 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Based Near-Field User Localization with Beam Squint in Wideband XL-MIMO Systems
Dec 02, 2024



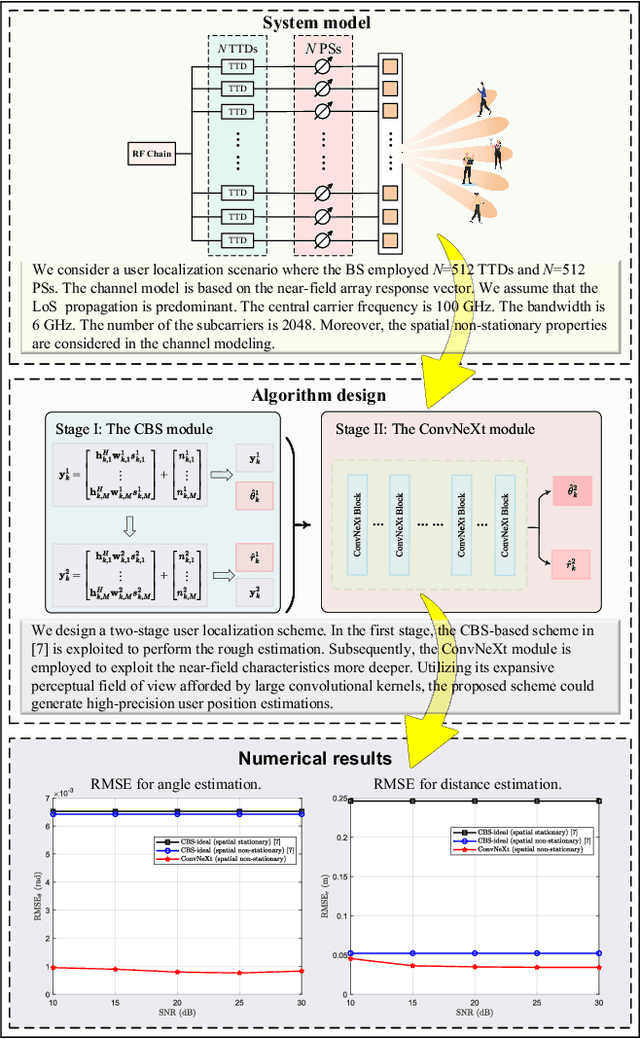
Extremely large-scale multiple-input multiple-output (XL-MIMO) is gaining attention as a prominent technology for enabling the sixth-generation (6G) wireless networks. However, the vast antenna array and the huge bandwidth introduce a non-negligible beam squint effect, causing beams of different frequencies to focus at different locations. One approach to cope with this is to employ true-time-delay lines (TTDs)-based beamforming to control the range and trajectory of near-field beam squint, known as the near-field controllable beam squint (CBS) effect. In this paper, we investigate the user localization in near-field wideband XL-MIMO systems under the beam squint effect and spatial non-stationary properties. Firstly, we derive the expressions for Cram\'er-Rao Bounds (CRBs) for characterizing the performance of estimating both angle and distance. This analysis aims to assess the potential of leveraging CBS for precise user localization. Secondly, a user localization scheme combining CBS and beam training is proposed. Specifically, we organize multiple subcarriers into groups, directing beams from different groups to distinct angles or distances through the CBS to obtain the estimates of users' angles and distances. Furthermore, we design a user localization scheme based on a convolutional neural network model, namely ConvNeXt. This scheme utilizes the inputs and outputs of the CBS-based scheme to generate high-precision estimates of angle and distance. More importantly, our proposed ConvNeXt-based user localization scheme achieves centimeter-level accuracy in localization estimates.
Near-Field User Localization and Channel Estimation for XL-MIMO Systems: Fundamentals, Recent Advances, and Outlooks
Jul 14, 2024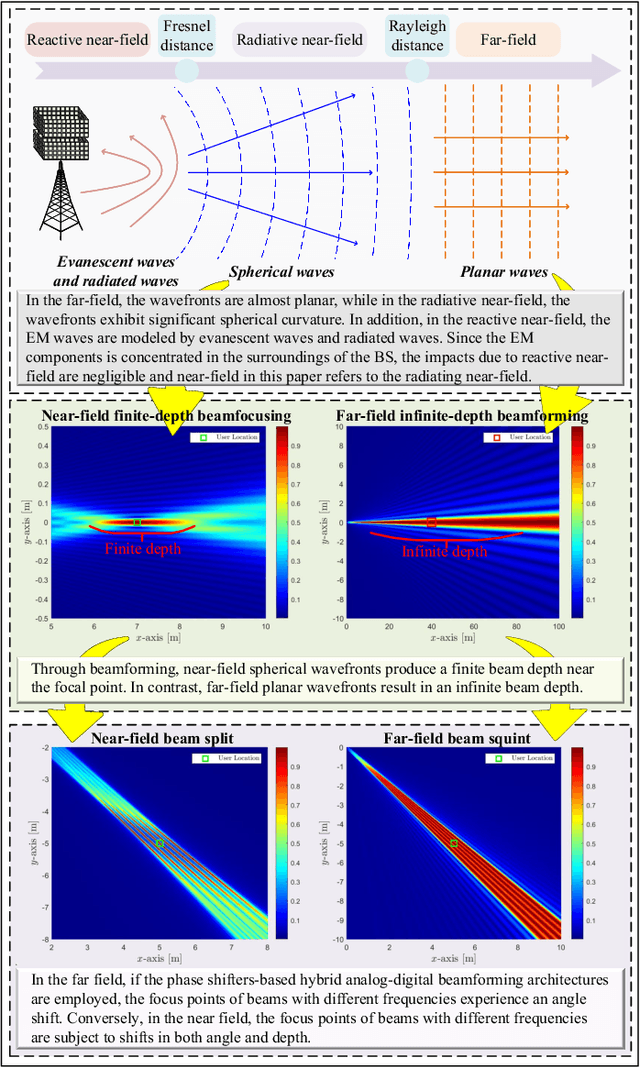
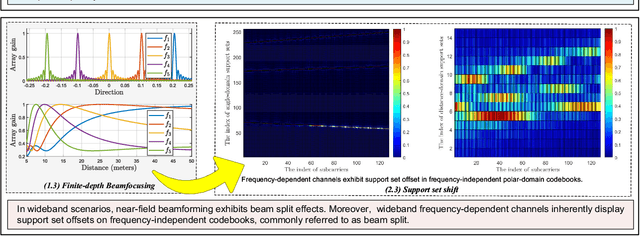
Extremely large-scale multiple-input multipleoutput (XL-MIMO) is believed to be a cornerstone of sixth-generation (6G) wireless networks. XL-MIMO uses more antennas to both achieve unprecedented spatial degrees of freedom (DoFs) and exploit new electromagnetic (EM) phenomena occurring in the radiative near-field. The near-field effects provide the XL-MIMO array with depth perception, enabling precise localization and spatially multiplexing jointly in the angle and distance domains. This article delineates the distinctions between near-field and far-field propagation, highlighting the unique EM characteristics introduced by having large antenna arrays. It thoroughly examines the challenges these new near-field characteristics pose for user localization and channel estimation and provides a comprehensive review of new algorithms developed to address them. The article concludes by identifying critical future research directions.
Hybrid-Field Channel Estimation for XL-MIMO Systems with Stochastic Gradient Pursuit Algorithm
May 24, 2024
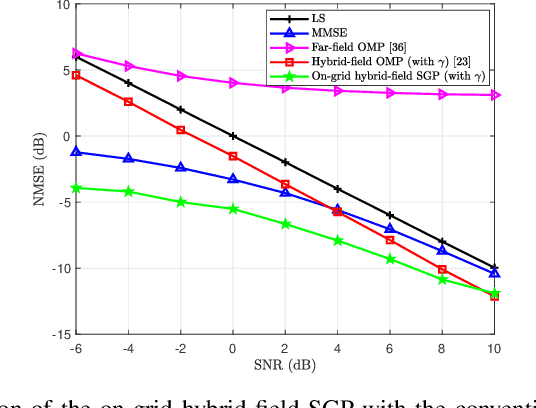

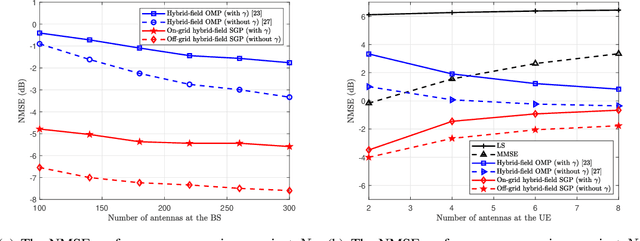
Extremely large-scale multiple-input multiple-output (XL-MIMO) is crucial for satisfying the high data rate requirements of the sixth-generation (6G) wireless networks. In this context, ensuring accurate acquisition of channel state information (CSI) with low complexity becomes imperative. Moreover, deploying an extremely large antenna array at the base station (BS) might result in some scatterers being located in near-field, while others are situated in far-field, leading to a hybrid-field communication scenario. To address these challenges, this paper introduces two stochastic gradient pursuit (SGP)-based schemes for the hybrid-field channel estimation in two scenarios. For the first scenario in which the prior knowledge of the specific proportion of the number of near-field and far-field channel paths is known, the scheme can effectively leverage the angular-domain sparsity of the far-field channels and the polar-domain sparsity of the near-field channels such that the channel estimation in these two fields can be performed separately. For the second scenario which the proportion is not available, we propose an off-grid SGP-based channel estimation scheme, which iterates through the values of the proportion parameter based on a criterion before performing the hybrid-field channel estimation. We demonstrate numerically that both of the proposed channel estimation schemes achieve superior performance in terms of both estimation accuracy and achievable rates while enjoying lower computational complexity compared with existing schemes. Additionally, we reveal that as the number of antennas at the UE increases, the normalized mean square error (NMSE) performances of the proposed schemes remain basically unchanged, while the NMSE performances of existing ones improve. Remarkably, even in this scenario, the proposed schemes continue to outperform the existing ones.
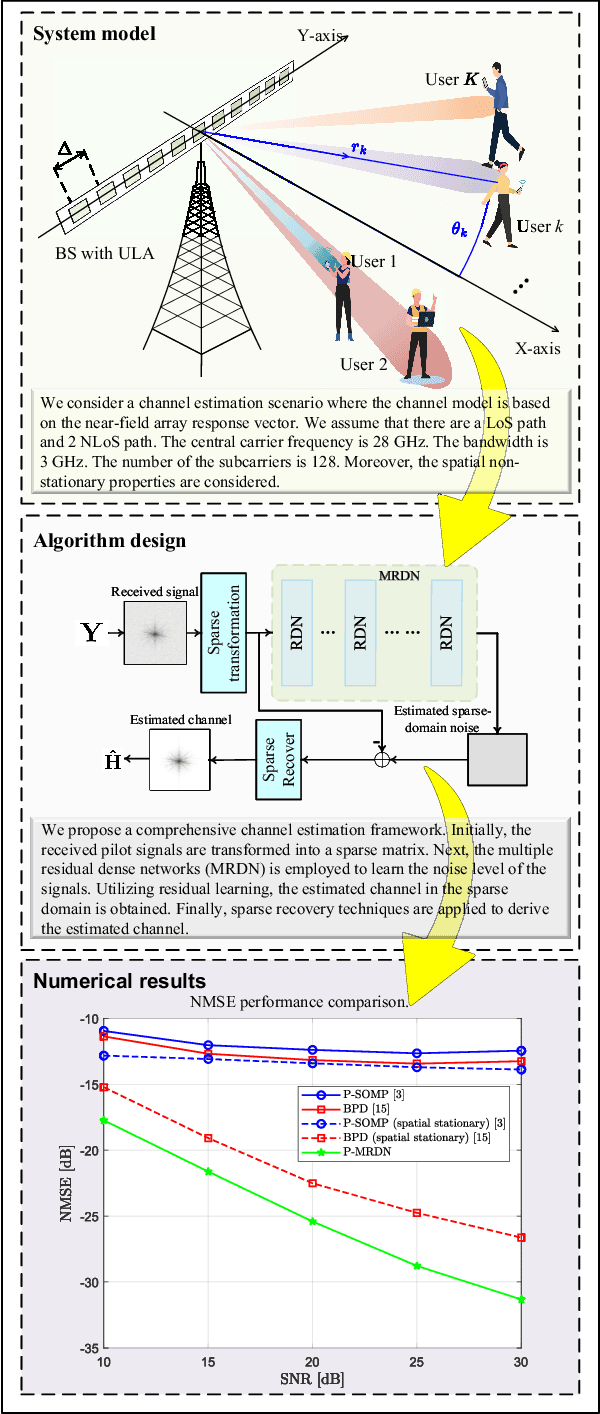
Channel Estimation for XL-MIMO Systems with Polar-Domain Multi-Scale Residual Dense Network
Sep 02, 2023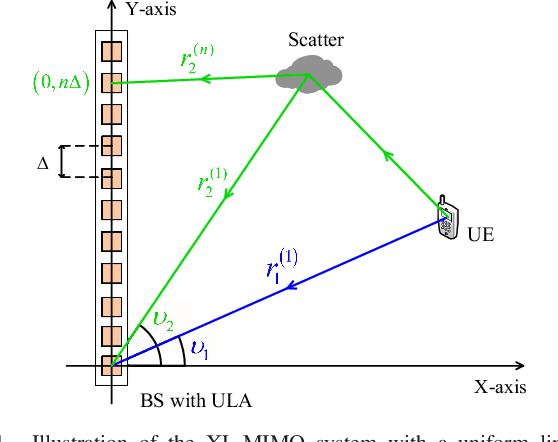
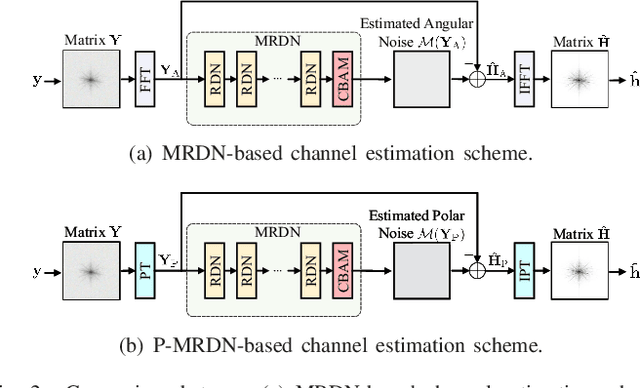
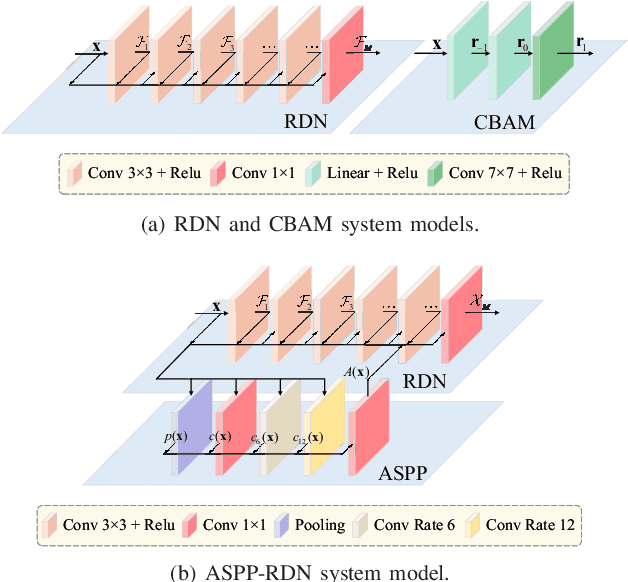
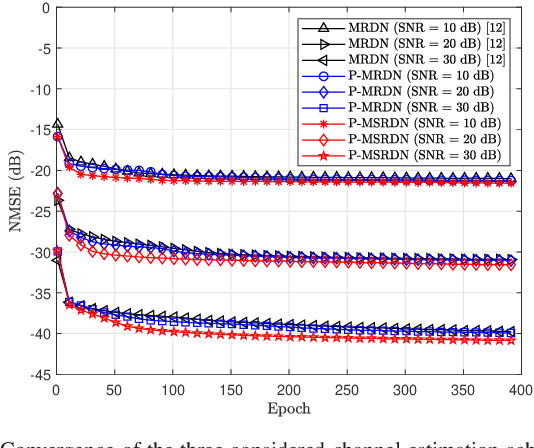
Extremely large-scale multiple-input multiple-output (XL-MIMO) is a promising technique to enable versatile applications for future wireless communications.To realize the huge potential performance gain, accurate channel state information is a fundamental technical prerequisite. In conventional massive MIMO, the channel is often modeled by the far-field planar-wavefront with rich sparsity in the angular domain that facilitates the design of low-complexity channel estimation. However, this sparsity is not conspicuous in XL-MIMO systems due to the non-negligible near-field spherical-wavefront. To address the inherent performance loss of the angular-domain channel estimation schemes, we first propose the polar-domain multiple residual dense network (P-MRDN) for XL-MIMO systems based on the polar-domain sparsity of the near-field channel by improving the existing MRDN scheme. Furthermore, a polar-domain multi-scale residual dense network (P-MSRDN) is designed to improve the channel estimation accuracy. Finally, simulation results reveal the superior performance of the proposed schemes compared with existing benchmark schemes and the minimal influence of the channel sparsity on the proposed schemes.
Generative Zero-Shot Prompt Learning for Cross-Domain Slot Filling with Inverse Prompting
Jul 06, 2023Zero-shot cross-domain slot filling aims to transfer knowledge from the labeled source domain to the unlabeled target domain. Existing models either encode slot descriptions and examples or design handcrafted question templates using heuristic rules, suffering from poor generalization capability or robustness. In this paper, we propose a generative zero-shot prompt learning framework for cross-domain slot filling, both improving generalization and robustness than previous work. Besides, we introduce a novel inverse prompting strategy to distinguish different slot types to avoid the multiple prediction problem, and an efficient prompt-tuning strategy to boost higher performance by only training fewer prompt parameters. Experiments and analysis demonstrate the effectiveness of our proposed framework, especially huge improvements (+13.44% F1) on the unseen slots.
Uplink Performance of Cell-Free Extremely Large-Scale MIMO Systems
Feb 14, 2023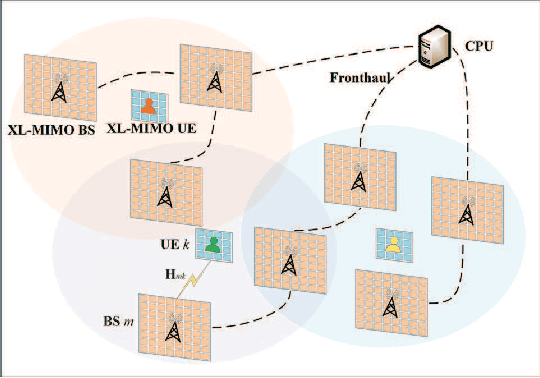
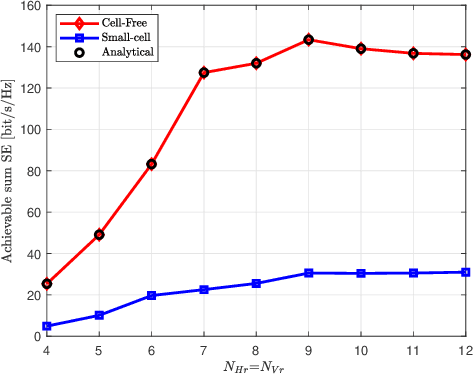
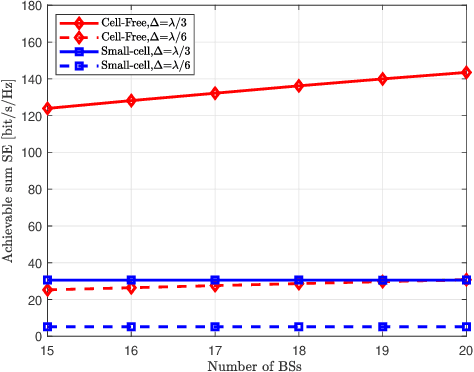
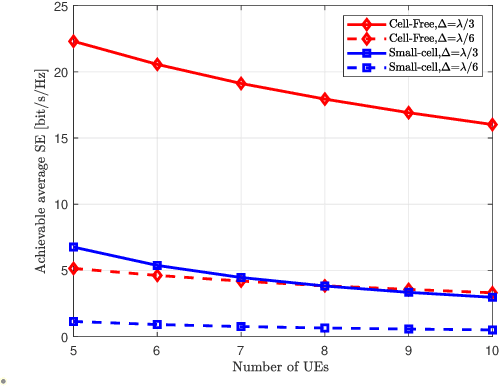
In this paper, we investigate the uplink performance of cell-free (CF) extremely large-scale multiple-input-multipleoutput (XL-MIMO) systems, which is a promising technique for future wireless communications. More specifically, we consider the practical scenario with multiple base stations (BSs) and multiple user equipments (UEs). To this end, we derive exact achievable spectral efficiency (SE) expressions for any combining scheme. It is worth noting that we derive the closed-form SE expressions for the CF XL-MIMO with maximum ratio (MR) combining. Numerical results show that the SE performance of the CF XL-MIMO can be hugely improved compared with the small-cell XL-MIMO. It is interesting that a smaller antenna spacing leads to a higher correlation level among patch antennas. Finally, we prove that increasing the number of UE antennas may decrease the SE performance with MR combining.
PSSAT: A Perturbed Semantic Structure Awareness Transferring Method for Perturbation-Robust Slot Filling
Aug 31, 2022
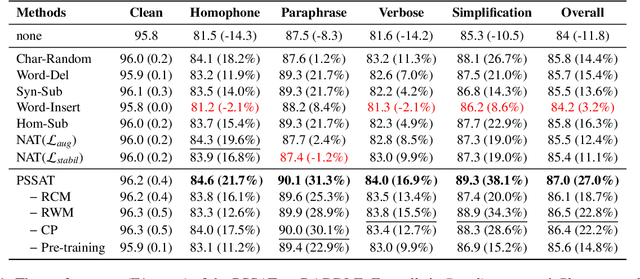
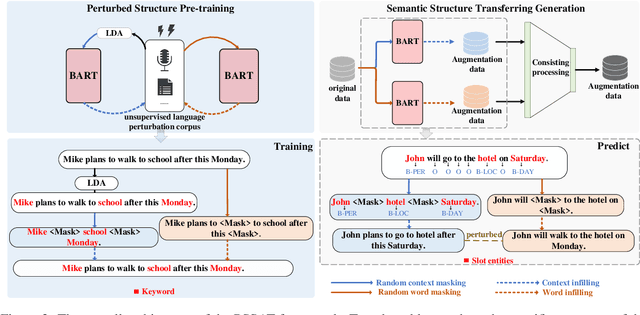
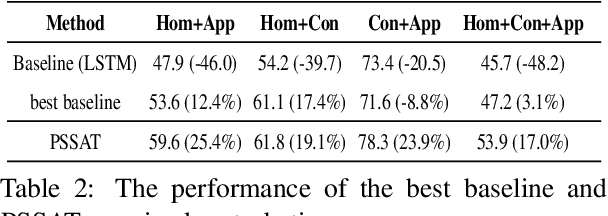
Most existing slot filling models tend to memorize inherent patterns of entities and corresponding contexts from training data. However, these models can lead to system failure or undesirable outputs when being exposed to spoken language perturbation or variation in practice. We propose a perturbed semantic structure awareness transferring method for training perturbation-robust slot filling models. Specifically, we introduce two MLM-based training strategies to respectively learn contextual semantic structure and word distribution from unsupervised language perturbation corpus. Then, we transfer semantic knowledge learned from upstream training procedure into the original samples and filter generated data by consistency processing. These procedures aim to enhance the robustness of slot filling models. Experimental results show that our method consistently outperforms the previous basic methods and gains strong generalization while preventing the model from memorizing inherent patterns of entities and contexts.
A Robust Contrastive Alignment Method For Multi-Domain Text Classification
Apr 26, 2022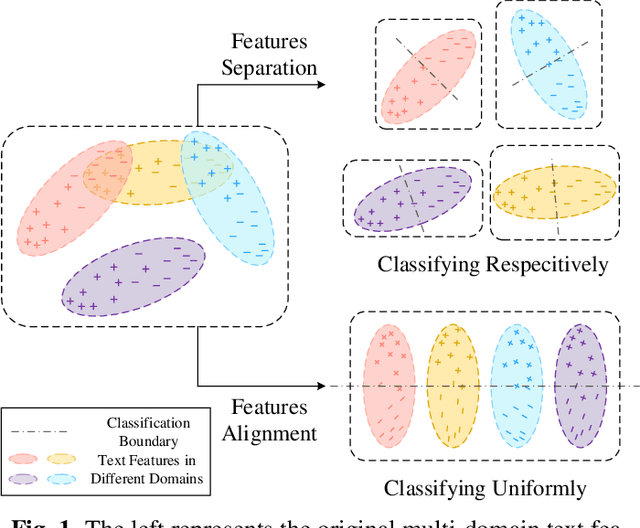
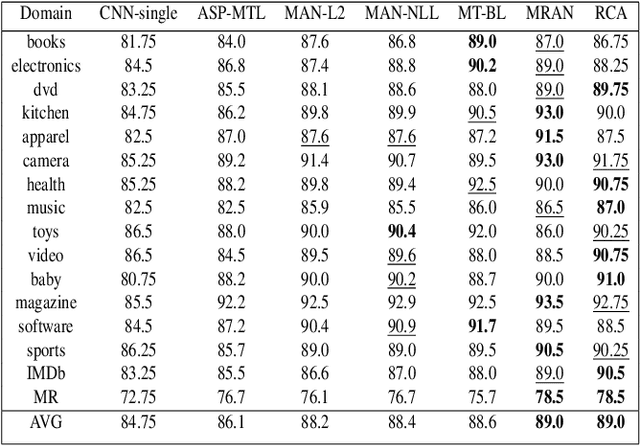
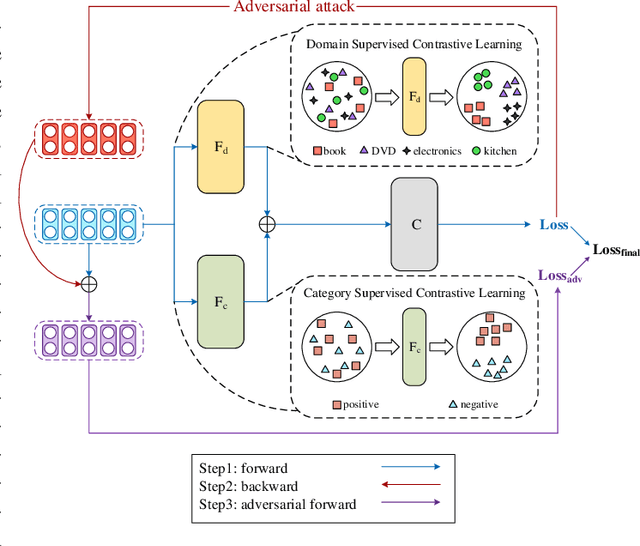
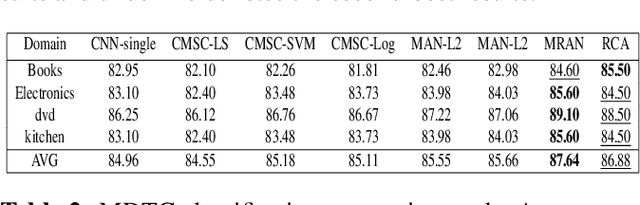
Multi-domain text classification can automatically classify texts in various scenarios. Due to the diversity of human languages, texts with the same label in different domains may differ greatly, which brings challenges to the multi-domain text classification. Current advanced methods use the private-shared paradigm, capturing domain-shared features by a shared encoder, and training a private encoder for each domain to extract domain-specific features. However, in realistic scenarios, these methods suffer from inefficiency as new domains are constantly emerging. In this paper, we propose a robust contrastive alignment method to align text classification features of various domains in the same feature space by supervised contrastive learning. By this means, we only need two universal feature extractors to achieve multi-domain text classification. Extensive experimental results show that our method performs on par with or sometimes better than the state-of-the-art method, which uses the complex multi-classifier in a private-shared framework.
Concentrated Document Topic Model
Feb 06, 2021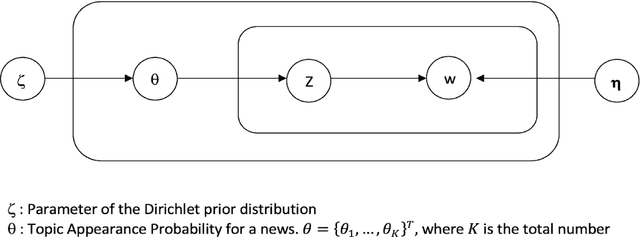

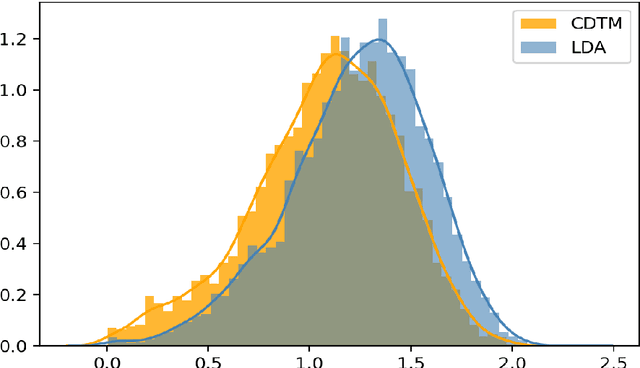
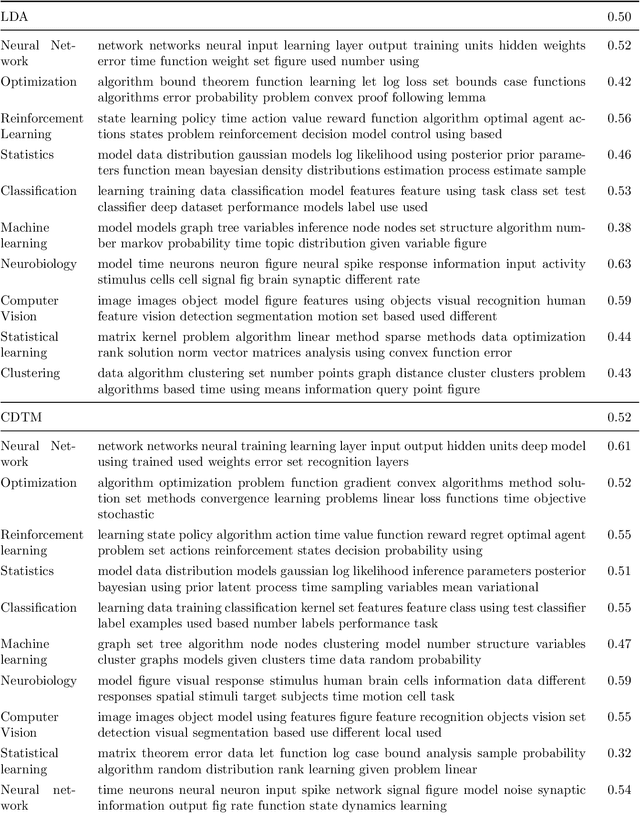
We propose a Concentrated Document Topic Model(CDTM) for unsupervised text classification, which is able to produce a concentrated and sparse document topic distribution. In particular, an exponential entropy penalty is imposed on the document topic distribution. Documents that have diverse topic distributions are penalized more, while those having concentrated topics are penalized less. We apply the model to the benchmark NIPS dataset and observe more coherent topics and more concentrated and sparse document-topic distributions than Latent Dirichlet Allocation(LDA).
Exclusive Topic Modeling
Feb 06, 2021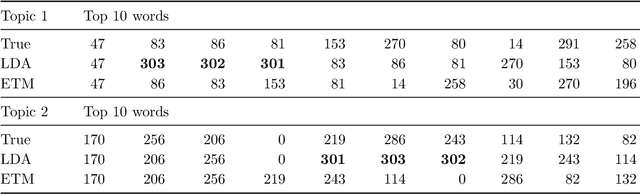
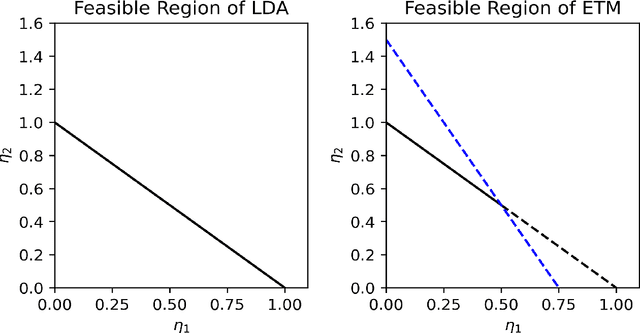

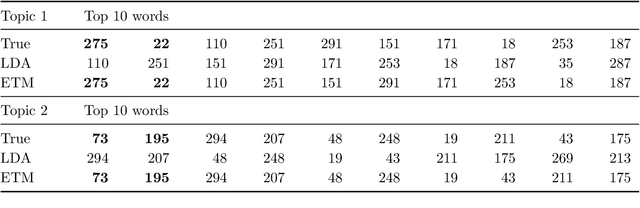
We propose an Exclusive Topic Modeling (ETM) for unsupervised text classification, which is able to 1) identify the field-specific keywords though less frequently appeared and 2) deliver well-structured topics with exclusive words. In particular, a weighted Lasso penalty is imposed to reduce the dominance of the frequently appearing yet less relevant words automatically, and a pairwise Kullback-Leibler divergence penalty is used to implement topics separation. Simulation studies demonstrate that the ETM detects the field-specific keywords, while LDA fails. When applying to the benchmark NIPS dataset, the topic coherence score on average improves by 22% and 10% for the model with weighted Lasso penalty and pairwise Kullback-Leibler divergence penalty, respectively.