 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Under Imperfect Benchmarks and Ratings: A Case Study in Text Simplification
Paper and Code

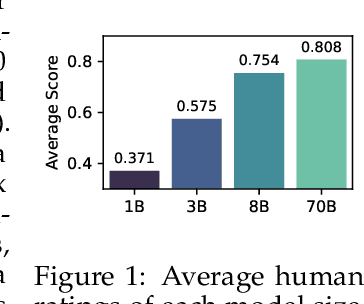


Despite the successes of language models, their evaluation remains a daunting challenge for new and existing tasks. We consider the task of text simplification, commonly used to improve information accessibility, where evaluation faces two major challenges. First, the data in existing benchmarks might not reflect the capabilities of current language models on the task, often containing disfluent, incoherent, or simplistic examples. Second, existing human ratings associated with the benchmarks often contain a high degree of disagreement, resulting in inconsistent ratings; nevertheless, existing metrics still have to show higher correlations with these imperfect ratings. As a result, evaluation for the task is not reliable and does not reflect expected trends (e.g., more powerful models being assigned higher scores). We address these challenges for the task of text simplification through three contributions. First, we introduce SynthSimpliEval, a synthetic benchmark for text simplification featuring simplified sentences generated by models of varying sizes. Through a pilot study, we show that human ratings on our benchmark exhibit high inter-annotator agreement and reflect the expected trend: larger models produce higher-quality simplifications. Second, we show that auto-evaluation with a panel of LLM judges (LLMs-as-a-jury) often suffices to obtain consistent ratings for the evaluation of text simplification. Third, we demonstrate that existing learnable metrics for text simplification benefit from training on our LLMs-as-a-jury-rated synthetic data, closing the gap with pure LLMs-as-a-jury for evaluation. Overall, through our case study on text simplification, we show that a reliable evaluation requires higher quality test data, which could be obtained through synthetic data and LLMs-as-a-jury ratings.