 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSufficient Conditions for Stability of Minimum-Norm Interpolating Deep ReLU Networks
Feb 14, 2026Algorithmic stability is a classical framework for analyzing the generalization error of learning algorithms. It predicts that an algorithm has small generalization error if it is insensitive to small perturbations in the training set such as the removal or replacement of a training point. While stability has been demonstrated for numerous well-known algorithms, this framework has had limited success in analyses of deep neural networks. In this paper we study the algorithmic stability of deep ReLU homogeneous neural networks that achieve zero training error using parameters with the smallest $L_2$ norm, also known as the minimum-norm interpolation, a phenomenon that can be observed in overparameterized models trained by gradient-based algorithms. We investigate sufficient conditions for such networks to be stable. We find that 1) such networks are stable when they contain a (possibly small) stable sub-network, followed by a layer with a low-rank weight matrix, and 2) such networks are not guaranteed to be stable even when they contain a stable sub-network, if the following layer is not low-rank. The low-rank assumption is inspired by recent empirical and theoretical results which demonstrate that training deep neural networks is biased towards low-rank weight matrices, for minimum-norm interpolation and weight-decay regularization.
Supervised sparse auto-encoders as unconstrained feature models for semantic composition
Jan 31, 2026Sparse auto-encoders (SAEs) have re-emerged as a prominent method for mechanistic interpretability, yet they face two significant challenges: the non-smoothness of the $L_1$ penalty, which hinders reconstruction and scalability, and a lack of alignment between learned features and human semantics. In this paper, we address these limitations by adapting unconstrained feature models-a mathematical framework from neural collapse theory-and by supervising the task. We supervise (decoder-only) SAEs to reconstruct feature vectors by jointly learning sparse concept embeddings and decoder weights. Validated on Stable Diffusion 3.5, our approach demonstrates compositional generalization, successfully reconstructing images with concept combinations unseen during training, and enabling feature-level intervention for semantic image editing without prompt modification.
Evaluation Under Imperfect Benchmarks and Ratings: A Case Study in Text Simplification
Apr 15, 2025
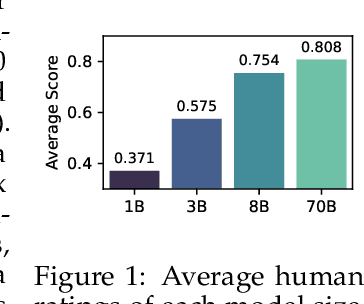


Despite the successes of language models, their evaluation remains a daunting challenge for new and existing tasks. We consider the task of text simplification, commonly used to improve information accessibility, where evaluation faces two major challenges. First, the data in existing benchmarks might not reflect the capabilities of current language models on the task, often containing disfluent, incoherent, or simplistic examples. Second, existing human ratings associated with the benchmarks often contain a high degree of disagreement, resulting in inconsistent ratings; nevertheless, existing metrics still have to show higher correlations with these imperfect ratings. As a result, evaluation for the task is not reliable and does not reflect expected trends (e.g., more powerful models being assigned higher scores). We address these challenges for the task of text simplification through three contributions. First, we introduce SynthSimpliEval, a synthetic benchmark for text simplification featuring simplified sentences generated by models of varying sizes. Through a pilot study, we show that human ratings on our benchmark exhibit high inter-annotator agreement and reflect the expected trend: larger models produce higher-quality simplifications. Second, we show that auto-evaluation with a panel of LLM judges (LLMs-as-a-jury) often suffices to obtain consistent ratings for the evaluation of text simplification. Third, we demonstrate that existing learnable metrics for text simplification benefit from training on our LLMs-as-a-jury-rated synthetic data, closing the gap with pure LLMs-as-a-jury for evaluation. Overall, through our case study on text simplification, we show that a reliable evaluation requires higher quality test data, which could be obtained through synthetic data and LLMs-as-a-jury ratings.
Position: Solve Layerwise Linear Models First to Understand Neural Dynamical Phenomena (Neural Collapse, Emergence, Lazy/Rich Regime, and Grokking)
Feb 28, 2025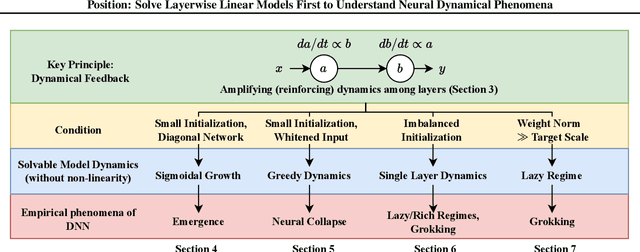
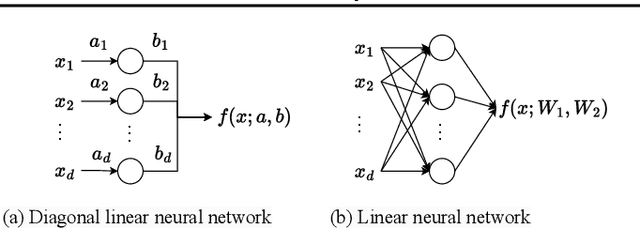
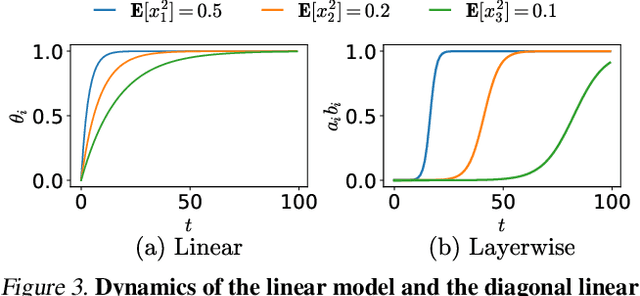
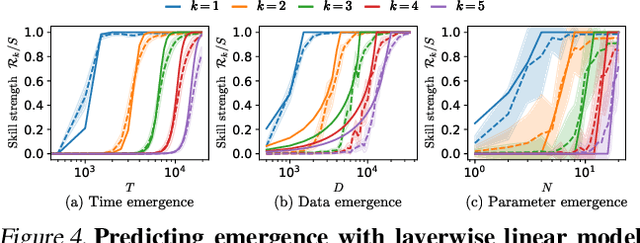
In physics, complex systems are often simplified into minimal, solvable models that retain only the core principles. In machine learning, layerwise linear models (e.g., linear neural networks) act as simplified representations of neural network dynamics. These models follow the dynamical feedback principle, which describes how layers mutually govern and amplify each other's evolution. This principle extends beyond the simplified models, successfully explaining a wide range of dynamical phenomena in deep neural networks, including neural collapse, emergence, lazy and rich regimes, and grokking. In this position paper, we call for the use of layerwise linear models retaining the core principles of neural dynamical phenomena to accelerate the science of deep learning.
Visualising Feature Learning in Deep Neural Networks by Diagonalizing the Forward Feature Map
Oct 05, 2024



Deep neural networks (DNNs) exhibit a remarkable ability to automatically learn data representations, finding appropriate features without human input. Here we present a method for analysing feature learning by decomposing DNNs into 1) a forward feature-map $\Phi$ that maps the input dataspace to the post-activations of the penultimate layer, and 2) a final linear layer that classifies the data. We diagonalize $\Phi$ with respect to the gradient descent operator and track feature learning by measuring how the eigenfunctions and eigenvalues of $\Phi$ change during training. Across many popular architectures and classification datasets, we find that DNNs converge, after just a few epochs, to a minimal feature (MF) regime dominated by a number of eigenfunctions equal to the number of classes. This behaviour resembles the neural collapse phenomenon studied at longer training times. For other DNN-data combinations, such as a fully connected network on CIFAR10, we find an extended feature (EF) regime where significantly more features are used. Optimal generalisation performance upon hyperparameter tuning typically coincides with the MF regime, but we also find examples of poor performance within the MF regime. Finally, we recast the phenomenon of neural collapse into a kernel picture which can be extended to broader tasks such as regression.
Exploiting the equivalence between quantum neural networks and perceptrons
Jul 05, 2024
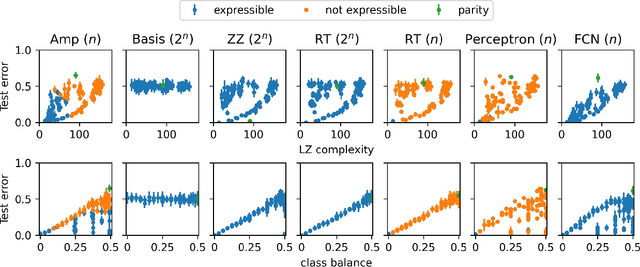
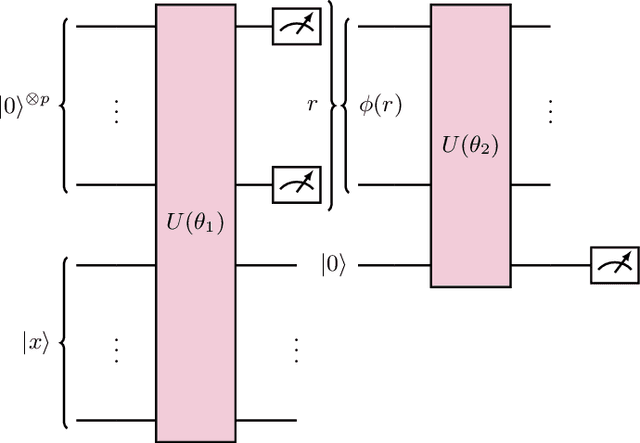
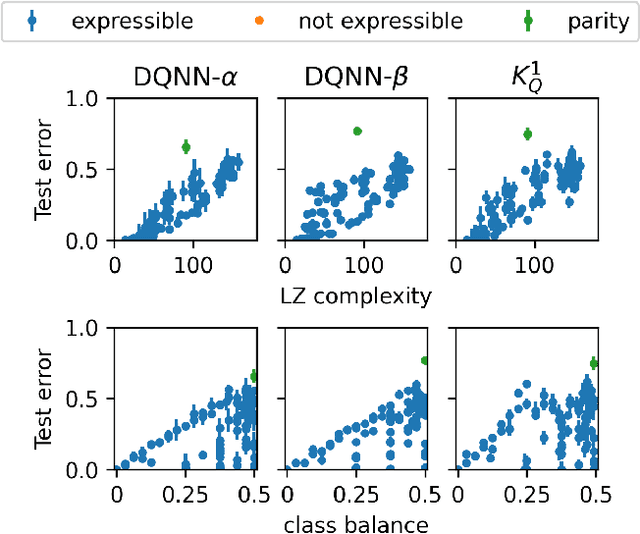
Quantum machine learning models based on parametrized quantum circuits, also called quantum neural networks (QNNs), are considered to be among the most promising candidates for applications on near-term quantum devices. Here we explore the expressivity and inductive bias of QNNs by exploiting an exact mapping from QNNs with inputs $x$ to classical perceptrons acting on $x \otimes x$ (generalised to complex inputs). The simplicity of the perceptron architecture allows us to provide clear examples of the shortcomings of current QNN models, and the many barriers they face to becoming useful general-purpose learning algorithms. For example, a QNN with amplitude encoding cannot express the Boolean parity function for $n\geq 3$, which is but one of an exponential number of data structures that such a QNN is unable to express. Mapping a QNN to a classical perceptron simplifies training, allowing us to systematically study the inductive biases of other, more expressive embeddings on Boolean data. Several popular embeddings primarily produce an inductive bias towards functions with low class balance, reducing their generalisation performance compared to deep neural network architectures which exhibit much richer inductive biases. We explore two alternate strategies that move beyond standard QNNs. In the first, we use a QNN to help generate a classical DNN-inspired kernel. In the second we draw an analogy to the hierarchical structure of deep neural networks and construct a layered non-linear QNN that is provably fully expressive on Boolean data, while also exhibiting a richer inductive bias than simple QNNs. Finally, we discuss characteristics of the QNN literature that may obscure how hard it is to achieve quantum advantage over deep learning algorithms on classical data.
An exactly solvable model for emergence and scaling laws
Apr 26, 2024

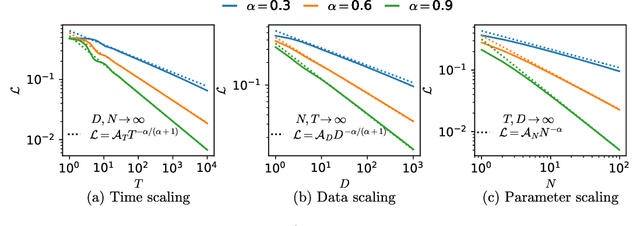

Deep learning models can exhibit what appears to be a sudden ability to solve a new problem as training time ($T$), training data ($D$), or model size ($N$) increases, a phenomenon known as emergence. In this paper, we present a framework where each new ability (a skill) is represented as a basis function. We solve a simple multi-linear model in this skill-basis, finding analytic expressions for the emergence of new skills, as well as for scaling laws of the loss with training time, data size, model size, and optimal compute ($C$). We compare our detailed calculations to direct simulations of a two-layer neural network trained on multitask sparse parity, where the tasks in the dataset are distributed according to a power-law. Our simple model captures, using a single fit parameter, the sigmoidal emergence of multiple new skills as training time, data size or model size increases in the neural network.
Does Video Summarization Require Videos? Quantifying the Effectiveness of Language in Video Summarization
Sep 18, 2023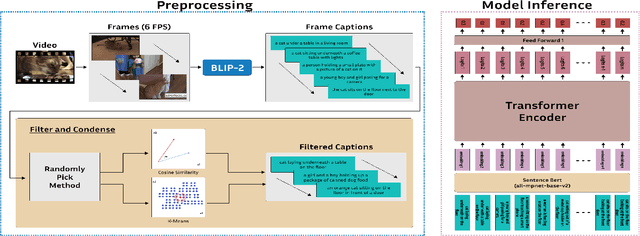
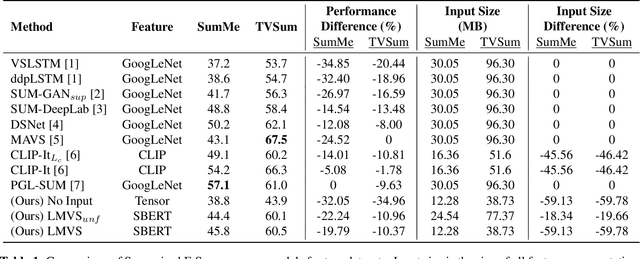

Video summarization remains a huge challenge in computer vision due to the size of the input videos to be summarized. We propose an efficient, language-only video summarizer that achieves competitive accuracy with high data efficiency. Using only textual captions obtained via a zero-shot approach, we train a language transformer model and forego image representations. This method allows us to perform filtration amongst the representative text vectors and condense the sequence. With our approach, we gain explainability with natural language that comes easily for human interpretation and textual summaries of the videos. An ablation study that focuses on modality and data compression shows that leveraging text modality only effectively reduces input data processing while retaining comparable results.
HyperTendril: Visual Analytics for User-Driven Hyperparameter Optimization of Deep Neural Networks
Sep 18, 2020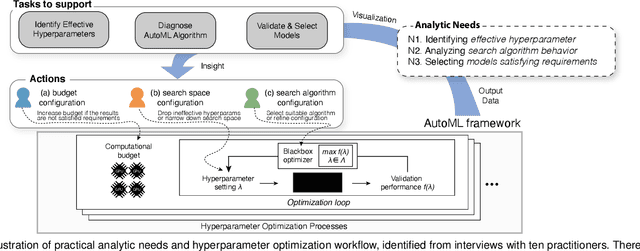
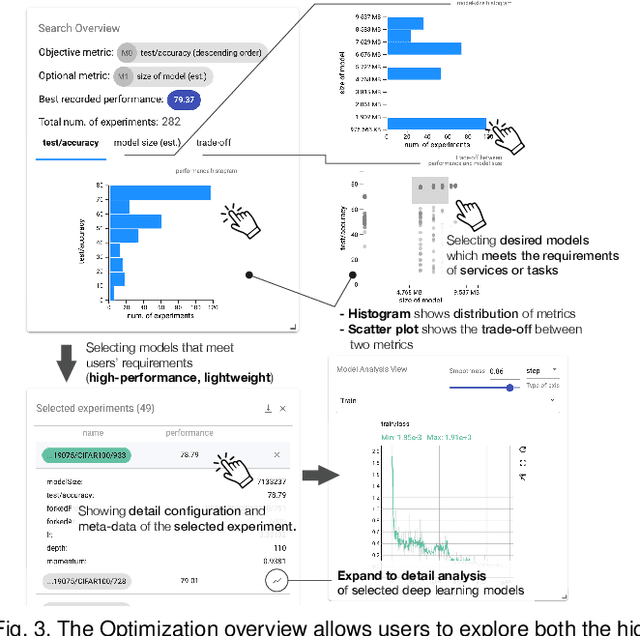
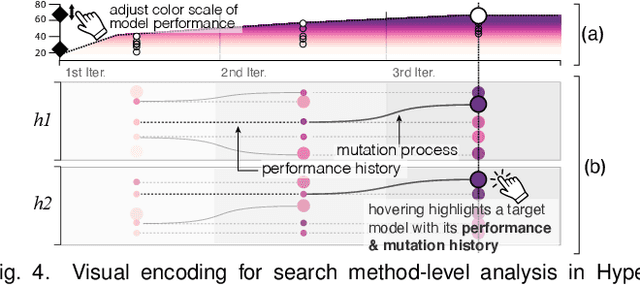
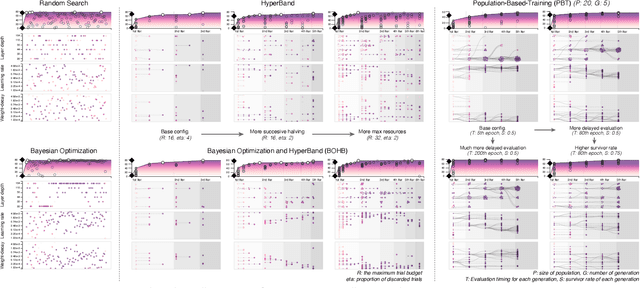
To mitigate the pain of manually tuning hyperparameters of deep neural networks, automated machine learning (AutoML) methods have been developed to search for an optimal set of hyperparameters in large combinatorial search spaces. However, the search results of AutoML methods significantly depend on initial configurations, making it a non-trivial task to find a proper configuration. Therefore, human intervention via a visual analytic approach bears huge potential in this task. In response, we propose HyperTendril, a web-based visual analytics system that supports user-driven hyperparameter tuning processes in a model-agnostic environment. HyperTendril takes a novel approach to effectively steering hyperparameter optimization through an iterative, interactive tuning procedure that allows users to refine the search spaces and the configuration of the AutoML method based on their own insights from given results. Using HyperTendril, users can obtain insights into the complex behaviors of various hyperparameter search algorithms and diagnose their configurations. In addition, HyperTendril supports variable importance analysis to help the users refine their search spaces based on the analysis of relative importance of different hyperparameters and their interaction effects. We present the evaluation demonstrating how HyperTendril helps users steer their tuning processes via a longitudinal user study based on the analysis of interaction logs and in-depth interviews while we deploy our system in a professional industrial environment.