 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Artificial Intelligence Research Assistant for Expert-Involved Learning
May 03, 2025Large Language Models (LLMs) and Large Multi-Modal Models (LMMs) have emerged as transformative tools in scientific research, yet their reliability and specific contributions to biomedical applications remain insufficiently characterized. In this study, we present \textbf{AR}tificial \textbf{I}ntelligence research assistant for \textbf{E}xpert-involved \textbf{L}earning (ARIEL), a multimodal dataset designed to benchmark and enhance two critical capabilities of LLMs and LMMs in biomedical research: summarizing extensive scientific texts and interpreting complex biomedical figures. To facilitate rigorous assessment, we create two open-source sets comprising biomedical articles and figures with designed questions. We systematically benchmark both open- and closed-source foundation models, incorporating expert-driven human evaluations conducted by doctoral-level experts. Furthermore, we improve model performance through targeted prompt engineering and fine-tuning strategies for summarizing research papers, and apply test-time computational scaling to enhance the reasoning capabilities of LMMs, achieving superior accuracy compared to human-expert corrections. We also explore the potential of using LMM Agents to generate scientific hypotheses from diverse multimodal inputs. Overall, our results delineate clear strengths and highlight significant limitations of current foundation models, providing actionable insights and guiding future advancements in deploying large-scale language and multi-modal models within biomedical research.
Evaluation Under Imperfect Benchmarks and Ratings: A Case Study in Text Simplification
Apr 15, 2025
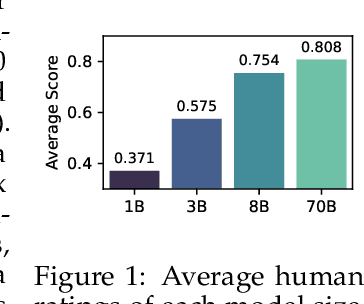


Despite the successes of language models, their evaluation remains a daunting challenge for new and existing tasks. We consider the task of text simplification, commonly used to improve information accessibility, where evaluation faces two major challenges. First, the data in existing benchmarks might not reflect the capabilities of current language models on the task, often containing disfluent, incoherent, or simplistic examples. Second, existing human ratings associated with the benchmarks often contain a high degree of disagreement, resulting in inconsistent ratings; nevertheless, existing metrics still have to show higher correlations with these imperfect ratings. As a result, evaluation for the task is not reliable and does not reflect expected trends (e.g., more powerful models being assigned higher scores). We address these challenges for the task of text simplification through three contributions. First, we introduce SynthSimpliEval, a synthetic benchmark for text simplification featuring simplified sentences generated by models of varying sizes. Through a pilot study, we show that human ratings on our benchmark exhibit high inter-annotator agreement and reflect the expected trend: larger models produce higher-quality simplifications. Second, we show that auto-evaluation with a panel of LLM judges (LLMs-as-a-jury) often suffices to obtain consistent ratings for the evaluation of text simplification. Third, we demonstrate that existing learnable metrics for text simplification benefit from training on our LLMs-as-a-jury-rated synthetic data, closing the gap with pure LLMs-as-a-jury for evaluation. Overall, through our case study on text simplification, we show that a reliable evaluation requires higher quality test data, which could be obtained through synthetic data and LLMs-as-a-jury ratings.
Robust Data Watermarking in Language Models by Injecting Fictitious Knowledge
Mar 06, 2025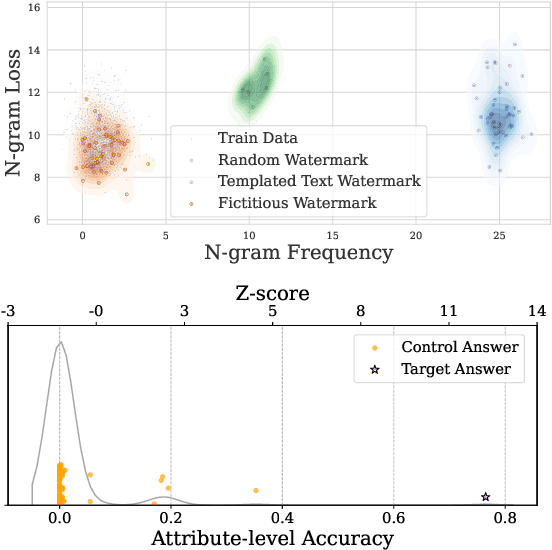

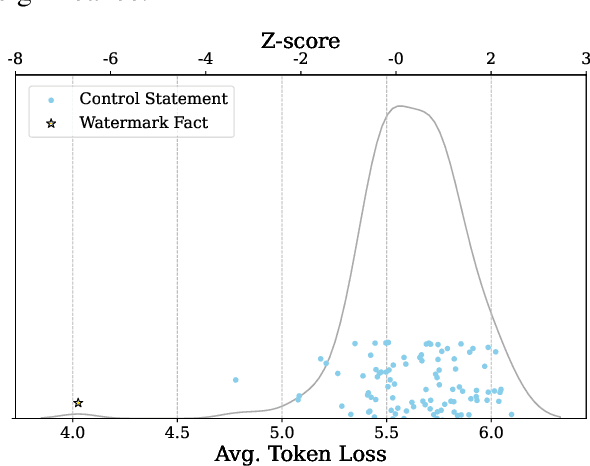

Data watermarking in language models injects traceable signals, such as specific token sequences or stylistic patterns, into copyrighted text, allowing copyright holders to track and verify training data ownership. Previous data watermarking techniques primarily focus on effective memorization after pretraining, while overlooking challenges that arise in other stages of the LLM pipeline, such as the risk of watermark filtering during data preprocessing, or potential forgetting through post-training, or verification difficulties due to API-only access. We propose a novel data watermarking approach that injects coherent and plausible yet fictitious knowledge into training data using generated passages describing a fictitious entity and its associated attributes. Our watermarks are designed to be memorized by the LLM through seamlessly integrating in its training data, making them harder to detect lexically during preprocessing.We demonstrate that our watermarks can be effectively memorized by LLMs, and that increasing our watermarks' density, length, and diversity of attributes strengthens their memorization. We further show that our watermarks remain robust throughout LLM development, maintaining their effectiveness after continual pretraining and supervised finetuning. Finally, we show that our data watermarks can be evaluated even under API-only access via question answering.
Annotating FrameNet via Structure-Conditioned Language Generation
Jun 07, 2024



Despite the remarkable generative capabilities of language models in producing naturalistic language, their effectiveness on explicit manipulation and generation of linguistic structures remain understudied. In this paper, we investigate the task of generating new sentences preserving a given semantic structure, following the FrameNet formalism. We propose a framework to produce novel frame-semantically annotated sentences following an overgenerate-and-filter approach. Our results show that conditioning on rich, explicit semantic information tends to produce generations with high human acceptance, under both prompting and finetuning. Our generated frame-semantic structured annotations are effective at training data augmentation for frame-semantic role labeling in low-resource settings; however, we do not see benefits under higher resource settings. Our study concludes that while generating high-quality, semantically rich data might be within reach, the downstream utility of such generations remains to be seen, highlighting the outstanding challenges with automating linguistic annotation tasks.
A Multi-Task Semantic Decomposition Framework with Task-specific Pre-training for Few-Shot NER
Aug 28, 2023
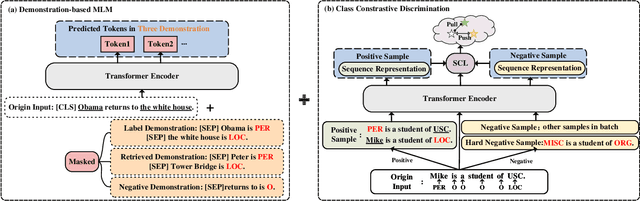

The objective of few-shot named entity recognition is to identify named entities with limited labeled instances. Previous works have primarily focused on optimizing the traditional token-wise classification framework, while neglecting the exploration of information based on NER data characteristics. To address this issue, we propose a Multi-Task Semantic Decomposition Framework via Joint Task-specific Pre-training (MSDP) for few-shot NER. Drawing inspiration from demonstration-based and contrastive learning, we introduce two novel pre-training tasks: Demonstration-based Masked Language Modeling (MLM) and Class Contrastive Discrimination. These tasks effectively incorporate entity boundary information and enhance entity representation in Pre-trained Language Models (PLMs). In the downstream main task, we introduce a multi-task joint optimization framework with the semantic decomposing method, which facilitates the model to integrate two different semantic information for entity classification. Experimental results of two few-shot NER benchmarks demonstrate that MSDP consistently outperforms strong baselines by a large margin. Extensive analyses validate the effectiveness and generalization of MSDP.
A Prototypical Semantic Decoupling Method via Joint Contrastive Learning for Few-Shot Name Entity Recognition
Feb 27, 2023



Few-shot named entity recognition (NER) aims at identifying named entities based on only few labeled instances. Most existing prototype-based sequence labeling models tend to memorize entity mentions which would be easily confused by close prototypes. In this paper, we proposed a Prototypical Semantic Decoupling method via joint Contrastive learning (PSDC) for few-shot NER. Specifically, we decouple class-specific prototypes and contextual semantic prototypes by two masking strategies to lead the model to focus on two different semantic information for inference. Besides, we further introduce joint contrastive learning objectives to better integrate two kinds of decoupling information and prevent semantic collapse. Experimental results on two few-shot NER benchmarks demonstrate that PSDC consistently outperforms the previous SOTA methods in terms of overall performance. Extensive analysis further validates the effectiveness and generalization of PSDC.
Revisit Out-Of-Vocabulary Problem for Slot Filling: A Unified Contrastive Frameword with Multi-level Data Augmentations
Feb 27, 2023In real dialogue scenarios, the existing slot filling model, which tends to memorize entity patterns, has a significantly reduced generalization facing Out-of-Vocabulary (OOV) problems. To address this issue, we propose an OOV robust slot filling model based on multi-level data augmentations to solve the OOV problem from both word and slot perspectives. We present a unified contrastive learning framework, which pull representations of the origin sample and augmentation samples together, to make the model resistant to OOV problems. We evaluate the performance of the model from some specific slots and carefully design test data with OOV word perturbation to further demonstrate the effectiveness of OOV words. Experiments on two datasets show that our approach outperforms the previous sota methods in terms of both OOV slots and words.
PSSAT: A Perturbed Semantic Structure Awareness Transferring Method for Perturbation-Robust Slot Filling
Aug 31, 2022
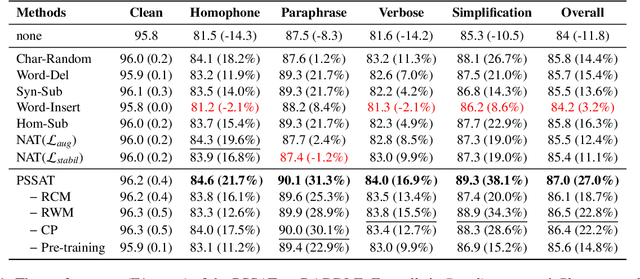
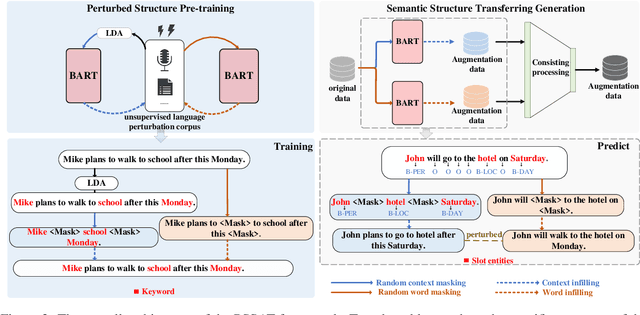
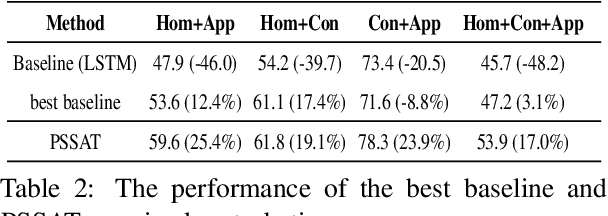
Most existing slot filling models tend to memorize inherent patterns of entities and corresponding contexts from training data. However, these models can lead to system failure or undesirable outputs when being exposed to spoken language perturbation or variation in practice. We propose a perturbed semantic structure awareness transferring method for training perturbation-robust slot filling models. Specifically, we introduce two MLM-based training strategies to respectively learn contextual semantic structure and word distribution from unsupervised language perturbation corpus. Then, we transfer semantic knowledge learned from upstream training procedure into the original samples and filter generated data by consistency processing. These procedures aim to enhance the robustness of slot filling models. Experimental results show that our method consistently outperforms the previous basic methods and gains strong generalization while preventing the model from memorizing inherent patterns of entities and contexts.
Using Machine Learning to Forecast Future Earnings
May 26, 2020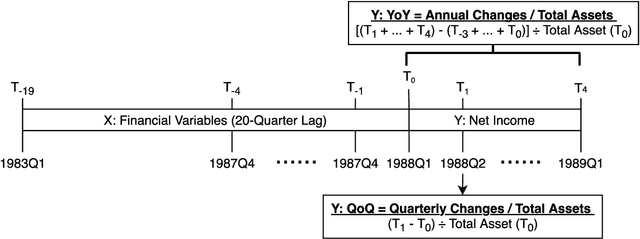
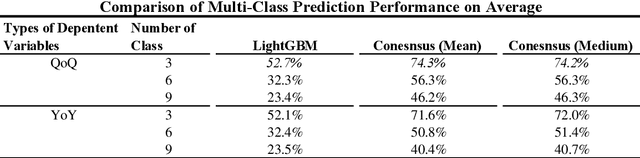
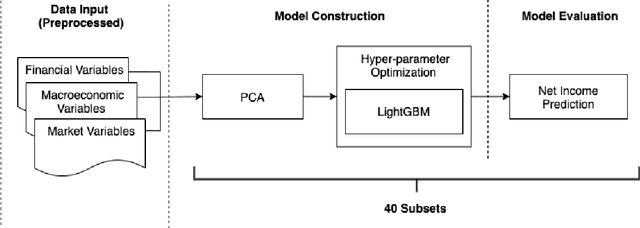
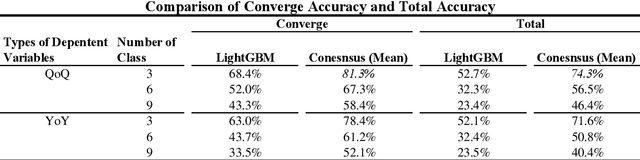
In this essay, we have comprehensively evaluated the feasibility and suitability of adopting the Machine Learning Models on the forecast of corporation fundamentals (i.e. the earnings), where the prediction results of our method have been thoroughly compared with both analysts' consensus estimation and traditional statistical models. As a result, our model has already been proved to be capable of serving as a favorable auxiliary tool for analysts to conduct better predictions on company fundamentals. Compared with previous traditional statistical models being widely adopted in the industry like Logistic Regression, our method has already achieved satisfactory advancement on both the prediction accuracy and speed. Meanwhile, we are also confident enough that there are still vast potentialities for this model to evolve, where we do hope that in the near future, the machine learning model could generate even better performances compared with professional analysts.