 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Text-to-image Model Assist Multi-modal Learning for Visual Recognition with Visual Modality Missing?
Feb 14, 2024Multi-modal learning has emerged as an increasingly promising avenue in vision recognition, driving innovations across diverse domains ranging from media and education to healthcare and transportation. Despite its success, the robustness of multi-modal learning for visual recognition is often challenged by the unavailability of a subset of modalities, especially the visual modality. Conventional approaches to mitigate missing modalities in multi-modal learning rely heavily on algorithms and modality fusion schemes. In contrast, this paper explores the use of text-to-image models to assist multi-modal learning. Specifically, we propose a simple but effective multi-modal learning framework GTI-MM to enhance the data efficiency and model robustness against missing visual modality by imputing the missing data with generative transformers. Using multiple multi-modal datasets with visual recognition tasks, we present a comprehensive analysis of diverse conditions involving missing visual modality in data, including model training. Our findings reveal that synthetic images benefit training data efficiency with visual data missing in training and improve model robustness with visual data missing involving training and testing. Moreover, we demonstrate GTI-MM is effective with lower generation quantity and simple prompt techniques.
Does Video Summarization Require Videos? Quantifying the Effectiveness of Language in Video Summarization
Sep 18, 2023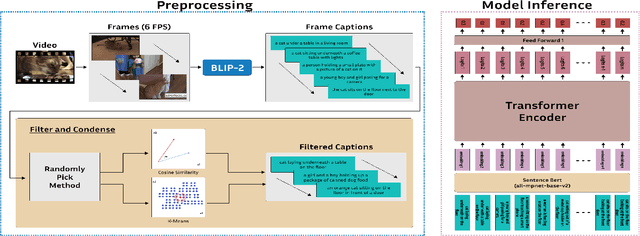
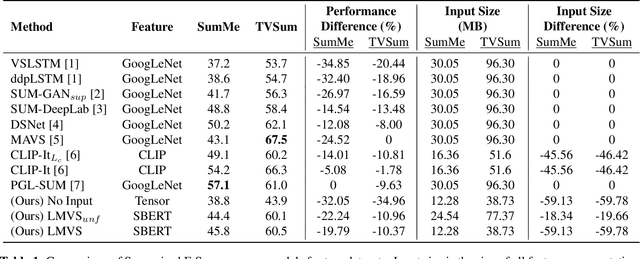

Video summarization remains a huge challenge in computer vision due to the size of the input videos to be summarized. We propose an efficient, language-only video summarizer that achieves competitive accuracy with high data efficiency. Using only textual captions obtained via a zero-shot approach, we train a language transformer model and forego image representations. This method allows us to perform filtration amongst the representative text vectors and condense the sequence. With our approach, we gain explainability with natural language that comes easily for human interpretation and textual summaries of the videos. An ablation study that focuses on modality and data compression shows that leveraging text modality only effectively reduces input data processing while retaining comparable results.
MM-AU:Towards Multimodal Understanding of Advertisement Videos
Aug 27, 2023Advertisement videos (ads) play an integral part in the domain of Internet e-commerce as they amplify the reach of particular products to a broad audience or can serve as a medium to raise awareness about specific issues through concise narrative structures. The narrative structures of advertisements involve several elements like reasoning about the broad content (topic and the underlying message) and examining fine-grained details involving the transition of perceived tone due to the specific sequence of events and interaction among characters. In this work, to facilitate the understanding of advertisements along the three important dimensions of topic categorization, perceived tone transition, and social message detection, we introduce a multimodal multilingual benchmark called MM-AU composed of over 8.4K videos (147 hours) curated from multiple web sources. We explore multiple zero-shot reasoning baselines through the application of large language models on the ads transcripts. Further, we demonstrate that leveraging signals from multiple modalities, including audio, video, and text, in multimodal transformer-based supervised models leads to improved performance compared to unimodal approaches.
FedMultimodal: A Benchmark For Multimodal Federated Learning
Jun 20, 2023Over the past few years, Federated Learning (FL) has become an emerging machine learning technique to tackle data privacy challenges through collaborative training. In the Federated Learning algorithm, the clients submit a locally trained model, and the server aggregates these parameters until convergence. Despite significant efforts that have been made to FL in fields like computer vision, audio, and natural language processing, the FL applications utilizing multimodal data streams remain largely unexplored. It is known that multimodal learning has broad real-world applications in emotion recognition, healthcare, multimedia, and social media, while user privacy persists as a critical concern. Specifically, there are no existing FL benchmarks targeting multimodal applications or related tasks. In order to facilitate the research in multimodal FL, we introduce FedMultimodal, the first FL benchmark for multimodal learning covering five representative multimodal applications from ten commonly used datasets with a total of eight unique modalities. FedMultimodal offers a systematic FL pipeline, enabling end-to-end modeling framework ranging from data partition and feature extraction to FL benchmark algorithms and model evaluation. Unlike existing FL benchmarks, FedMultimodal provides a standardized approach to assess the robustness of FL against three common data corruptions in real-life multimodal applications: missing modalities, missing labels, and erroneous labels. We hope that FedMultimodal can accelerate numerous future research directions, including designing multimodal FL algorithms toward extreme data heterogeneity, robustness multimodal FL, and efficient multimodal FL. The datasets and benchmark results can be accessed at: https://github.com/usc-sail/fed-multimodal.
Unlocking Foundation Models for Privacy-Enhancing Speech Understanding: An Early Study on Low Resource Speech Training Leveraging Label-guided Synthetic Speech Content
Jun 13, 2023Automatic Speech Understanding (ASU) leverages the power of deep learning models for accurate interpretation of human speech, leading to a wide range of speech applications that enrich the human experience. However, training a robust ASU model requires the curation of a large number of speech samples, creating risks for privacy breaches. In this work, we investigate using foundation models to assist privacy-enhancing speech computing. Unlike conventional works focusing primarily on data perturbation or distributed algorithms, our work studies the possibilities of using pre-trained generative models to synthesize speech content as training data with just label guidance. We show that zero-shot learning with training label-guided synthetic speech content remains a challenging task. On the other hand, our results demonstrate that the model trained with synthetic speech samples provides an effective initialization point for low-resource ASU training. This result reveals the potential to enhance privacy by reducing user data collection but using label-guided synthetic speech content.
Signal Processing Grand Challenge 2023 -- e-Prevention: Sleep Behavior as an Indicator of Relapses in Psychotic Patients
Apr 17, 2023
This paper presents the approach and results of USC SAIL's submission to the Signal Processing Grand Challenge 2023 - e-Prevention (Task 2), on detecting relapses in psychotic patients. Relapse prediction has proven to be challenging, primarily due to the heterogeneity of symptoms and responses to treatment between individuals. We address these challenges by investigating the use of sleep behavior features to estimate relapse days as outliers in an unsupervised machine learning setting. We extract informative features from human activity and heart rate data collected in the wild, and evaluate various combinations of feature types and time resolutions. We found that short-time sleep behavior features outperformed their awake counterparts and larger time intervals. Our submission was ranked 3rd in the Task's official leaderboard, demonstrating the potential of such features as an objective and non-invasive predictor of psychotic relapses.
Contextually-rich human affect perception using multimodal scene information
Mar 13, 2023
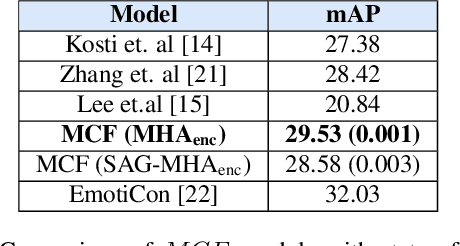
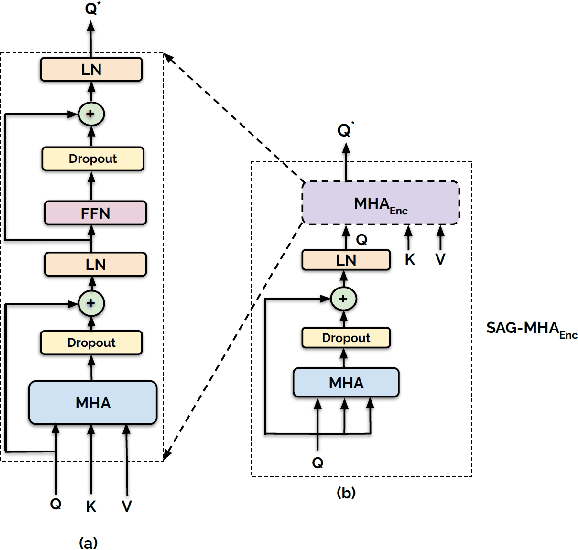
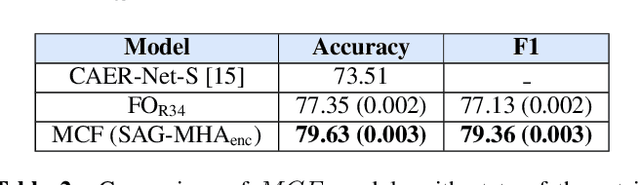
The process of human affect understanding involves the ability to infer person specific emotional states from various sources including images, speech, and language. Affect perception from images has predominantly focused on expressions extracted from salient face crops. However, emotions perceived by humans rely on multiple contextual cues including social settings, foreground interactions, and ambient visual scenes. In this work, we leverage pretrained vision-language (VLN) models to extract descriptions of foreground context from images. Further, we propose a multimodal context fusion (MCF) module to combine foreground cues with the visual scene and person-based contextual information for emotion prediction. We show the effectiveness of our proposed modular design on two datasets associated with natural scenes and TV shows.
A dataset for Audio-Visual Sound Event Detection in Movies
Feb 14, 2023

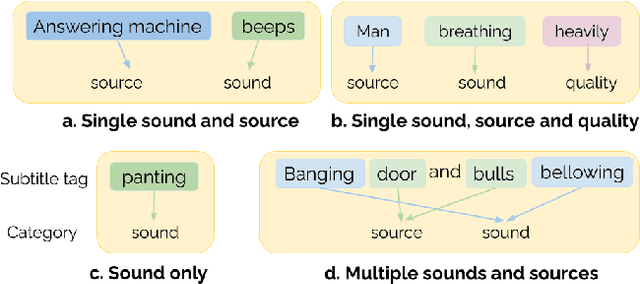

Audio event detection is a widely studied audio processing task, with applications ranging from self-driving cars to healthcare. In-the-wild datasets such as Audioset have propelled research in this field. However, many efforts typically involve manual annotation and verification, which is expensive to perform at scale. Movies depict various real-life and fictional scenarios which makes them a rich resource for mining a wide-range of audio events. In this work, we present a dataset of audio events called Subtitle-Aligned Movie Sounds (SAM-S). We use publicly-available closed-caption transcripts to automatically mine over 110K audio events from 430 movies. We identify three dimensions to categorize audio events: sound, source, quality, and present the steps involved to produce a final taxonomy of 245 sounds. We discuss the choices involved in generating the taxonomy, and also highlight the human-centered nature of sounds in our dataset. We establish a baseline performance for audio-only sound classification of 34.76% mean average precision and show that incorporating visual information can further improve the performance by about 5%. Data and code are made available for research at https://github.com/usc-sail/mica-subtitle-aligned-movie-sounds
Multimodal Estimation of Change Points of Physiological Arousal in Drivers
Oct 28, 2022Detecting unsafe driving states, such as stress, drowsiness, and fatigue, is an important component of ensuring driving safety and an essential prerequisite for automatic intervention systems in vehicles. These concerning conditions are primarily connected to the driver's low or high arousal levels. In this study, we describe a framework for processing multimodal physiological time-series from wearable sensors during driving and locating points of prominent change in drivers' physiological arousal state. These points of change could potentially indicate events that require just-in-time intervention. We apply time-series segmentation on heart rate and breathing rate measurements and quantify their robustness in capturing change points in electrodermal activity, treated as a reference index for arousal, as well as on self-reported stress ratings, using three public datasets. Our experiments demonstrate that physiological measures are veritable indicators of change points of arousal and perform robustly across an extensive ablation study.
Understanding of Emotion Perception from Art
Oct 13, 2021
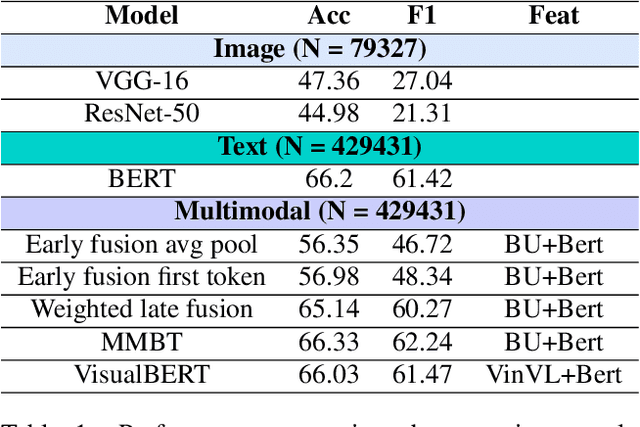

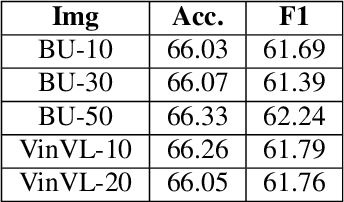
Computational modeling of the emotions evoked by art in humans is a challenging problem because of the subjective and nuanced nature of art and affective signals. In this paper, we consider the above-mentioned problem of understanding emotions evoked in viewers by artwork using both text and visual modalities. Specifically, we analyze images and the accompanying text captions from the viewers expressing emotions as a multimodal classification task. Our results show that single-stream multimodal transformer-based models like MMBT and VisualBERT perform better compared to both image-only models and dual-stream multimodal models having separate pathways for text and image modalities. We also observe improvements in performance for extreme positive and negative emotion classes, when a single-stream model like MMBT is compared with a text-only transformer model like BERT.