systems trained using FL, we propose an attribute inference attack framework that infers sensitive attribute information of the clients from shared gradients or model parameters, corresponding to the FedSGD and the FedAvg training algorithms, respectively. As a use case, we empirically evaluate our approach for predicting the client's gender information using three SER benchmark datasets: IEMOCAP, CREMA-D, and MSP-Improv. We show that the attribute inference attack is achievable for SER systems trained using FL. We further identify that most information leakage possibly comes from the first layer in the SER model.