 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAIR: A Rule-Aware Benchmark Uniting Challenging Long-Tail and Visual Salience Subset for E-commerce Relevance Assessment
Dec 31, 2025Search relevance plays a central role in web e-commerce. While large language models (LLMs) have shown significant results on relevance task, existing benchmarks lack sufficient complexity for comprehensive model assessment, resulting in an absence of standardized relevance evaluation metrics across the industry. To address this limitation, we propose Rule-Aware benchmark with Image for Relevance assessment(RAIR), a Chinese dataset derived from real-world scenarios. RAIR established a standardized framework for relevance assessment and provides a set of universal rules, which forms the foundation for standardized evaluation. Additionally, RAIR analyzes essential capabilities required for current relevance models and introduces a comprehensive dataset consists of three subset: (1) a general subset with industry-balanced sampling to evaluate fundamental model competencies; (2) a long-tail hard subset focus on challenging cases to assess performance limits; (3) a visual salience subset for evaluating multimodal understanding capabilities. We conducted experiments on RAIR using 14 open and closed-source models. The results demonstrate that RAIR presents sufficient challenges even for GPT-5, which achieved the best performance. RAIR data are now available, serving as an industry benchmark for relevance assessment while providing new insights into general LLM and Visual Language Model(VLM) evaluation.
Explainable LLM-driven Multi-dimensional Distillation for E-Commerce Relevance Learning
Nov 20, 2024Effective query-item relevance modeling is pivotal for enhancing user experience and safeguarding user satisfaction in e-commerce search systems. Recently, benefiting from the vast inherent knowledge, Large Language Model (LLM) approach demonstrates strong performance and long-tail generalization ability compared with previous neural-based specialized relevance learning methods. Though promising, current LLM-based methods encounter the following inadequacies in practice: First, the massive parameters and computational demands make it difficult to be deployed online. Second, distilling LLM models to online models is a feasible direction, but the LLM relevance modeling is a black box, and its rich intrinsic knowledge is difficult to extract and apply online. To improve the interpretability of LLM and boost the performance of online relevance models via LLM, we propose an Explainable LLM-driven Multi-dimensional Distillation framework for e-commerce relevance learning, which comprises two core components: (1) An Explainable LLM for relevance modeling (ELLM-rele), which decomposes the relevance learning into intermediate steps and models relevance learning as a Chain-of-Thought (CoT) reasoning, thereby enhancing both interpretability and performance of LLM. (2) A Multi-dimensional Knowledge Distillation (MKD) architecture that transfers the knowledge of ELLM-rele to current deployable interaction-based and representation-based student models from both the relevance score distribution and CoT reasoning aspects. Through distilling the probabilistic and CoT reasoning knowledge, MKD improves both the semantic interaction and long-tail generalization abilities of student models. Extensive offline evaluations and online experiments on Taobao search ad scene demonstrate that our proposed framework significantly enhances e-commerce relevance learning performance and user experience.
Eliminating the Language Bias for Visual Question Answering with fine-grained Causal Intervention
Oct 14, 2024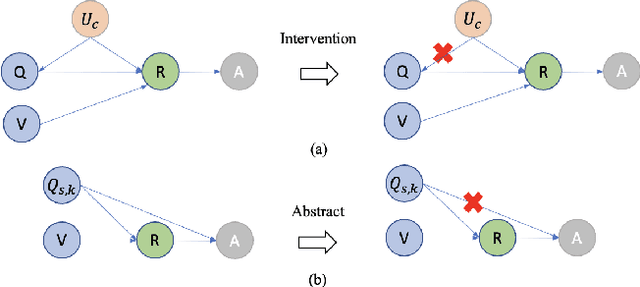
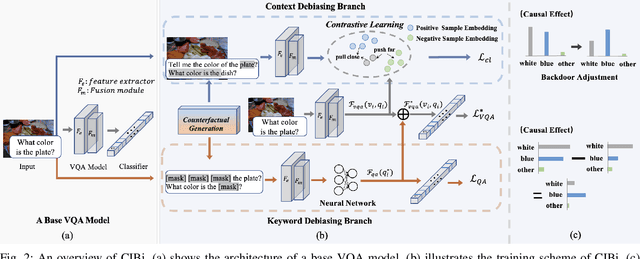
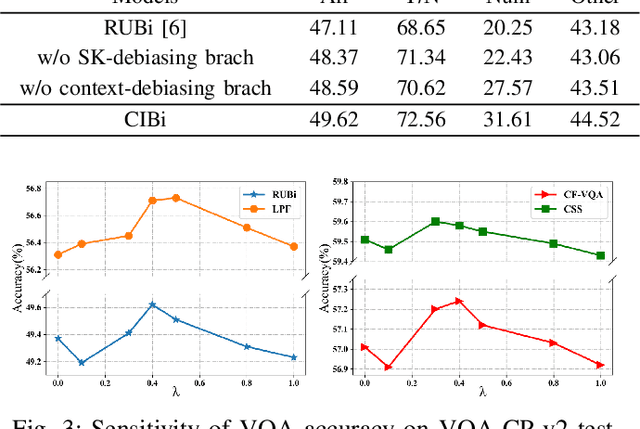
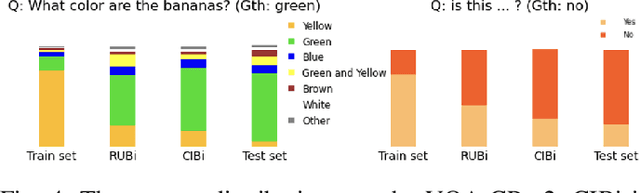
Despite the remarkable advancements in Visual Question Answering (VQA), the challenge of mitigating the language bias introduced by textual information remains unresolved. Previous approaches capture language bias from a coarse-grained perspective. However, the finer-grained information within a sentence, such as context and keywords, can result in different biases. Due to the ignorance of fine-grained information, most existing methods fail to sufficiently capture language bias. In this paper, we propose a novel causal intervention training scheme named CIBi to eliminate language bias from a finer-grained perspective. Specifically, we divide the language bias into context bias and keyword bias. We employ causal intervention and contrastive learning to eliminate context bias and improve the multi-modal representation. Additionally, we design a new question-only branch based on counterfactual generation to distill and eliminate keyword bias. Experimental results illustrate that CIBi is applicable to various VQA models, yielding competitive performance.
Fusion Makes Perfection: An Efficient Multi-Grained Matching Approach for Zero-Shot Relation Extraction
Jun 17, 2024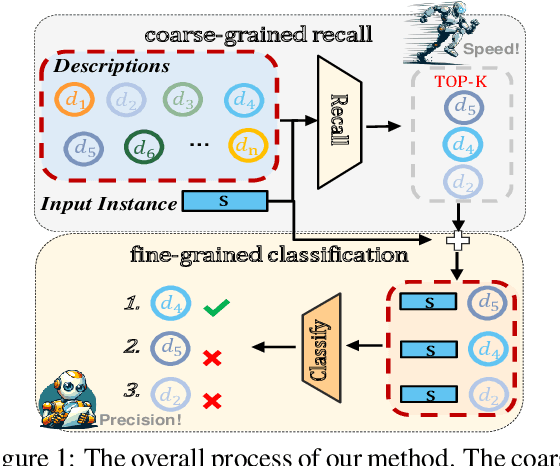
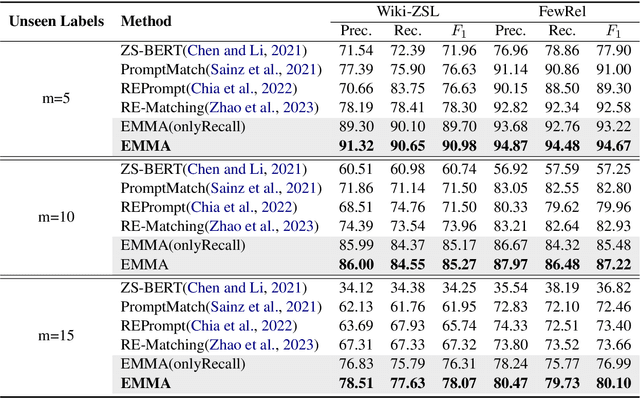
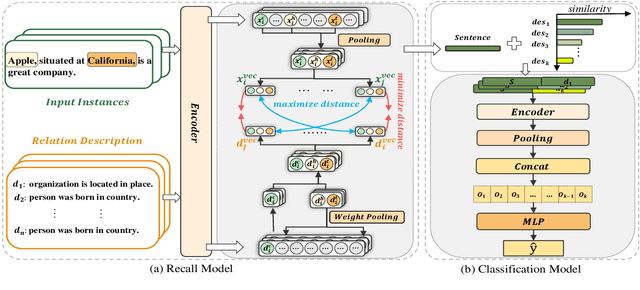
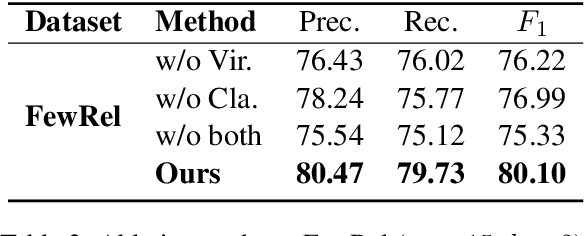
Predicting unseen relations that cannot be observed during the training phase is a challenging task in relation extraction. Previous works have made progress by matching the semantics between input instances and label descriptions. However, fine-grained matching often requires laborious manual annotation, and rich interactions between instances and label descriptions come with significant computational overhead. In this work, we propose an efficient multi-grained matching approach that uses virtual entity matching to reduce manual annotation cost, and fuses coarse-grained recall and fine-grained classification for rich interactions with guaranteed inference speed. Experimental results show that our approach outperforms the previous State Of The Art (SOTA) methods, and achieves a balance between inference efficiency and prediction accuracy in zero-shot relation extraction tasks. Our code is available at https://github.com/longls777/EMMA.