 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Do Models Follow Visual Instructions? VIBE: A Systematic Benchmark for Visual Instruction-Driven Image Editing
Feb 02, 2026Recent generative models have achieved remarkable progress in image editing. However, existing systems and benchmarks remain largely text-guided. In contrast, human communication is inherently multimodal, where visual instructions such as sketches efficiently convey spatial and structural intent. To address this gap, we introduce VIBE, the Visual Instruction Benchmark for Image Editing with a three-level interaction hierarchy that captures deictic grounding, morphological manipulation, and causal reasoning. Across these levels, we curate high-quality and diverse test cases that reflect progressively increasing complexity in visual instruction following. We further propose a robust LMM-as-a-judge evaluation framework with task-specific metrics to enable scalable and fine-grained assessment. Through a comprehensive evaluation of 17 representative open-source and proprietary image editing models, we find that proprietary models exhibit early-stage visual instruction-following capabilities and consistently outperform open-source models. However, performance degrades markedly with increasing task difficulty even for the strongest systems, highlighting promising directions for future research.
ShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
AdaptEval: A Benchmark for Evaluating Large Language Models on Code Snippet Adaptation
Jan 08, 2026Recent advancements in large language models (LLMs) have automated various software engineering tasks, with benchmarks emerging to evaluate their capabilities. However, for adaptation, a critical activity during code reuse, there is no benchmark to assess LLMs' performance, leaving their practical utility in this area unclear. To fill this gap, we propose AdaptEval, a benchmark designed to evaluate LLMs on code snippet adaptation. Unlike existing benchmarks, AdaptEval incorporates the following three distinctive features: First, Practical Context. Tasks in AdaptEval are derived from developers' practices, preserving rich contextual information from Stack Overflow and GitHub communities. Second, Multi-granularity Annotation. Each task is annotated with requirements at both task and adaptation levels, supporting the evaluation of LLMs across diverse adaptation scenarios. Third, Fine-grained Evaluation. AdaptEval includes a two-tier testing framework combining adaptation-level and function-level tests, which enables evaluating LLMs' performance across various individual adaptations. Based on AdaptEval, we conduct the first empirical study to evaluate six instruction-tuned LLMs and especially three reasoning LLMs on code snippet adaptation. Experimental results demonstrate that AdaptEval enables the assessment of LLMs' adaptation capabilities from various perspectives. It also provides critical insights into their current limitations, particularly their struggle to follow explicit instructions. We hope AdaptEval can facilitate further investigation and enhancement of LLMs' capabilities in code snippet adaptation, supporting their real-world applications.
Luminark: Training-free, Probabilistically-Certified Watermarking for General Vision Generative Models
Jan 03, 2026In this paper, we introduce \emph{Luminark}, a training-free and probabilistically-certified watermarking method for general vision generative models. Our approach is built upon a novel watermark definition that leverages patch-level luminance statistics. Specifically, the service provider predefines a binary pattern together with corresponding patch-level thresholds. To detect a watermark in a given image, we evaluate whether the luminance of each patch surpasses its threshold and then verify whether the resulting binary pattern aligns with the target one. A simple statistical analysis demonstrates that the false positive rate of the proposed method can be effectively controlled, thereby ensuring certified detection. To enable seamless watermark injection across different paradigms, we leverage the widely adopted guidance technique as a plug-and-play mechanism and develop the \emph{watermark guidance}. This design enables Luminark to achieve generality across state-of-the-art generative models without compromising image quality. Empirically, we evaluate our approach on nine models spanning diffusion, autoregressive, and hybrid frameworks. Across all evaluations, Luminark consistently demonstrates high detection accuracy, strong robustness against common image transformations, and good performance on visual quality.
E-GRPO: High Entropy Steps Drive Effective Reinforcement Learning for Flow Models
Jan 01, 2026Recent reinforcement learning has enhanced the flow matching models on human preference alignment. While stochastic sampling enables the exploration of denoising directions, existing methods which optimize over multiple denoising steps suffer from sparse and ambiguous reward signals. We observe that the high entropy steps enable more efficient and effective exploration while the low entropy steps result in undistinguished roll-outs. To this end, we propose E-GRPO, an entropy aware Group Relative Policy Optimization to increase the entropy of SDE sampling steps. Since the integration of stochastic differential equations suffer from ambiguous reward signals due to stochasticity from multiple steps, we specifically merge consecutive low entropy steps to formulate one high entropy step for SDE sampling, while applying ODE sampling on other steps. Building upon this, we introduce multi-step group normalized advantage, which computes group-relative advantages within samples sharing the same consolidated SDE denoising step. Experimental results on different reward settings have demonstrated the effectiveness of our methods.
SportsGPT: An LLM-driven Framework for Interpretable Sports Motion Assessment and Training Guidance
Dec 19, 2025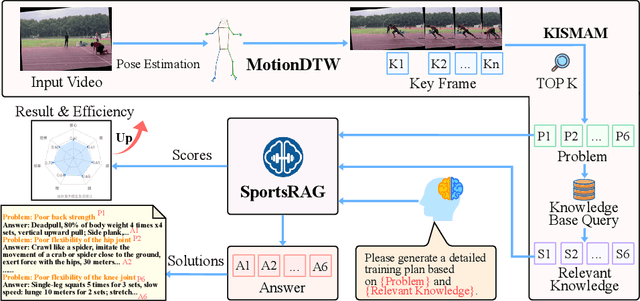
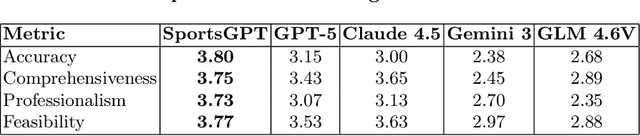
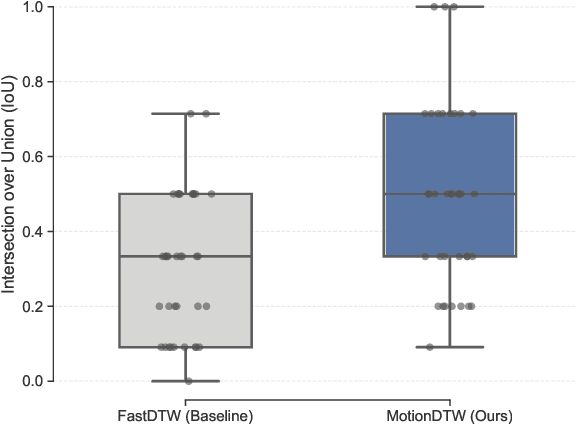

Existing intelligent sports analysis systems mainly focus on "scoring and visualization," often lacking automatic performance diagnosis and interpretable training guidance. Recent advances in Large Language Models (LLMs) and motion analysis techniques provide new opportunities to address the above limitations. In this paper, we propose SportsGPT, an LLM-driven framework for interpretable sports motion assessment and training guidance, which establishes a closed loop from motion time-series input to professional training guidance. First, given a set of high-quality target models, we introduce MotionDTW, a two-stage time series alignment algorithm designed for accurate keyframe extraction from skeleton-based motion sequences. Subsequently, we design a Knowledge-based Interpretable Sports Motion Assessment Model (KISMAM) to obtain a set of interpretable assessment metrics (e.g., insufficient extension) by contrasting the keyframes with the target models. Finally, we propose SportsRAG, a RAG-based training guidance model built upon Qwen3. Leveraging a 6B-token knowledge base, it prompts the LLM to generate professional training guidance by retrieving domain-specific QA pairs. Experimental results demonstrate that MotionDTW significantly outperforms traditional methods with lower temporal error and higher IoU scores. Furthermore, ablation studies validate the KISMAM and SportsRAG, confirming that SportsGPT surpasses general LLMs in diagnostic accuracy and professionalism.
HeatV2X: Scalable Heterogeneous Collaborative Perception via Efficient Alignment and Interaction
Nov 13, 2025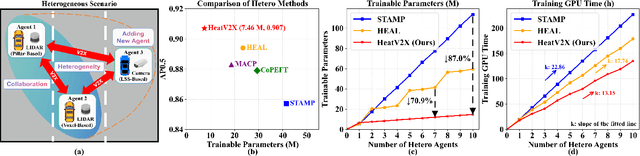
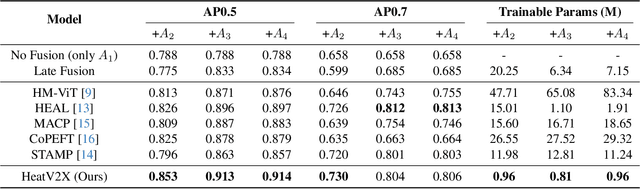
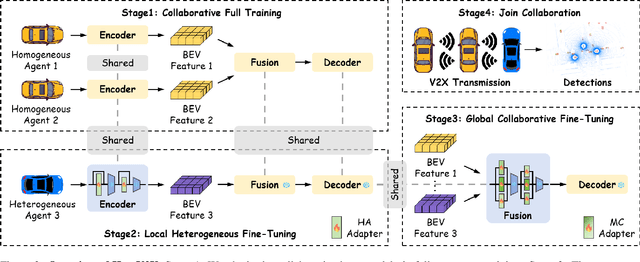
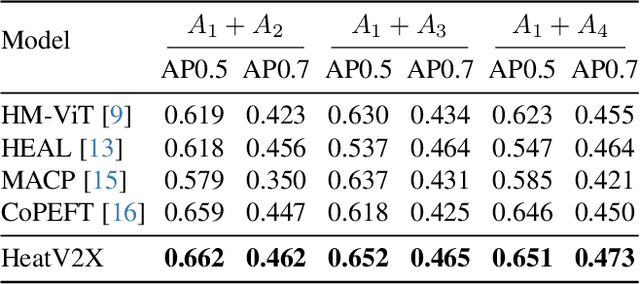
Vehicle-to-Everything (V2X) collaborative perception extends sensing beyond single vehicle limits through transmission. However, as more agents participate, existing frameworks face two key challenges: (1) the participating agents are inherently multi-modal and heterogeneous, and (2) the collaborative framework must be scalable to accommodate new agents. The former requires effective cross-agent feature alignment to mitigate heterogeneity loss, while the latter renders full-parameter training impractical, highlighting the importance of scalable adaptation. To address these issues, we propose Heterogeneous Adaptation (HeatV2X), a scalable collaborative framework. We first train a high-performance agent based on heterogeneous graph attention as the foundation for collaborative learning. Then, we design Local Heterogeneous Fine-Tuning and Global Collaborative Fine-Tuning to achieve effective alignment and interaction among heterogeneous agents. The former efficiently extracts modality-specific differences using Hetero-Aware Adapters, while the latter employs the Multi-Cognitive Adapter to enhance cross-agent collaboration and fully exploit the fusion potential. These designs enable substantial performance improvement of the collaborative framework with minimal training cost. We evaluate our approach on the OPV2V-H and DAIR-V2X datasets. Experimental results demonstrate that our method achieves superior perception performance with significantly reduced training overhead, outperforming existing state-of-the-art approaches. Our implementation will be released soon.
BaseReward: A Strong Baseline for Multimodal Reward Model
Sep 19, 2025



The rapid advancement of Multimodal Large Language Models (MLLMs) has made aligning them with human preferences a critical challenge. Reward Models (RMs) are a core technology for achieving this goal, but a systematic guide for building state-of-the-art Multimodal Reward Models (MRMs) is currently lacking in both academia and industry. Through exhaustive experimental analysis, this paper aims to provide a clear ``recipe'' for constructing high-performance MRMs. We systematically investigate every crucial component in the MRM development pipeline, including \textit{reward modeling paradigms} (e.g., Naive-RM, Critic-based RM, and Generative RM), \textit{reward head architecture}, \textit{training strategies}, \textit{data curation} (covering over ten multimodal and text-only preference datasets), \textit{backbone model} and \textit{model scale}, and \textit{ensemble methods}. Based on these experimental insights, we introduce \textbf{BaseReward}, a powerful and efficient baseline for multimodal reward modeling. BaseReward adopts a simple yet effective architecture, built upon a {Qwen2.5-VL} backbone, featuring an optimized two-layer reward head, and is trained on a carefully curated mixture of high-quality multimodal and text-only preference data. Our results show that BaseReward establishes a new SOTA on major benchmarks such as MM-RLHF-Reward Bench, VL-Reward Bench, and Multimodal Reward Bench, outperforming previous models. Furthermore, to validate its practical utility beyond static benchmarks, we integrate BaseReward into a real-world reinforcement learning pipeline, successfully enhancing an MLLM's performance across various perception, reasoning, and conversational tasks. This work not only delivers a top-tier MRM but, more importantly, provides the community with a clear, empirically-backed guide for developing robust reward models for the next generation of MLLMs.
Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots
Jul 27, 2025Humanoid robot technology is advancing rapidly, with manufacturers introducing diverse heterogeneous visual perception modules tailored to specific scenarios. Among various perception paradigms, occupancy-based representation has become widely recognized as particularly suitable for humanoid robots, as it provides both rich semantic and 3D geometric information essential for comprehensive environmental understanding. In this work, we present Humanoid Occupancy, a generalized multimodal occupancy perception system that integrates hardware and software components, data acquisition devices, and a dedicated annotation pipeline. Our framework employs advanced multi-modal fusion techniques to generate grid-based occupancy outputs encoding both occupancy status and semantic labels, thereby enabling holistic environmental understanding for downstream tasks such as task planning and navigation. To address the unique challenges of humanoid robots, we overcome issues such as kinematic interference and occlusion, and establish an effective sensor layout strategy. Furthermore, we have developed the first panoramic occupancy dataset specifically for humanoid robots, offering a valuable benchmark and resource for future research and development in this domain. The network architecture incorporates multi-modal feature fusion and temporal information integration to ensure robust perception. Overall, Humanoid Occupancy delivers effective environmental perception for humanoid robots and establishes a technical foundation for standardizing universal visual modules, paving the way for the widespread deployment of humanoid robots in complex real-world scenarios.
Patho-R1: A Multimodal Reinforcement Learning-Based Pathology Expert Reasoner
May 16, 2025



Recent advances in vision language models (VLMs) have enabled broad progress in the general medical field. However, pathology still remains a more challenging subdomain, with current pathology specific VLMs exhibiting limitations in both diagnostic accuracy and reasoning plausibility. Such shortcomings are largely attributable to the nature of current pathology datasets, which are primarily composed of image description pairs that lack the depth and structured diagnostic paradigms employed by real world pathologists. In this study, we leverage pathology textbooks and real world pathology experts to construct high-quality, reasoning-oriented datasets. Building on this, we introduce Patho-R1, a multimodal RL-based pathology Reasoner, trained through a three-stage pipeline: (1) continued pretraining on 3.5 million image-text pairs for knowledge infusion; (2) supervised fine-tuning on 500k high-quality Chain-of-Thought samples for reasoning incentivizing; (3) reinforcement learning using Group Relative Policy Optimization and Decoupled Clip and Dynamic sAmpling Policy Optimization strategies for multimodal reasoning quality refinement. To further assess the alignment quality of our dataset, we propose PathoCLIP, trained on the same figure-caption corpus used for continued pretraining. Comprehensive experimental results demonstrate that both PathoCLIP and Patho-R1 achieve robust performance across a wide range of pathology-related tasks, including zero-shot classification, cross-modal retrieval, Visual Question Answering, and Multiple Choice Question. Our project is available at the Patho-R1 repository: https://github.com/Wenchuan-Zhang/Patho-R1.