 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoding in a Bubble? Evaluating LLMs in Resolving Context Adaptation Bugs During Code Adaptation
Jan 10, 2026Code adaptation is a fundamental but challenging task in software development, requiring developers to modify existing code for new contexts. A key challenge is to resolve Context Adaptation Bugs (CtxBugs), which occurs when code correct in its original context violates constraints in the target environment. Unlike isolated bugs, CtxBugs cannot be resolved through local fixes and require cross-context reasoning to identify semantic mismatches. Overlooking them may lead to critical failures in adaptation. Although Large Language Models (LLMs) show great potential in automating code-related tasks, their ability to resolve CtxBugs remains a significant and unexplored obstacle to their practical use in code adaptation. To bridge this gap, we propose CtxBugGen, a novel framework for generating CtxBugs to evaluate LLMs. Its core idea is to leverage LLMs' tendency to generate plausible but context-free code when contextual constraints are absent. The framework generates CtxBugs through a four-step process to ensure their relevance and validity: (1) Adaptation Task Selection, (2) Task-specific Perturbation,(3) LLM-based Variant Generation and (4) CtxBugs Identification. Based on the benchmark constructed by CtxBugGen, we conduct an empirical study with four state-of-the-art LLMs. Our results reveal their unsatisfactory performance in CtxBug resolution. The best performing LLM, Kimi-K2, achieves 55.93% on Pass@1 and resolves just 52.47% of CtxBugs. The presence of CtxBugs degrades LLMs' adaptation performance by up to 30%. Failure analysis indicates that LLMs often overlook CtxBugs and replicate them in their outputs. Our study highlights a critical weakness in LLMs' cross-context reasoning and emphasize the need for new methods to enhance their context awareness for reliable code adaptation.
AdaptEval: A Benchmark for Evaluating Large Language Models on Code Snippet Adaptation
Jan 08, 2026Recent advancements in large language models (LLMs) have automated various software engineering tasks, with benchmarks emerging to evaluate their capabilities. However, for adaptation, a critical activity during code reuse, there is no benchmark to assess LLMs' performance, leaving their practical utility in this area unclear. To fill this gap, we propose AdaptEval, a benchmark designed to evaluate LLMs on code snippet adaptation. Unlike existing benchmarks, AdaptEval incorporates the following three distinctive features: First, Practical Context. Tasks in AdaptEval are derived from developers' practices, preserving rich contextual information from Stack Overflow and GitHub communities. Second, Multi-granularity Annotation. Each task is annotated with requirements at both task and adaptation levels, supporting the evaluation of LLMs across diverse adaptation scenarios. Third, Fine-grained Evaluation. AdaptEval includes a two-tier testing framework combining adaptation-level and function-level tests, which enables evaluating LLMs' performance across various individual adaptations. Based on AdaptEval, we conduct the first empirical study to evaluate six instruction-tuned LLMs and especially three reasoning LLMs on code snippet adaptation. Experimental results demonstrate that AdaptEval enables the assessment of LLMs' adaptation capabilities from various perspectives. It also provides critical insights into their current limitations, particularly their struggle to follow explicit instructions. We hope AdaptEval can facilitate further investigation and enhancement of LLMs' capabilities in code snippet adaptation, supporting their real-world applications.
Large Language Models are Qualified Benchmark Builders: Rebuilding Pre-Training Datasets for Advancing Code Intelligence Tasks
Apr 28, 2025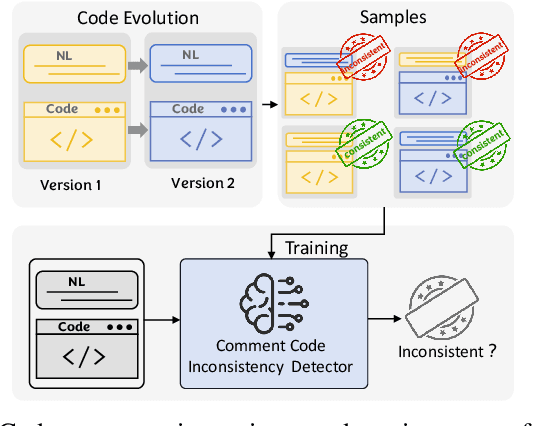
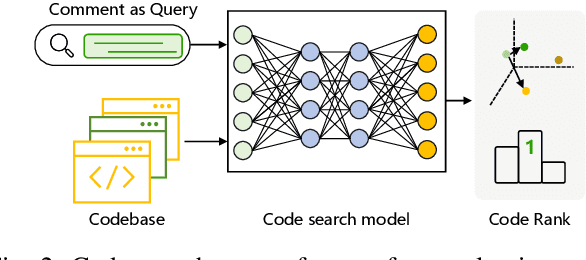

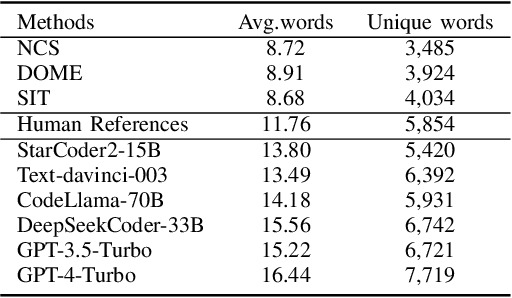
Pre-trained code models rely heavily on high-quality pre-training data, particularly human-written reference comments that bridge code and natural language. However, these comments often become outdated as software evolves, degrading model performance. Large language models (LLMs) excel at generating high-quality code comments. We investigate whether replacing human-written comments with LLM-generated ones improves pre-training datasets. Since standard metrics cannot assess reference comment quality, we propose two novel reference-free evaluation tasks: code-comment inconsistency detection and semantic code search. Results show that LLM-generated comments are more semantically consistent with code than human-written ones, as confirmed by manual evaluation. Leveraging this finding, we rebuild the CodeSearchNet dataset with LLM-generated comments and re-pre-train CodeT5. Evaluations demonstrate that models trained on LLM-enhanced data outperform those using original human comments in code summarization, generation, and translation tasks. This work validates rebuilding pre-training datasets with LLMs to advance code intelligence, challenging the traditional reliance on human reference comments.
Instruct or Interact? Exploring and Eliciting LLMs' Capability in Code Snippet Adaptation Through Prompt Engineering
Nov 23, 2024
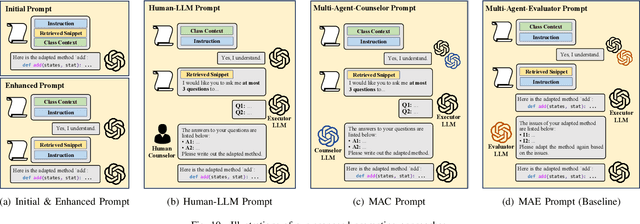
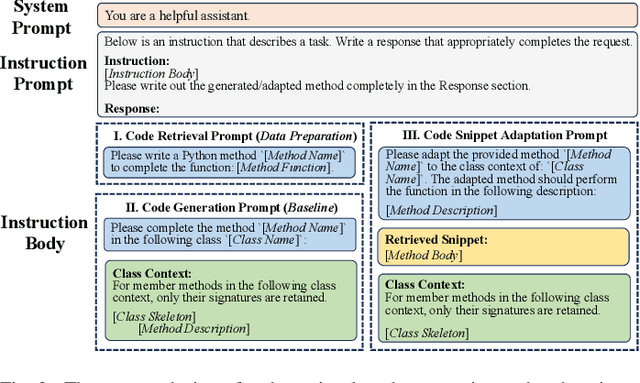
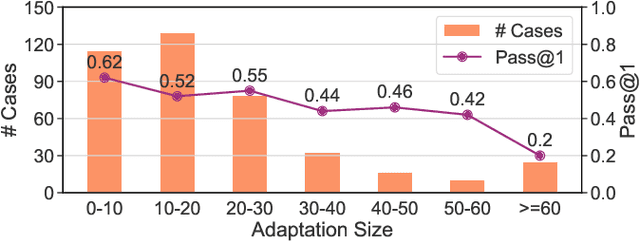
Code snippet adaptation is a fundamental activity in the software development process. Unlike code generation, code snippet adaptation is not a "free creation", which requires developers to tailor a given code snippet in order to fit specific requirements and the code context. Recently, large language models (LLMs) have confirmed their effectiveness in the code generation task with promising results. However, their performance on adaptation, a reuse-oriented and context-dependent code change prediction task, is still unclear. To bridge this gap, we conduct an empirical study to investigate the performance and issues of LLMs on the adaptation task. We first evaluate the adaptation performances of three popular LLMs and compare them to the code generation task. Our result indicates that their adaptation ability is weaker than generation, with a nearly 15% decrease on pass@1 and more context-related errors. By manually inspecting 200 cases, we further investigate the causes of LLMs' sub-optimal performance, which can be classified into three categories, i.e., Unclear Requirement, Requirement Misalignment and Context Misapplication. Based on the above empirical research, we propose an interactive prompting approach to eliciting LLMs' adaptation ability. Experimental result reveals that our approach greatly improve LLMs' adaptation performance. The best-performing Human-LLM interaction successfully solves 159 out of the 202 identified defects and improves the pass@1 and pass@5 by over 40% compared to the initial instruction-based prompt. Considering human efforts, we suggest multi-agent interaction as a trade-off, which can achieve comparable performance with excellent generalization ability. We deem that our approach could provide methodological assistance for autonomous code snippet reuse and adaptation with LLMs.
ROS package search for robot software development: a knowledge graph-based approach
Dec 22, 2023ROS (Robot Operating System) packages have become increasingly popular as a type of software artifact that can be effectively reused in robotic software development. Indeed, finding suitable ROS packages that closely match the software's functional requirements from the vast number of available packages is a nontrivial task using current search methods. The traditional search methods for ROS packages often involve inputting keywords related to robotic tasks into general-purpose search engines or code hosting platforms to obtain approximate results of all potentially suitable ROS packages. However, the accuracy of these search methods remains relatively low because the task-related keywords may not precisely match the functionalities offered by the ROS packages. To improve the search accuracy of ROS packages, this paper presents a novel semantic-based search approach that relies on the semantic-level ROS Package Knowledge Graph (RPKG) to automatically retrieve the most suitable ROS packages. Firstly, to construct the RPKG, we employ multi-dimensional feature extraction techniques to extract semantic concepts from the dataset of ROS package text descriptions. The semantic features extracted from this process result in a substantial number of entities and relationships. Subsequently, we create a robot domain-specific small corpus and further fine-tune a pre-trained language model, BERT-ROS, to generate embeddings that effectively represent the semantics of the extracted features. These embeddings play a crucial role in facilitating semantic-level understanding and comparisons during the ROS package search process within the RPKG. Secondly, we introduce a novel semantic matching-based search algorithm that incorporates the weighted similarities of multiple features from user search queries, which searches out more accurate ROS packages than the traditional keyword search method.