 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion Makes Perfection: An Efficient Multi-Grained Matching Approach for Zero-Shot Relation Extraction
Jun 17, 2024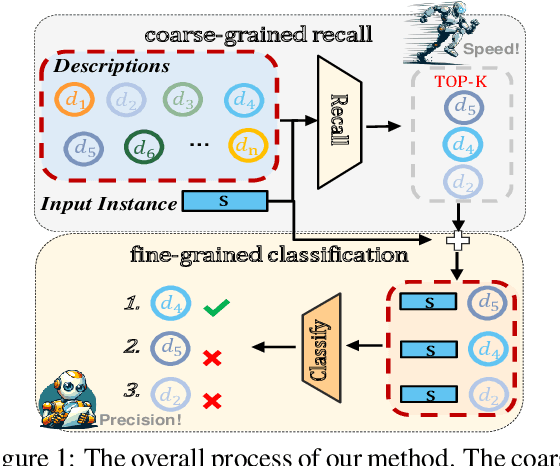
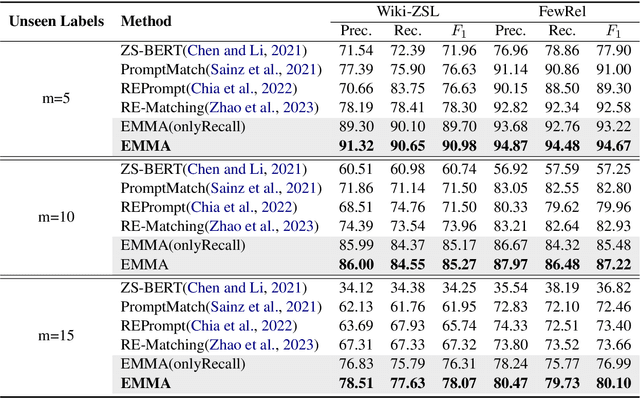
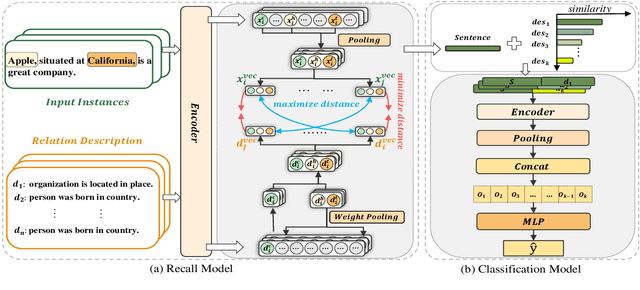
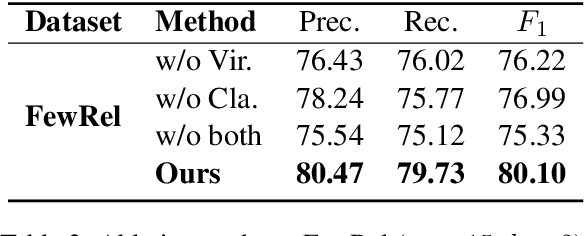
Predicting unseen relations that cannot be observed during the training phase is a challenging task in relation extraction. Previous works have made progress by matching the semantics between input instances and label descriptions. However, fine-grained matching often requires laborious manual annotation, and rich interactions between instances and label descriptions come with significant computational overhead. In this work, we propose an efficient multi-grained matching approach that uses virtual entity matching to reduce manual annotation cost, and fuses coarse-grained recall and fine-grained classification for rich interactions with guaranteed inference speed. Experimental results show that our approach outperforms the previous State Of The Art (SOTA) methods, and achieves a balance between inference efficiency and prediction accuracy in zero-shot relation extraction tasks. Our code is available at https://github.com/longls777/EMMA.
Noise-BERT: A Unified Perturbation-Robust Framework with Noise Alignment Pre-training for Noisy Slot Filling Task
Mar 06, 2024



In a realistic dialogue system, the input information from users is often subject to various types of input perturbations, which affects the slot-filling task. Although rule-based data augmentation methods have achieved satisfactory results, they fail to exhibit the desired generalization when faced with unknown noise disturbances. In this study, we address the challenges posed by input perturbations in slot filling by proposing Noise-BERT, a unified Perturbation-Robust Framework with Noise Alignment Pre-training. Our framework incorporates two Noise Alignment Pre-training tasks: Slot Masked Prediction and Sentence Noisiness Discrimination, aiming to guide the pre-trained language model in capturing accurate slot information and noise distribution. During fine-tuning, we employ a contrastive learning loss to enhance the semantic representation of entities and labels. Additionally, we introduce an adversarial attack training strategy to improve the model's robustness. Experimental results demonstrate the superiority of our proposed approach over state-of-the-art models, and further analysis confirms its effectiveness and generalization ability.
DemoNSF: A Multi-task Demonstration-based Generative Framework for Noisy Slot Filling Task
Oct 16, 2023Recently, prompt-based generative frameworks have shown impressive capabilities in sequence labeling tasks. However, in practical dialogue scenarios, relying solely on simplistic templates and traditional corpora presents a challenge for these methods in generalizing to unknown input perturbations. To address this gap, we propose a multi-task demonstration based generative framework for noisy slot filling, named DemoNSF. Specifically, we introduce three noisy auxiliary tasks, namely noisy recovery (NR), random mask (RM), and hybrid discrimination (HD), to implicitly capture semantic structural information of input perturbations at different granularities. In the downstream main task, we design a noisy demonstration construction strategy for the generative framework, which explicitly incorporates task-specific information and perturbed distribution during training and inference. Experiments on two benchmarks demonstrate that DemoNSF outperforms all baseline methods and achieves strong generalization. Further analysis provides empirical guidance for the practical application of generative frameworks. Our code is released at https://github.com/dongguanting/Demo-NSF.
Revisit Input Perturbation Problems for LLMs: A Unified Robustness Evaluation Framework for Noisy Slot Filling Task
Oct 10, 2023With the increasing capabilities of large language models (LLMs), these high-performance models have achieved state-of-the-art results on a wide range of natural language processing (NLP) tasks. However, the models' performance on commonly-used benchmark datasets often fails to accurately reflect their reliability and robustness when applied to real-world noisy data. To address these challenges, we propose a unified robustness evaluation framework based on the slot-filling task to systematically evaluate the dialogue understanding capability of LLMs in diverse input perturbation scenarios. Specifically, we construct a input perturbation evaluation dataset, Noise-LLM, which contains five types of single perturbation and four types of mixed perturbation data. Furthermore, we utilize a multi-level data augmentation method (character, word, and sentence levels) to construct a candidate data pool, and carefully design two ways of automatic task demonstration construction strategies (instance-level and entity-level) with various prompt templates. Our aim is to assess how well various robustness methods of LLMs perform in real-world noisy scenarios. The experiments have demonstrated that the current open-source LLMs generally achieve limited perturbation robustness performance. Based on these experimental observations, we make some forward-looking suggestions to fuel the research in this direction.
A Multi-Task Semantic Decomposition Framework with Task-specific Pre-training for Few-Shot NER
Aug 28, 2023
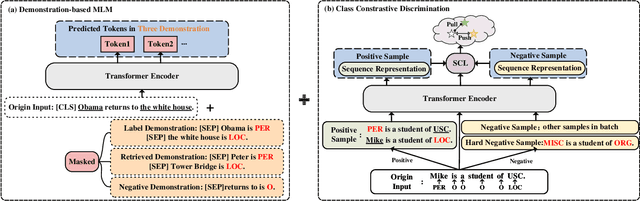

The objective of few-shot named entity recognition is to identify named entities with limited labeled instances. Previous works have primarily focused on optimizing the traditional token-wise classification framework, while neglecting the exploration of information based on NER data characteristics. To address this issue, we propose a Multi-Task Semantic Decomposition Framework via Joint Task-specific Pre-training (MSDP) for few-shot NER. Drawing inspiration from demonstration-based and contrastive learning, we introduce two novel pre-training tasks: Demonstration-based Masked Language Modeling (MLM) and Class Contrastive Discrimination. These tasks effectively incorporate entity boundary information and enhance entity representation in Pre-trained Language Models (PLMs). In the downstream main task, we introduce a multi-task joint optimization framework with the semantic decomposing method, which facilitates the model to integrate two different semantic information for entity classification. Experimental results of two few-shot NER benchmarks demonstrate that MSDP consistently outperforms strong baselines by a large margin. Extensive analyses validate the effectiveness and generalization of MSDP.
A Prototypical Semantic Decoupling Method via Joint Contrastive Learning for Few-Shot Name Entity Recognition
Feb 27, 2023



Few-shot named entity recognition (NER) aims at identifying named entities based on only few labeled instances. Most existing prototype-based sequence labeling models tend to memorize entity mentions which would be easily confused by close prototypes. In this paper, we proposed a Prototypical Semantic Decoupling method via joint Contrastive learning (PSDC) for few-shot NER. Specifically, we decouple class-specific prototypes and contextual semantic prototypes by two masking strategies to lead the model to focus on two different semantic information for inference. Besides, we further introduce joint contrastive learning objectives to better integrate two kinds of decoupling information and prevent semantic collapse. Experimental results on two few-shot NER benchmarks demonstrate that PSDC consistently outperforms the previous SOTA methods in terms of overall performance. Extensive analysis further validates the effectiveness and generalization of PSDC.
Revisit Out-Of-Vocabulary Problem for Slot Filling: A Unified Contrastive Frameword with Multi-level Data Augmentations
Feb 27, 2023In real dialogue scenarios, the existing slot filling model, which tends to memorize entity patterns, has a significantly reduced generalization facing Out-of-Vocabulary (OOV) problems. To address this issue, we propose an OOV robust slot filling model based on multi-level data augmentations to solve the OOV problem from both word and slot perspectives. We present a unified contrastive learning framework, which pull representations of the origin sample and augmentation samples together, to make the model resistant to OOV problems. We evaluate the performance of the model from some specific slots and carefully design test data with OOV word perturbation to further demonstrate the effectiveness of OOV words. Experiments on two datasets show that our approach outperforms the previous sota methods in terms of both OOV slots and words.
PSSAT: A Perturbed Semantic Structure Awareness Transferring Method for Perturbation-Robust Slot Filling
Aug 31, 2022
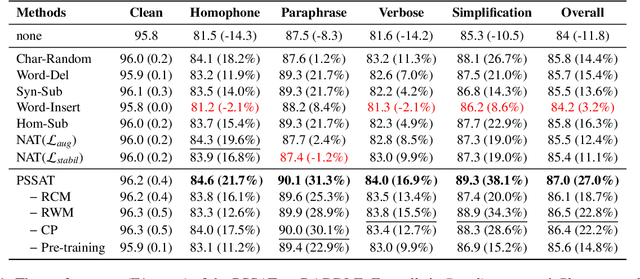
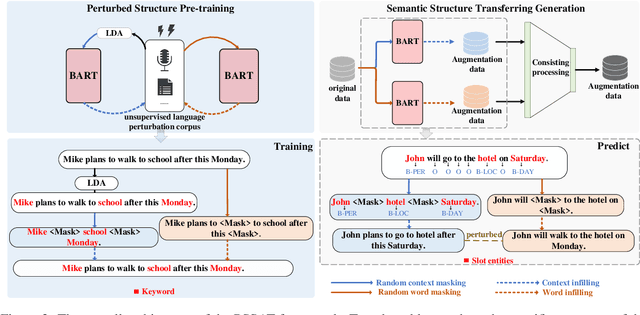
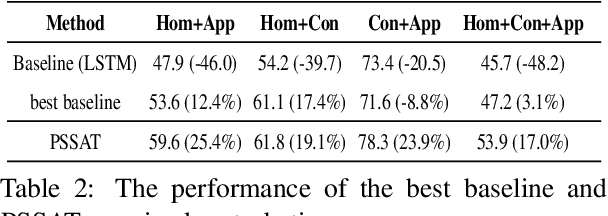
Most existing slot filling models tend to memorize inherent patterns of entities and corresponding contexts from training data. However, these models can lead to system failure or undesirable outputs when being exposed to spoken language perturbation or variation in practice. We propose a perturbed semantic structure awareness transferring method for training perturbation-robust slot filling models. Specifically, we introduce two MLM-based training strategies to respectively learn contextual semantic structure and word distribution from unsupervised language perturbation corpus. Then, we transfer semantic knowledge learned from upstream training procedure into the original samples and filter generated data by consistency processing. These procedures aim to enhance the robustness of slot filling models. Experimental results show that our method consistently outperforms the previous basic methods and gains strong generalization while preventing the model from memorizing inherent patterns of entities and contexts.