 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA dataset for Audio-Visual Sound Event Detection in Movies
Paper and Code


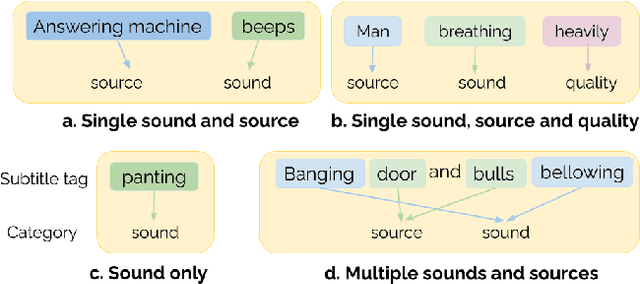

Audio event detection is a widely studied audio processing task, with applications ranging from self-driving cars to healthcare. In-the-wild datasets such as Audioset have propelled research in this field. However, many efforts typically involve manual annotation and verification, which is expensive to perform at scale. Movies depict various real-life and fictional scenarios which makes them a rich resource for mining a wide-range of audio events. In this work, we present a dataset of audio events called Subtitle-Aligned Movie Sounds (SAM-S). We use publicly-available closed-caption transcripts to automatically mine over 110K audio events from 430 movies. We identify three dimensions to categorize audio events: sound, source, quality, and present the steps involved to produce a final taxonomy of 245 sounds. We discuss the choices involved in generating the taxonomy, and also highlight the human-centered nature of sounds in our dataset. We establish a baseline performance for audio-only sound classification of 34.76% mean average precision and show that incorporating visual information can further improve the performance by about 5%. Data and code are made available for research at https://github.com/usc-sail/mica-subtitle-aligned-movie-sounds