 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliminating the Language Bias for Visual Question Answering with fine-grained Causal Intervention
Oct 14, 2024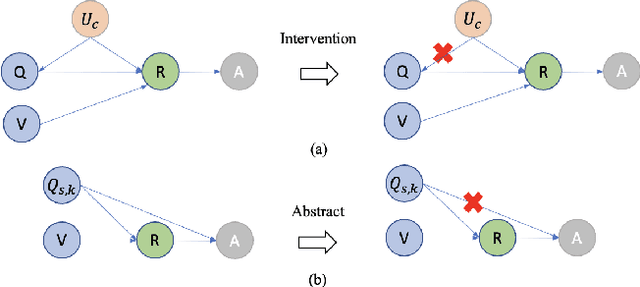
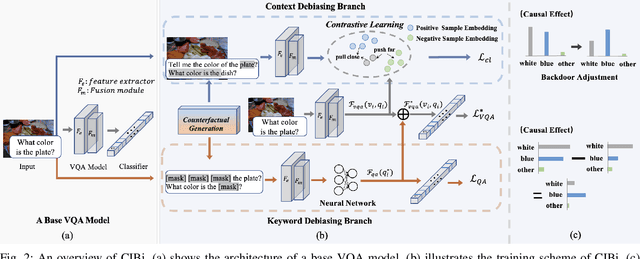
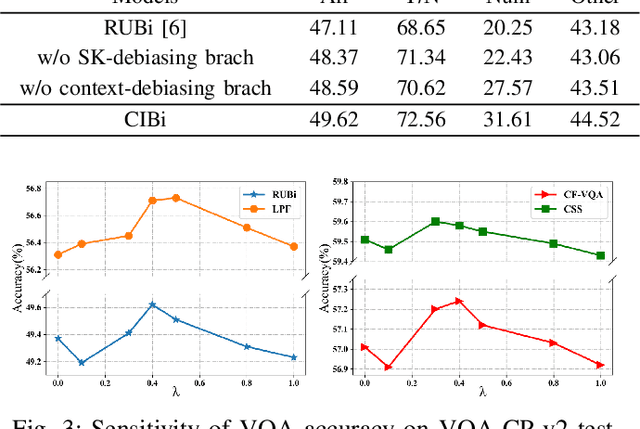
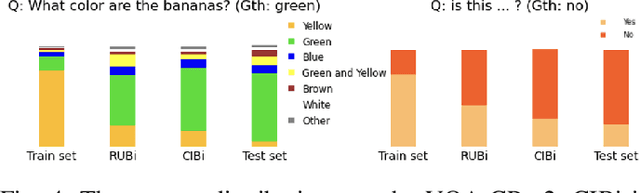
Despite the remarkable advancements in Visual Question Answering (VQA), the challenge of mitigating the language bias introduced by textual information remains unresolved. Previous approaches capture language bias from a coarse-grained perspective. However, the finer-grained information within a sentence, such as context and keywords, can result in different biases. Due to the ignorance of fine-grained information, most existing methods fail to sufficiently capture language bias. In this paper, we propose a novel causal intervention training scheme named CIBi to eliminate language bias from a finer-grained perspective. Specifically, we divide the language bias into context bias and keyword bias. We employ causal intervention and contrastive learning to eliminate context bias and improve the multi-modal representation. Additionally, we design a new question-only branch based on counterfactual generation to distill and eliminate keyword bias. Experimental results illustrate that CIBi is applicable to various VQA models, yielding competitive performance.
GraphReader: Building Graph-based Agent to Enhance Long-Context Abilities of Large Language Models
Jun 20, 2024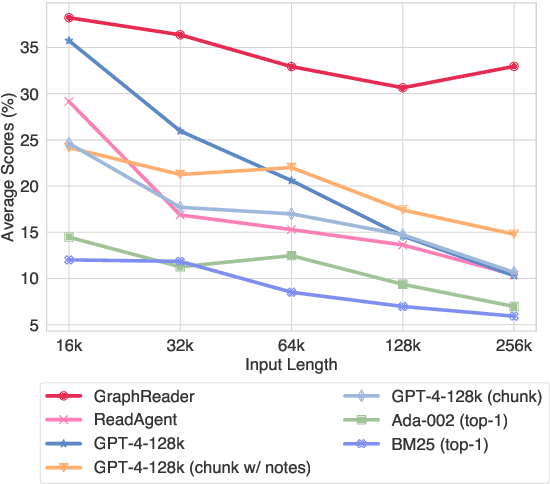
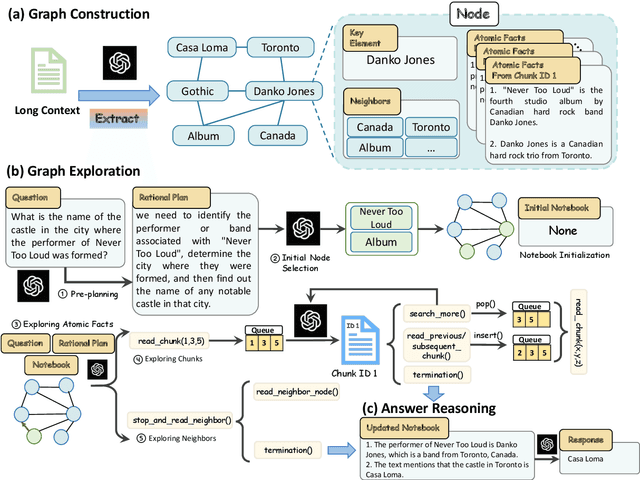
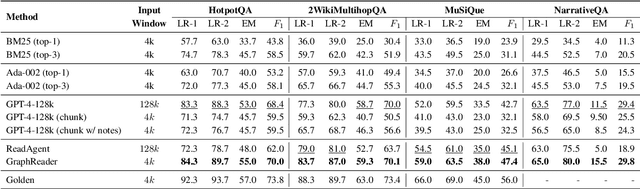
Long-context capabilities are essential for large language models (LLMs) to tackle complex and long-input tasks. Despite numerous efforts made to optimize LLMs for long contexts, challenges persist in robustly processing long inputs. In this paper, we introduce GraphReader, a graph-based agent system designed to handle long texts by structuring them into a graph and employing an agent to explore this graph autonomously. Upon receiving a question, the agent first undertakes a step-by-step analysis and devises a rational plan. It then invokes a set of predefined functions to read node content and neighbors, facilitating a coarse-to-fine exploration of the graph. Throughout the exploration, the agent continuously records new insights and reflects on current circumstances to optimize the process until it has gathered sufficient information to generate an answer. Experimental results on the LV-Eval dataset reveal that GraphReader, using a 4k context window, consistently outperforms GPT-4-128k across context lengths from 16k to 256k by a large margin. Additionally, our approach demonstrates superior performance on four challenging single-hop and multi-hop benchmarks.
Fusion Makes Perfection: An Efficient Multi-Grained Matching Approach for Zero-Shot Relation Extraction
Jun 17, 2024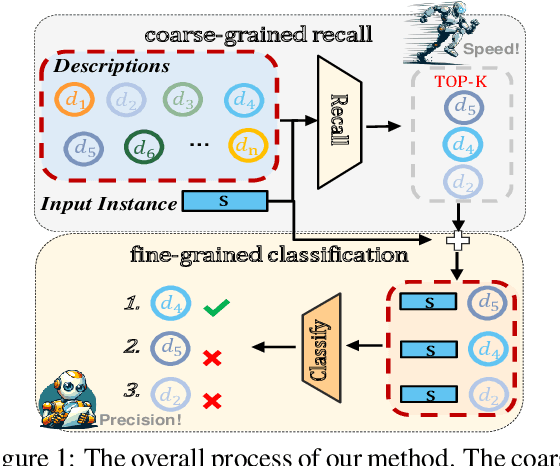
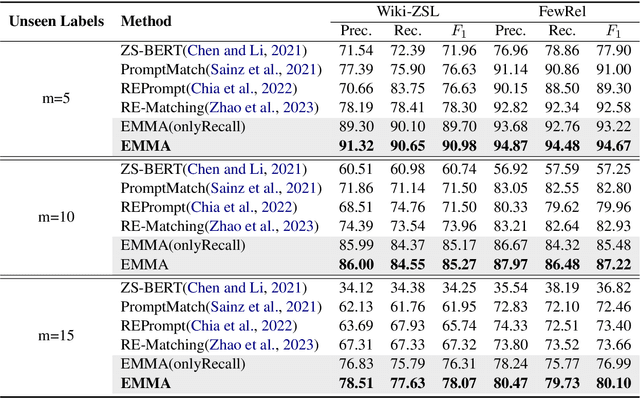
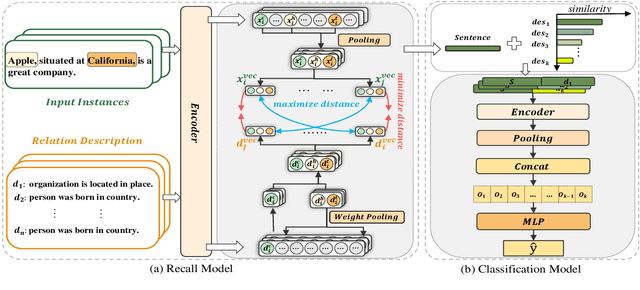
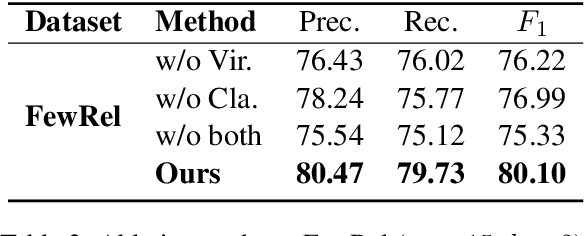
Predicting unseen relations that cannot be observed during the training phase is a challenging task in relation extraction. Previous works have made progress by matching the semantics between input instances and label descriptions. However, fine-grained matching often requires laborious manual annotation, and rich interactions between instances and label descriptions come with significant computational overhead. In this work, we propose an efficient multi-grained matching approach that uses virtual entity matching to reduce manual annotation cost, and fuses coarse-grained recall and fine-grained classification for rich interactions with guaranteed inference speed. Experimental results show that our approach outperforms the previous State Of The Art (SOTA) methods, and achieves a balance between inference efficiency and prediction accuracy in zero-shot relation extraction tasks. Our code is available at https://github.com/longls777/EMMA.
MT-Bench-101: A Fine-Grained Benchmark for Evaluating Large Language Models in Multi-Turn Dialogues
Feb 22, 2024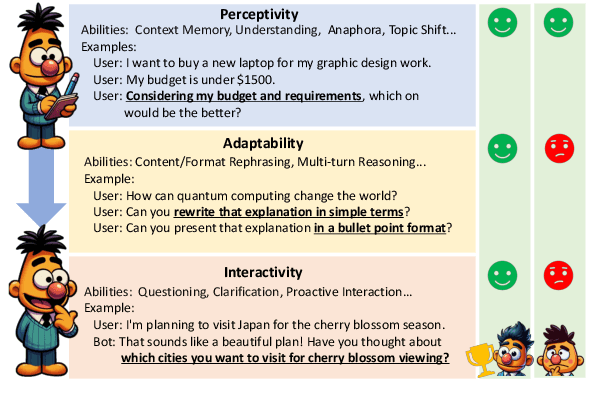

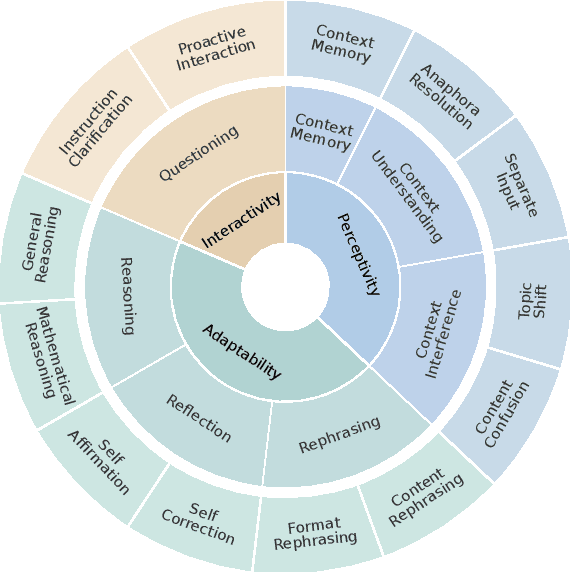
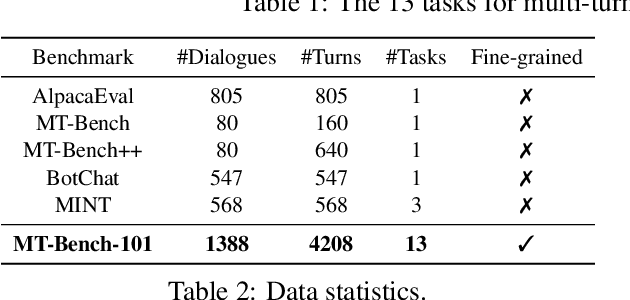
The advent of Large Language Models (LLMs) has drastically enhanced dialogue systems. However, comprehensively evaluating the dialogue abilities of LLMs remains a challenge. Previous benchmarks have primarily focused on single-turn dialogues or provided coarse-grained and incomplete assessments of multi-turn dialogues, overlooking the complexity and fine-grained nuances of real-life dialogues. To address this issue, we introduce MT-Bench-101, specifically designed to evaluate the fine-grained abilities of LLMs in multi-turn dialogues. By conducting a detailed analysis of real multi-turn dialogue data, we construct a three-tier hierarchical ability taxonomy comprising 4208 turns across 1388 multi-turn dialogues in 13 distinct tasks. We then evaluate 21 popular LLMs based on MT-Bench-101, conducting comprehensive analyses from both ability and task perspectives and observing differing trends in LLMs performance across dialogue turns within various tasks. Further analysis indicates that neither utilizing common alignment techniques nor chat-specific designs has led to obvious enhancements in the multi-turn abilities of LLMs. Extensive case studies suggest that our designed tasks accurately assess the corresponding multi-turn abilities.
A Data-Driven Approach to Quantum Cross-Platform Verification
Nov 03, 2022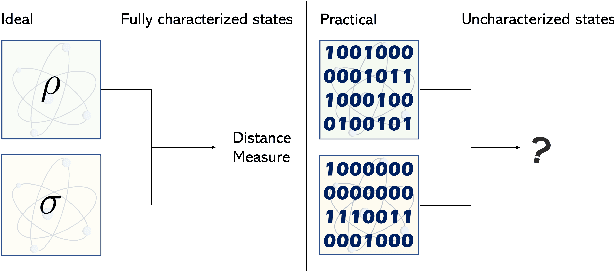
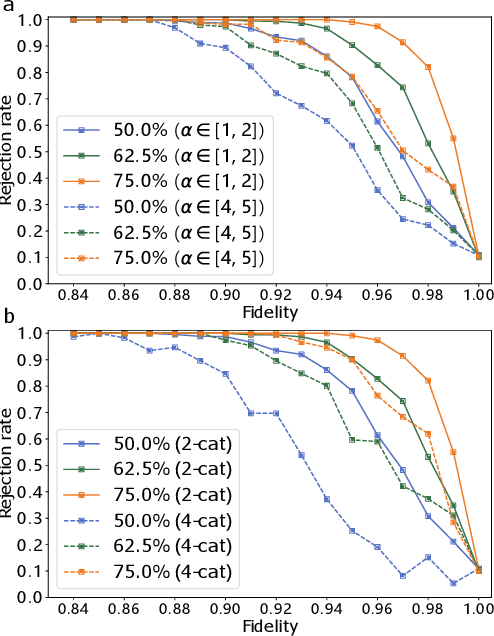
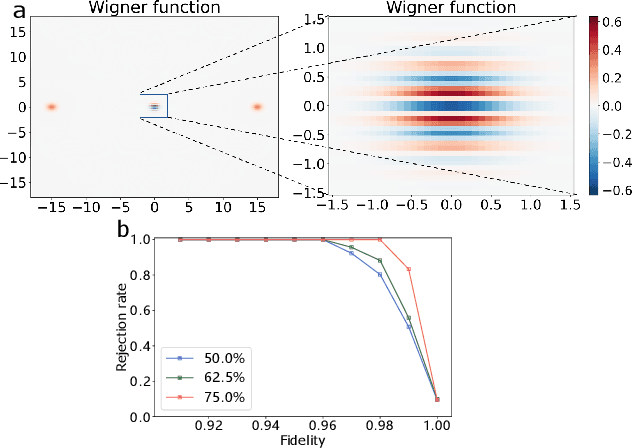
The task of testing whether two uncharacterized devices behave in the same way, known as cross-platform verification, is crucial for benchmarking quantum simulators and near-term quantum computers. Cross-platform verification becomes increasingly challenging as the system's dimensionality increases, and has so far remained intractable for continuous variable quantum systems. In this Letter, we develop a data-driven approach, working with limited noisy data and suitable for continuous variable quantum states. Our approach is based on a convolutional neural network that assesses the similarity of quantum states based on a lower-dimensional state representation built from measurement data. The network can be trained offline with classically simulated data, and is demonstrated here on non-Gaussian quantum states for which cross-platform verification could not be achieved with previous techniques. It can also be applied to cross-platform verification of quantum dynamics and to the problem of experimentally testing whether two quantum states are equivalent up to Gaussian unitary transformations.
Flexible learning of quantum states with generative query neural networks
Feb 14, 2022
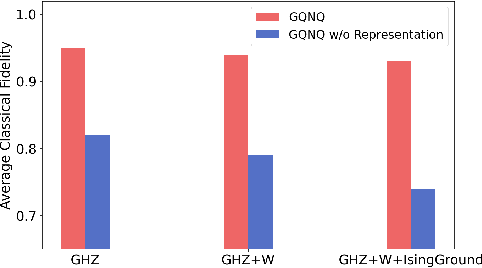
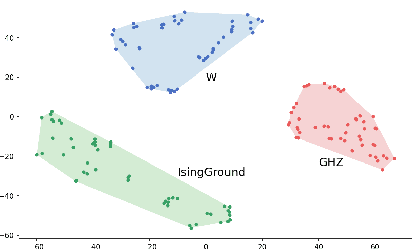
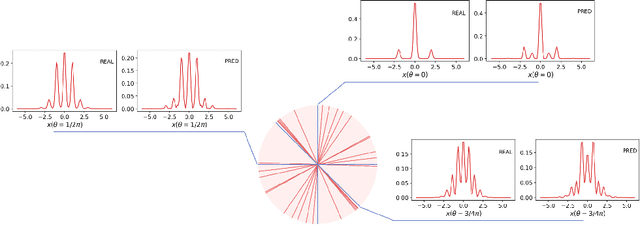
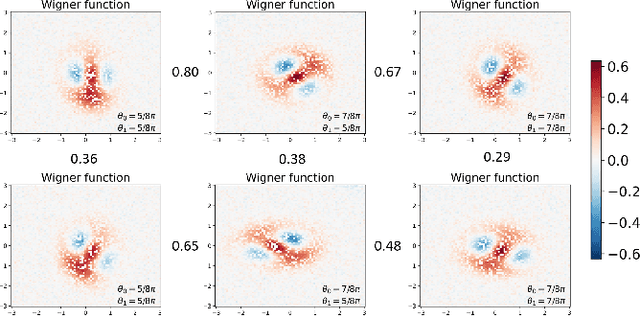
Deep neural networks are a powerful tool for characterizing quantum states. In this task, neural networks are typically trained with measurement data gathered from the quantum state to be characterized. But is it possible to train a neural network in a general-purpose way, which makes it applicable to multiple unknown quantum states? Here we show that learning across multiple quantum states and different measurement settings can be achieved by a generative query neural network, a type of neural network originally used in the classical domain for learning 3D scenes from 2D pictures. Our network can be trained offline with classically simulated data, and later be used to characterize unknown quantum states from real experimental data. With little guidance of quantum physics, the network builds its own data-driven representation of quantum states, and then uses it to predict the outcome probabilities of requested quantum measurements on the states of interest. This approach can be applied to state learning scenarios where quantum measurement settings are not informationally complete and predictions must be given in real time, as experimental data become available, as well as to adversarial scenarios where measurement choices and prediction requests are designed to expose learning inaccuracies. The internal representation produced by the network can be used for other tasks beyond state characterization, including clustering of states and prediction of physical properties. The features of our method are illustrated on many-qubit ground states of Ising model and continuous-variable non-Gaussian states.