 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXBOUND: Exploring the Capability Boundaries of Device-Control Agents through Trajectory Tree Exploration
May 27, 2025Recent advancements in vision-language models (VLMs) have spurred increased interest in Device-Control Agents (DC agents), such as utilizing in-the-wild device control to manage graphical user interfaces. Conventional methods for assessing the capabilities of DC agents, such as computing step-wise action accuracy and overall task success rates, provide a macroscopic view of DC agents' performance; however, they fail to offer microscopic insights into potential errors that may occur in real-world applications. Conducting a finer-grained performance evaluation of DC agents presents significant challenges. This study introduces a new perspective on evaluation methods for DC agents by proposing the XBOUND evaluation method, which employs the calculation of a novel Explore Metric to delineate the capability boundaries of DC agents. Compared to previous evaluation methods, XBOUND focuses on individual states to assess the proficiency of DC agents in mastering these states. Furthermore, we have developed a ``pseudo'' episode tree dataset derived from Android Control test data. Utilizing this dataset and XBOUND, we comprehensively evaluate the OS-Atlas and UI-TARS series, examining both the overall and specific performance across five common tasks. Additionally, we select representative cases to highlight the current deficiencies and limitations inherent in both series. Code is available at https://github.com/sqzhang-lazy/XBOUND.
Interpretable Cross-Sphere Multiscale Deep Learning Predicts ENSO Skilfully Beyond 2 Years
Mar 27, 2025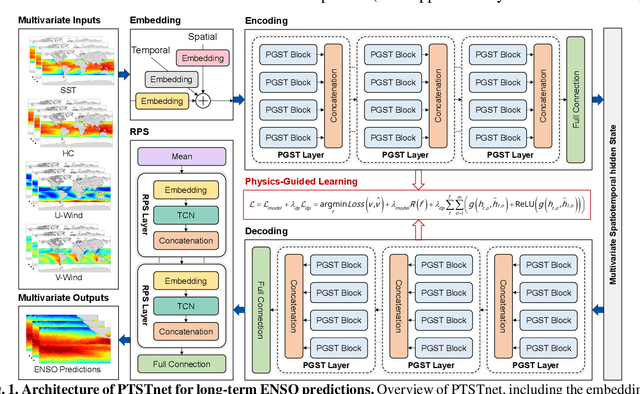
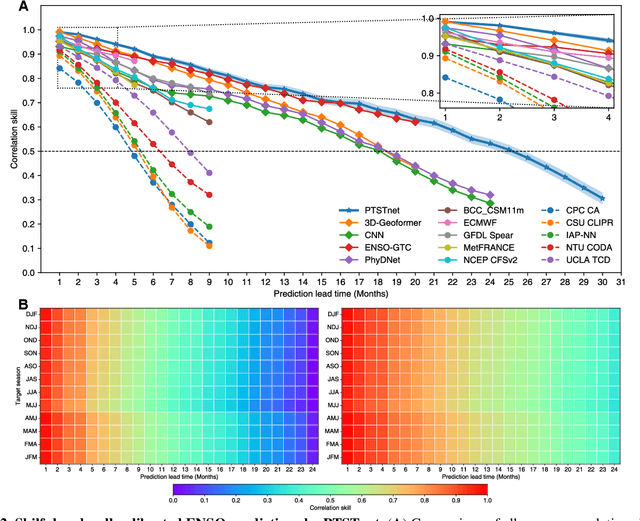
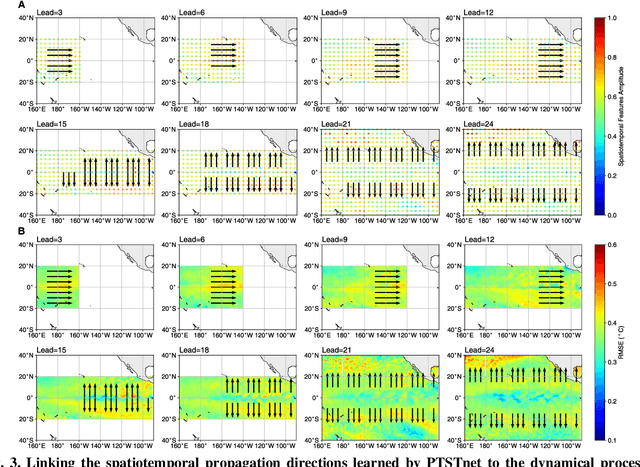
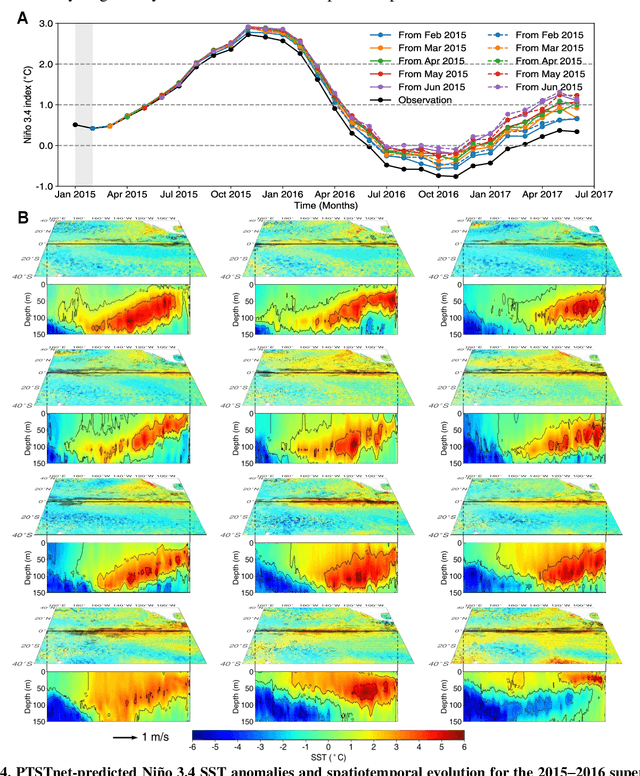
El Ni\~no-Southern Oscillation (ENSO) exerts global climate and societal impacts, but real-time prediction with lead times beyond one year remains challenging. Dynamical models suffer from large biases and uncertainties, while deep learning struggles with interpretability and multi-scale dynamics. Here, we introduce PTSTnet, an interpretable model that unifies dynamical processes and cross-scale spatiotemporal learning in an innovative neural-network framework with physics-encoding learning. PTSTnet produces interpretable predictions significantly outperforming state-of-the-art benchmarks with lead times beyond 24 months, providing physical insights into error propagation in ocean-atmosphere interactions. PTSTnet learns feature representations with physical consistency from sparse data to tackle inherent multi-scale and multi-physics challenges underlying ocean-atmosphere processes, thereby inherently enhancing long-term prediction skill. Our successful realizations mark substantial steps forward in interpretable insights into innovative neural ocean modelling.
AI Models Still Lag Behind Traditional Numerical Models in Predicting Sudden-Turning Typhoons
Feb 22, 2025Given the interpretability, accuracy, and stability of numerical weather prediction (NWP) models, current operational weather forecasting relies heavily on the NWP approach. In the past two years, the rapid development of Artificial Intelligence (AI) has provided an alternative solution for medium-range (1-10 days) weather forecasting. Bi et al. (2023) (hereafter Bi23) introduced the first AI-based weather prediction (AIWP) model in China, named Pangu-Weather, which offers fast prediction without compromising accuracy. In their work, Bi23 made notable claims regarding its effectiveness in extreme weather predictions. However, this claim lacks persuasiveness because the extreme nature of the two tropical cyclones (TCs) examples presented in Bi23, namely Typhoon Kong-rey and Typhoon Yutu, stems primarily from their intensities rather than their moving paths. Their claim may mislead into another meaning which is that Pangu-Weather works well in predicting unusual typhoon paths, which was not explicitly analyzed. Here, we reassess Pangu-Weather's ability to predict extreme TC trajectories from 2020-2024. Results reveal that while Pangu-Weather overall outperforms NWP models in predicting tropical cyclone (TC) tracks, it falls short in accurately predicting the rarely observed sudden-turning tracks, such as Typhoon Khanun in 2023. We argue that current AIWP models still lag behind traditional NWP models in predicting such rare extreme events in medium-range forecasts.
Look Before You Leap: Enhancing Attention and Vigilance Regarding Harmful Content with GuidelineLLM
Dec 10, 2024



Despite being empowered with alignment mechanisms, large language models (LLMs) are increasingly vulnerable to emerging jailbreak attacks that can compromise their alignment mechanisms. This vulnerability poses significant risks to the real-world applications. Existing work faces challenges in both training efficiency and generalization capabilities (i.e., Reinforcement Learning from Human Feedback and Red-Teaming). Developing effective strategies to enable LLMs to resist continuously evolving jailbreak attempts represents a significant challenge. To address this challenge, we propose a novel defensive paradigm called GuidelineLLM, which assists LLMs in recognizing queries that may have harmful content. Before LLMs respond to a query, GuidelineLLM first identifies potential risks associated with the query, summarizes these risks into guideline suggestions, and then feeds these guidelines to the responding LLMs. Importantly, our approach eliminates the necessity for additional safety fine-tuning of the LLMs themselves; only the GuidelineLLM requires fine-tuning. This characteristic enhances the general applicability of GuidelineLLM across various LLMs. Experimental results demonstrate that GuidelineLLM can significantly reduce the attack success rate (ASR) against the LLMs (an average reduction of 34.17\% ASR) while maintaining the helpfulness of the LLMs in handling benign queries. Code is available at https://github.com/sqzhang-lazy/GuidelineLLM.
Multi-Programming Language Sandbox for LLMs
Oct 30, 2024



We introduce MPLSandbox, an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for Large Language Models (LLMs). It can automatically identify the programming language of the code, compiling and executing it within an isolated sub-sandbox to ensure safety and stability. In addition, MPLSandbox also integrates both traditional and LLM-based code analysis tools, providing a comprehensive analysis of generated code. MPLSandbox can be effortlessly integrated into the training and deployment of LLMs to improve the quality and correctness of their generated code. It also helps researchers streamline their workflows for various LLM-based code-related tasks, reducing the development cost. To validate the effectiveness of MPLSandbox, we integrate it into training and deployment approaches, and also employ it to optimize workflows for a wide range of real-world code-related tasks. Our goal is to enhance researcher productivity on LLM-based code-related tasks by simplifying and automating workflows through delegation to MPLSandbox.
Dynamic Planning for LLM-based Graphical User Interface Automation
Oct 01, 2024



The advent of large language models (LLMs) has spurred considerable interest in advancing autonomous LLMs-based agents, particularly in intriguing applications within smartphone graphical user interfaces (GUIs). When presented with a task goal, these agents typically emulate human actions within a GUI environment until the task is completed. However, a key challenge lies in devising effective plans to guide action prediction in GUI tasks, though planning have been widely recognized as effective for decomposing complex tasks into a series of steps. Specifically, given the dynamic nature of environmental GUIs following action execution, it is crucial to dynamically adapt plans based on environmental feedback and action history.We show that the widely-used ReAct approach fails due to the excessively long historical dialogues. To address this challenge, we propose a novel approach called Dynamic Planning of Thoughts (D-PoT) for LLM-based GUI agents.D-PoT involves the dynamic adjustment of planning based on the environmental feedback and execution history. Experimental results reveal that the proposed D-PoT significantly surpassed the strong GPT-4V baseline by +12.7% (34.66% $\rightarrow$ 47.36%) in accuracy. The analysis highlights the generality of dynamic planning in different backbone LLMs, as well as the benefits in mitigating hallucinations and adapting to unseen tasks. Code is available at https://github.com/sqzhang-lazy/D-PoT.
Deep CSI Compression for Massive MIMO: A Self-information Model-driven Neural Network
Apr 25, 2022
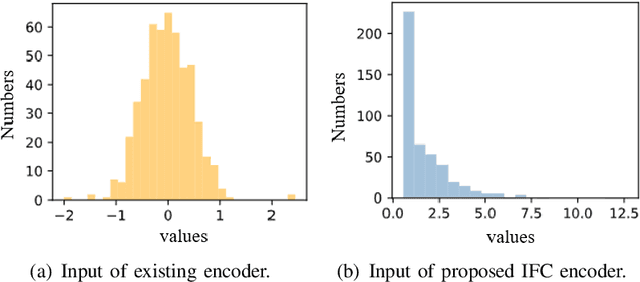
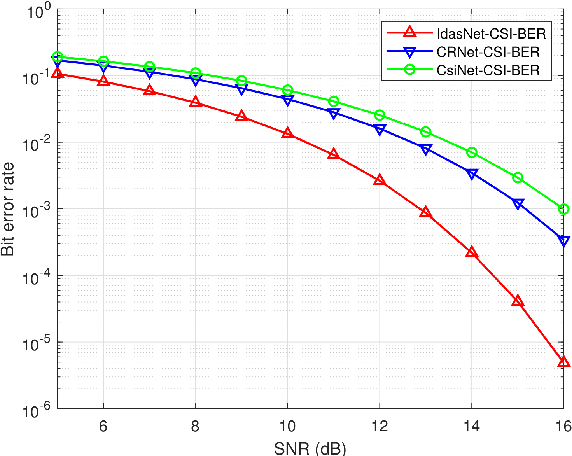
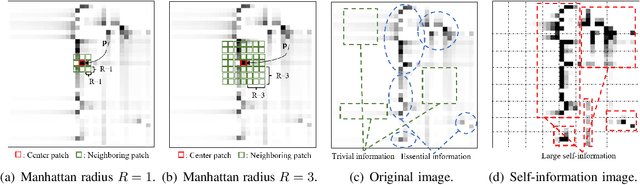
In order to fully exploit the advantages of massive multiple-input multiple-output (mMIMO), it is critical for the transmitter to accurately acquire the channel state information (CSI). Deep learning (DL)-based methods have been proposed for CSI compression and feedback to the transmitter. Although most existing DL-based methods consider the CSI matrix as an image, structural features of the CSI image are rarely exploited in neural network design. As such, we propose a model of self-information that dynamically measures the amount of information contained in each patch of a CSI image from the perspective of structural features. Then, by applying the self-information model, we propose a model-and-data-driven network for CSI compression and feedback, namely IdasNet. The IdasNet includes the design of a module of self-information deletion and selection (IDAS), an encoder of informative feature compression (IFC), and a decoder of informative feature recovery (IFR). In particular, the model-driven module of IDAS pre-compresses the CSI image by removing informative redundancy in terms of the self-information. The encoder of IFC then conducts feature compression to the pre-compressed CSI image and generates a feature codeword which contains two components, i.e., codeword values and position indices of the codeword values. Subsequently, the IFR decoder decouples the codeword values as well as position indices to recover the CSI image. Experimental results verify that the proposed IdasNet noticeably outperforms existing DL-based networks under various compression ratios while it has the number of network parameters reduced by orders-of-magnitude compared with various existing methods.
Data Augmentation Empowered Neural Precoding for Multiuser MIMO with MMSE Model
Mar 04, 2022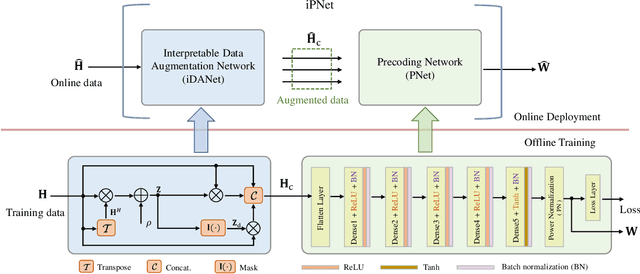
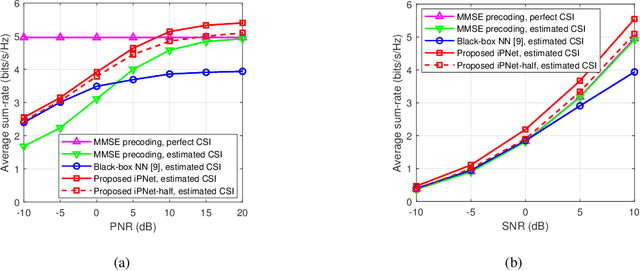
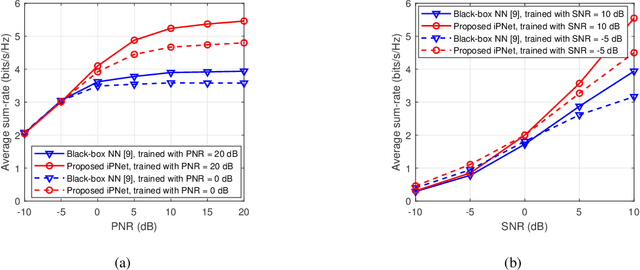
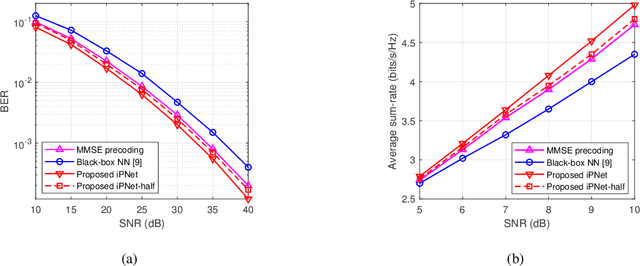
Precoding design exploiting deep learning methods has been widely studied for multiuser multiple-input multiple-output (MU-MIMO) systems. However, conventional neural precoding design applies black-box-based neural networks which are less interpretable. In this paper, we propose a deep learning-based precoding method based on an interpretable design of a neural precoding network, namely iPNet. In particular, the iPNet mimics the classic minimum mean-squared error (MMSE) precoding and approximates the matrix inversion in the design of the neural network architecture. Specifically, the proposed iPNet consists of a model-driven component network, responsible for augmenting the input channel state information (CSI), and a data-driven sub-network, responsible for precoding calculation from this augmented CSI. The latter data-driven module is explicitly interpreted as an unsupervised learner of the MMSE precoder. Simulation results show that by exploiting the augmented CSI, the proposed iPNet achieves noticeable performance gain over existing black-box designs and also exhibits enhanced generalizability against CSI mismatches.