 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT-Bench-101: A Fine-Grained Benchmark for Evaluating Large Language Models in Multi-Turn Dialogues
Paper and Code
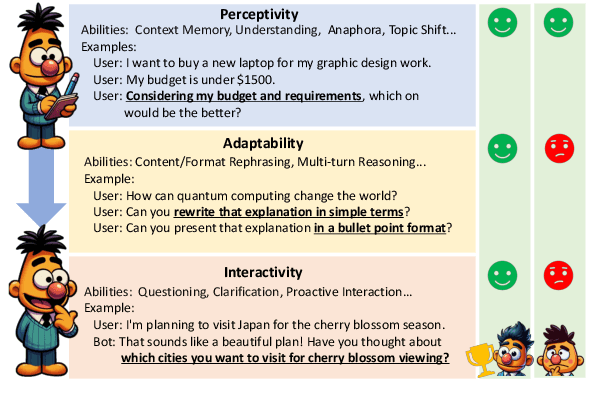

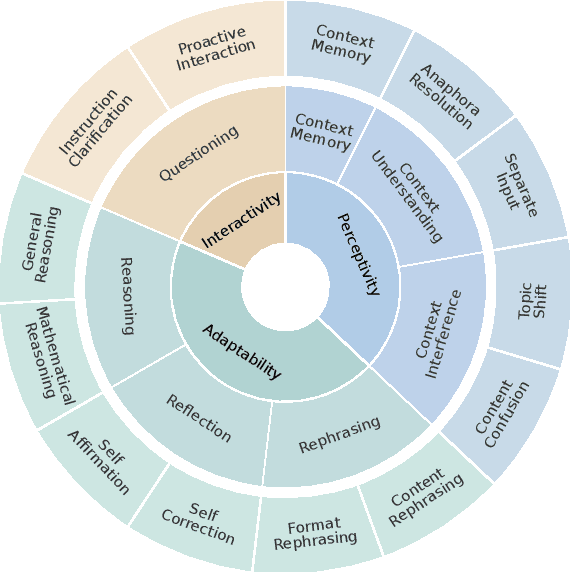
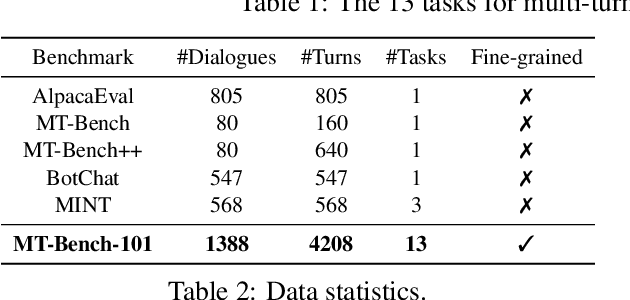
The advent of Large Language Models (LLMs) has drastically enhanced dialogue systems. However, comprehensively evaluating the dialogue abilities of LLMs remains a challenge. Previous benchmarks have primarily focused on single-turn dialogues or provided coarse-grained and incomplete assessments of multi-turn dialogues, overlooking the complexity and fine-grained nuances of real-life dialogues. To address this issue, we introduce MT-Bench-101, specifically designed to evaluate the fine-grained abilities of LLMs in multi-turn dialogues. By conducting a detailed analysis of real multi-turn dialogue data, we construct a three-tier hierarchical ability taxonomy comprising 4208 turns across 1388 multi-turn dialogues in 13 distinct tasks. We then evaluate 21 popular LLMs based on MT-Bench-101, conducting comprehensive analyses from both ability and task perspectives and observing differing trends in LLMs performance across dialogue turns within various tasks. Further analysis indicates that neither utilizing common alignment techniques nor chat-specific designs has led to obvious enhancements in the multi-turn abilities of LLMs. Extensive case studies suggest that our designed tasks accurately assess the corresponding multi-turn abilities.