 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Time-Phase Synchronization for Distributed Sensing Networks via Feature-Level Hyper-Plane Regression
Mar 30, 2026Achieving coherent integration in distributed Internet of Things (IoT) sensing networks requires precise synchronization to jointly compensate clock offsets and radio-frequency (RF) phase errors. Conventional two-step protocols suffer from time-phase coupling, where residual timing offsets degrade phase coherence. This paper proposes a generalized hyper-plane regression (GHR) framework for joint calibration by transforming coupled spatiotemporal phase evolution into a unified regression model, enabling effective parameter decoupling. To support resource-constrained IoT edge nodes, a feature-level distributed architecture is developed. By adopting a linear frequency-modulated (LFM) waveform, the model order is reduced, yielding linear computational complexity. In addition, a unidirectional feature transmission mechanism eliminates the communication overhead of bidirectional timestamp exchange, making the approach suitable for resource-constrained IoT networks. Simulation results demonstrate reliable picosecond-level synchronization accuracy under severe noise across kilometer-scale distributed IoT sensing networks.
Geometric Direction Finding on Dynamic Manifolds: Unambiguous DOA Estimation for Spatially Undersampled UWB Arrays
Mar 24, 2026Traditional Direction of Arrival (DOA) estimation methods struggle to simultaneously address three physical constraints in Ultra-Wideband (UWB) electromagnetic sensing: spatial undersampling, asynchronous array phase, and beam squint. Existing solutions treat these issues in isolation, leading to limited performance in complex scenarios. This paper proposes a novel dynamic manifold perspective, which models UWB signal observations as a continuous manifold curve in a high-dimensional space driven by temporal evolution and array topology. We theoretically demonstrate that the DOA can be uniquely determined solely by the geometric shape of the manifold, rather than the absolute arrival phase. Based on this perspective, we construct a geometric parameter system comprising extrinsic and intrinsic parameters, along with a corresponding DOA estimation framework. Extrinsic vector parameters serve as a dynamic extension of traditional array processing, effectively expanding the degrees of freedom to suppress grating lobes. Intrinsic scalar invariants provide a new geometric perspective independent of traditional phase models, offering intrinsic robustness against array channel phase errors. Simulation results show that the derived analytical expressions for geometric parameters are highly consistent with numerical truths. The proposed framework not only completely eliminates spatial ambiguity in sparse arrays but also achieves high-precision direction finding under conditions with calibration-free phase errors.
Coding in a Bubble? Evaluating LLMs in Resolving Context Adaptation Bugs During Code Adaptation
Jan 10, 2026Code adaptation is a fundamental but challenging task in software development, requiring developers to modify existing code for new contexts. A key challenge is to resolve Context Adaptation Bugs (CtxBugs), which occurs when code correct in its original context violates constraints in the target environment. Unlike isolated bugs, CtxBugs cannot be resolved through local fixes and require cross-context reasoning to identify semantic mismatches. Overlooking them may lead to critical failures in adaptation. Although Large Language Models (LLMs) show great potential in automating code-related tasks, their ability to resolve CtxBugs remains a significant and unexplored obstacle to their practical use in code adaptation. To bridge this gap, we propose CtxBugGen, a novel framework for generating CtxBugs to evaluate LLMs. Its core idea is to leverage LLMs' tendency to generate plausible but context-free code when contextual constraints are absent. The framework generates CtxBugs through a four-step process to ensure their relevance and validity: (1) Adaptation Task Selection, (2) Task-specific Perturbation,(3) LLM-based Variant Generation and (4) CtxBugs Identification. Based on the benchmark constructed by CtxBugGen, we conduct an empirical study with four state-of-the-art LLMs. Our results reveal their unsatisfactory performance in CtxBug resolution. The best performing LLM, Kimi-K2, achieves 55.93% on Pass@1 and resolves just 52.47% of CtxBugs. The presence of CtxBugs degrades LLMs' adaptation performance by up to 30%. Failure analysis indicates that LLMs often overlook CtxBugs and replicate them in their outputs. Our study highlights a critical weakness in LLMs' cross-context reasoning and emphasize the need for new methods to enhance their context awareness for reliable code adaptation.
AdaptEval: A Benchmark for Evaluating Large Language Models on Code Snippet Adaptation
Jan 08, 2026Recent advancements in large language models (LLMs) have automated various software engineering tasks, with benchmarks emerging to evaluate their capabilities. However, for adaptation, a critical activity during code reuse, there is no benchmark to assess LLMs' performance, leaving their practical utility in this area unclear. To fill this gap, we propose AdaptEval, a benchmark designed to evaluate LLMs on code snippet adaptation. Unlike existing benchmarks, AdaptEval incorporates the following three distinctive features: First, Practical Context. Tasks in AdaptEval are derived from developers' practices, preserving rich contextual information from Stack Overflow and GitHub communities. Second, Multi-granularity Annotation. Each task is annotated with requirements at both task and adaptation levels, supporting the evaluation of LLMs across diverse adaptation scenarios. Third, Fine-grained Evaluation. AdaptEval includes a two-tier testing framework combining adaptation-level and function-level tests, which enables evaluating LLMs' performance across various individual adaptations. Based on AdaptEval, we conduct the first empirical study to evaluate six instruction-tuned LLMs and especially three reasoning LLMs on code snippet adaptation. Experimental results demonstrate that AdaptEval enables the assessment of LLMs' adaptation capabilities from various perspectives. It also provides critical insights into their current limitations, particularly their struggle to follow explicit instructions. We hope AdaptEval can facilitate further investigation and enhancement of LLMs' capabilities in code snippet adaptation, supporting their real-world applications.
Interpretable Cross-Sphere Multiscale Deep Learning Predicts ENSO Skilfully Beyond 2 Years
Mar 27, 2025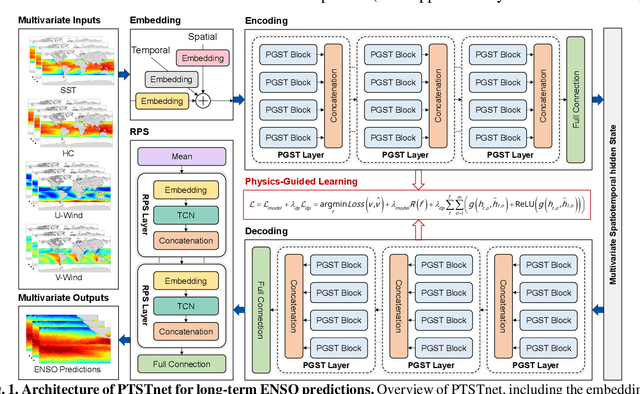
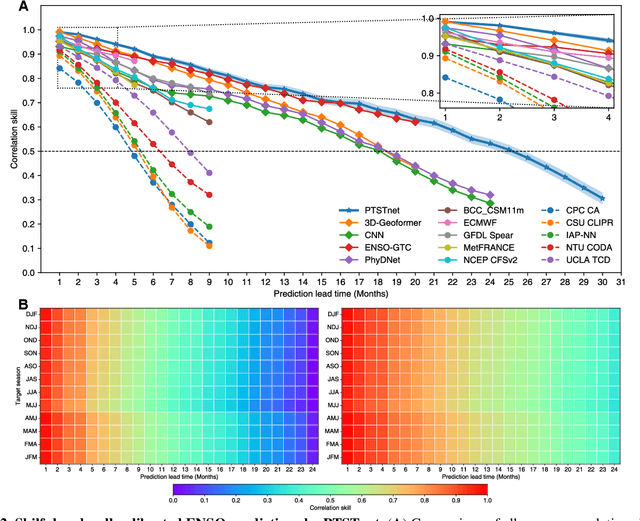
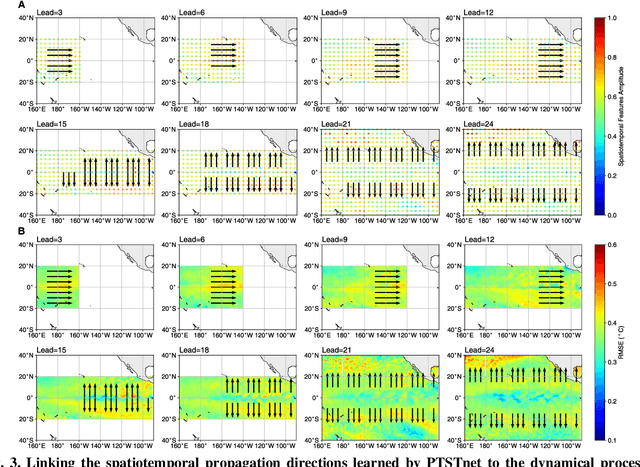
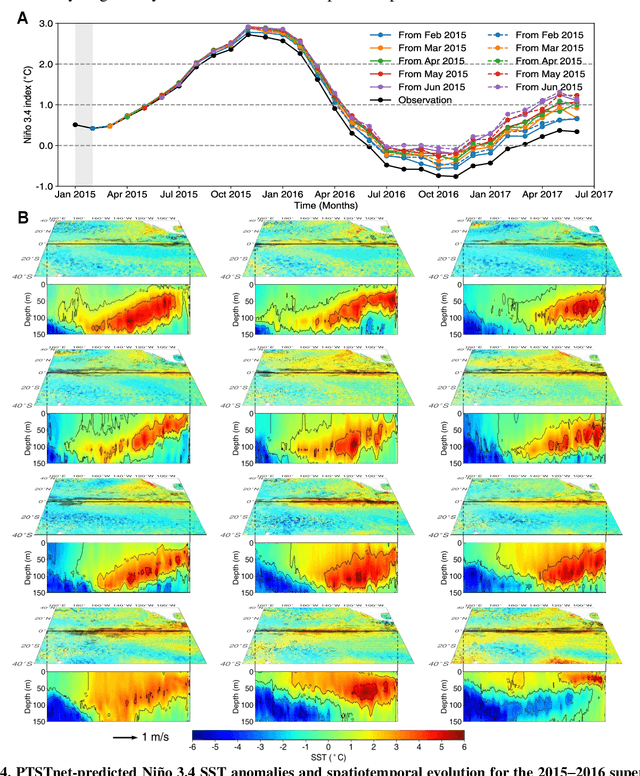
El Ni\~no-Southern Oscillation (ENSO) exerts global climate and societal impacts, but real-time prediction with lead times beyond one year remains challenging. Dynamical models suffer from large biases and uncertainties, while deep learning struggles with interpretability and multi-scale dynamics. Here, we introduce PTSTnet, an interpretable model that unifies dynamical processes and cross-scale spatiotemporal learning in an innovative neural-network framework with physics-encoding learning. PTSTnet produces interpretable predictions significantly outperforming state-of-the-art benchmarks with lead times beyond 24 months, providing physical insights into error propagation in ocean-atmosphere interactions. PTSTnet learns feature representations with physical consistency from sparse data to tackle inherent multi-scale and multi-physics challenges underlying ocean-atmosphere processes, thereby inherently enhancing long-term prediction skill. Our successful realizations mark substantial steps forward in interpretable insights into innovative neural ocean modelling.
Instruct or Interact? Exploring and Eliciting LLMs' Capability in Code Snippet Adaptation Through Prompt Engineering
Nov 23, 2024
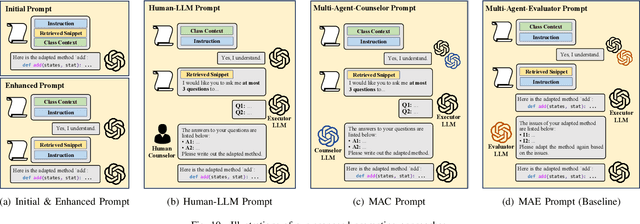
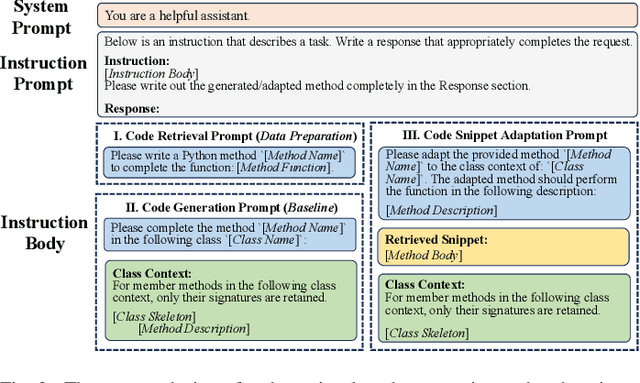
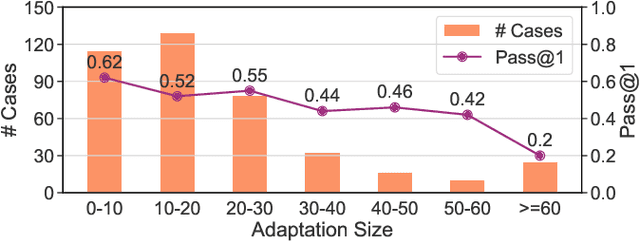
Code snippet adaptation is a fundamental activity in the software development process. Unlike code generation, code snippet adaptation is not a "free creation", which requires developers to tailor a given code snippet in order to fit specific requirements and the code context. Recently, large language models (LLMs) have confirmed their effectiveness in the code generation task with promising results. However, their performance on adaptation, a reuse-oriented and context-dependent code change prediction task, is still unclear. To bridge this gap, we conduct an empirical study to investigate the performance and issues of LLMs on the adaptation task. We first evaluate the adaptation performances of three popular LLMs and compare them to the code generation task. Our result indicates that their adaptation ability is weaker than generation, with a nearly 15% decrease on pass@1 and more context-related errors. By manually inspecting 200 cases, we further investigate the causes of LLMs' sub-optimal performance, which can be classified into three categories, i.e., Unclear Requirement, Requirement Misalignment and Context Misapplication. Based on the above empirical research, we propose an interactive prompting approach to eliciting LLMs' adaptation ability. Experimental result reveals that our approach greatly improve LLMs' adaptation performance. The best-performing Human-LLM interaction successfully solves 159 out of the 202 identified defects and improves the pass@1 and pass@5 by over 40% compared to the initial instruction-based prompt. Considering human efforts, we suggest multi-agent interaction as a trade-off, which can achieve comparable performance with excellent generalization ability. We deem that our approach could provide methodological assistance for autonomous code snippet reuse and adaptation with LLMs.
A Fast Power Spectrum Sensing Solution for Generalized Coprime Sampling
Nov 23, 2023The growing scarcity of spectrum resources, wideband spectrum sensing is required to process a prohibitive volume of data at a high sampling rate. For some applications, spectrum estimation only requires second-order statistics. In this case, a fast power spectrum sensing solution is proposed based on the generalized coprime sampling. By exploring the sensing vector inherent structure, the autocorrelation sequence of inputs can be reconstructed from sub-Nyquist samples by only utilizing the parallel Fourier transform and simple multiplication operations. Thus, it takes less time than the state-of-the-art methods while maintaining the same performance, and it achieves higher performance than the existing methods within the same execution time, without the need for pre-estimating the number of inputs. Furthermore, the influence of the model mismatch has only a minor impact on the estimation performance, which allows for more efficient use of the spectrum resource in a distributed swarm scenario. Simulation results demonstrate the low complexity in sampling and computation, making it a more practical solution for real-time and distributed wideband spectrum sensing applications.
Wideband Power Spectrum Sensing: a Fast Practical Solution for Nyquist Folding Receiver
Aug 14, 2023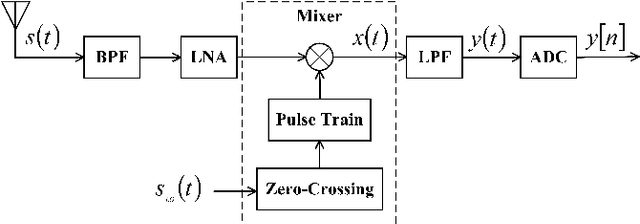
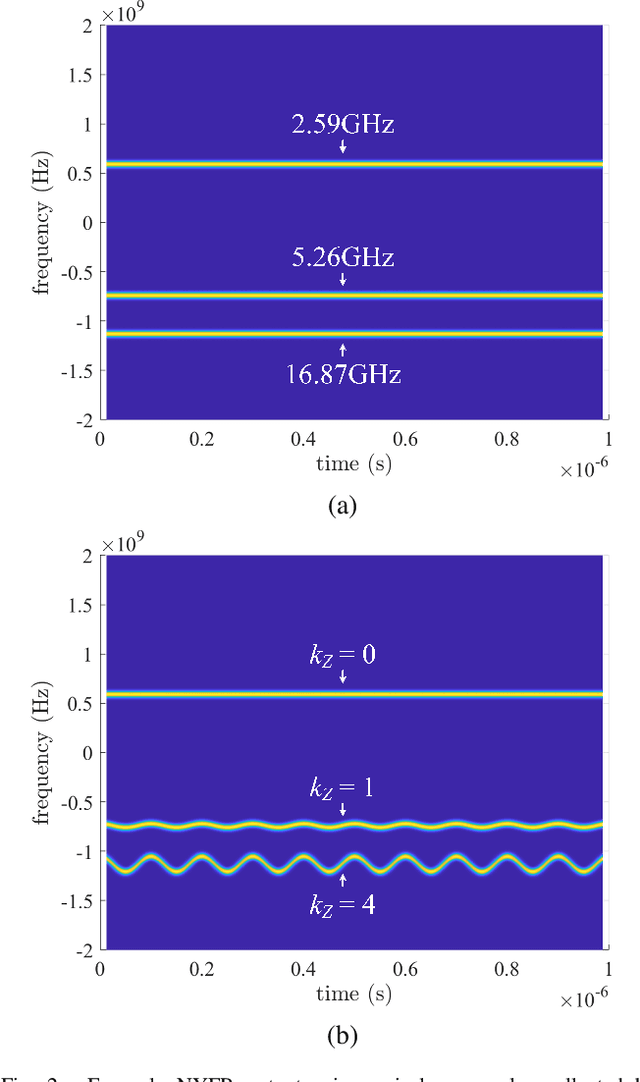
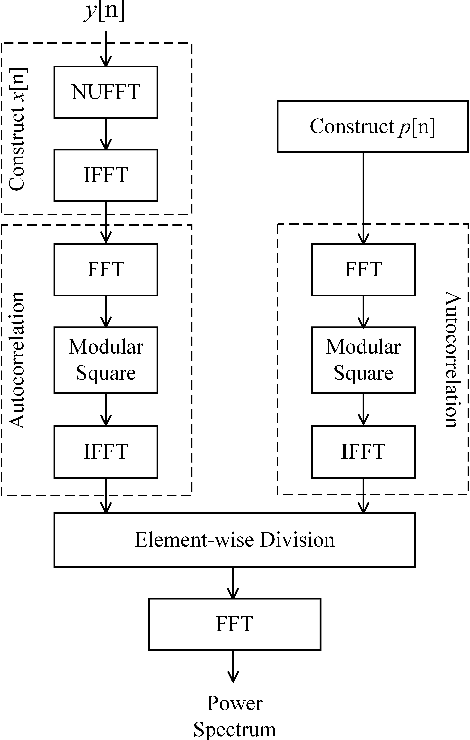
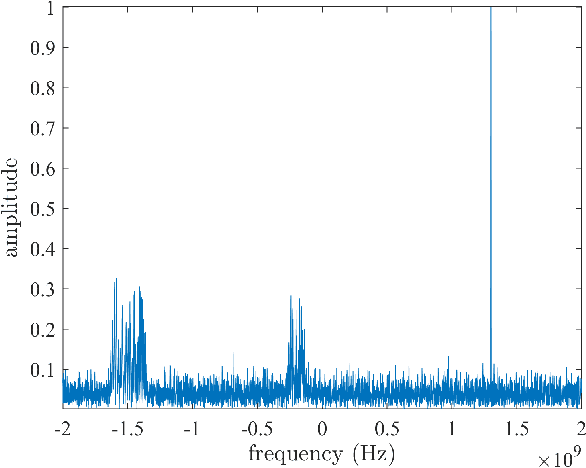
The limited availability of spectrum resources has been growing into a critical problem in wireless communications, remote sensing, and electronic surveillance, etc. To address the high-speed sampling bottleneck of wideband spectrum sensing, a fast and practical solution of power spectrum estimation for Nyquist folding receiver (NYFR) is proposed in this paper. The NYFR architectures is can theoretically achieve the full-band signal sensing with a hundred percent of probability of intercept. But the existing algorithm is difficult to realize in real-time due to its high complexity and complicated calculations. By exploring the sub-sampling principle inherent in NYFR, a computationally efficient method is introduced with compressive covariance sensing. That can be efficient implemented via only the non-uniform fast Fourier transform, fast Fourier transform, and some simple multiplication operations. Meanwhile, the state-of-the-art power spectrum reconstruction model for NYFR of time-domain and frequency-domain is constructed in this paper as a comparison. Furthermore, the computational complexity of the proposed method scales linearly with the Nyquist-rate sampled number of samples and the sparsity of spectrum occupancy. Simulation results and discussion demonstrate that the low complexity in sampling and computation is a more practical solution to meet the real-time wideband spectrum sensing applications.
Distributed UAV Swarm Augmented Wideband Spectrum Sensing Using Nyquist Folding Receiver
Aug 14, 2023Distributed unmanned aerial vehicle (UAV) swarms are formed by multiple UAVs with increased portability, higher levels of sensing capabilities, and more powerful autonomy. These features make them attractive for many recent applica-tions, potentially increasing the shortage of spectrum resources. In this paper, wideband spectrum sensing augmented technology is discussed for distributed UAV swarms to improve the utilization of spectrum. However, the sub-Nyquist sampling applied in existing schemes has high hardware complexity, power consumption, and low recovery efficiency for non-strictly sparse conditions. Thus, the Nyquist folding receiver (NYFR) is considered for the distributed UAV swarms, which can theoretically achieve full-band spectrum detection and reception using a single analog-to-digital converter (ADC) at low speed for all circuit components. There is a focus on the sensing model of two multichannel scenarios for the distributed UAV swarms, one with a complete functional receiver for the UAV swarm with RIS, and another with a decentralized UAV swarm equipped with a complete functional receiver for each UAV element. The key issue is to consider whether the application of RIS technology will bring advantages to spectrum sensing and the data fusion problem of decentralized UAV swarms based on the NYFR architecture. Therefore, the property for multiple pulse reconstruction is analyzed through the Gershgorin circle theorem, especially for very short pulses. Further, the block sparse recovery property is analyzed for wide bandwidth signals. The proposed technology can improve the processing capability for multiple signals and wide bandwidth signals while reducing interference from folded noise and subsampled harmonics. Experiment results show augmented spectrum sensing efficiency under non-strictly sparse conditions.
Gaze-Vergence-Controlled See-Through Vision in Augmented Reality
Jul 06, 2022
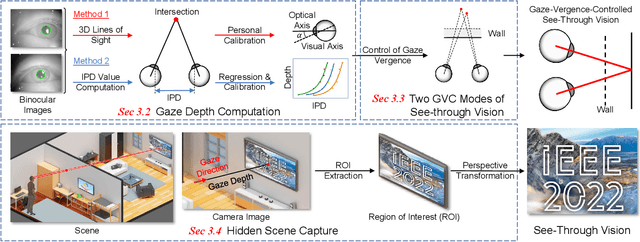
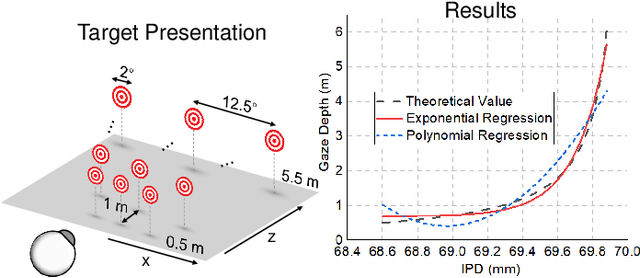
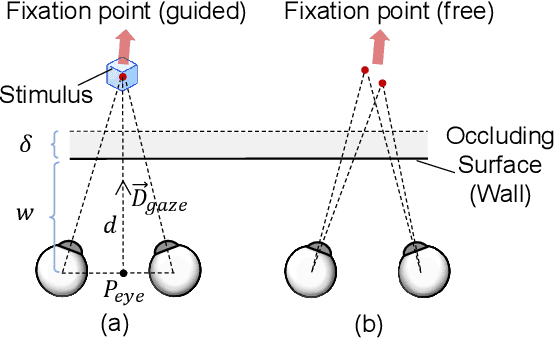
Augmented Reality (AR) see-through vision is an interesting research topic since it enables users to see through a wall and see the occluded objects. Most existing research focuses on the visual effects of see-through vision, while the interaction method is less studied. However, we argue that using common interaction modalities, e.g., midair click and speech, may not be the optimal way to control see-through vision. This is because when we want to see through something, it is physically related to our gaze depth/vergence and thus should be naturally controlled by the eyes. Following this idea, this paper proposes a novel gaze-vergence-controlled (GVC) see-through vision technique in AR. Since gaze depth is needed, we build a gaze tracking module with two infrared cameras and the corresponding algorithm and assemble it into the Microsoft HoloLens 2 to achieve gaze depth estimation. We then propose two different GVC modes for see-through vision to fit different scenarios. Extensive experimental results demonstrate that our gaze depth estimation is efficient and accurate. By comparing with conventional interaction modalities, our GVC techniques are also shown to be superior in terms of efficiency and more preferred by users. Finally, we present four example applications of gaze-vergence-controlled see-through vision.