 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFPO: Scaling Value Modeling via Distributional Flow towards Robust and Generalizable LLM Post-Training
Feb 05, 2026Training reinforcement learning (RL) systems in real-world environments remains challenging due to noisy supervision and poor out-of-domain (OOD) generalization, especially in LLM post-training. Recent distributional RL methods improve robustness by modeling values with multiple quantile points, but they still learn each quantile independently as a scalar. This results in rough-grained value representations that lack fine-grained conditioning on state information, struggling under complex and OOD conditions. We propose DFPO (Distributional Value Flow Policy Optimization with Conditional Risk and Consistency Control), a robust distributional RL framework that models values as continuous flows across time steps. By scaling value modeling through learning of a value flow field instead of isolated quantile predictions, DFPO captures richer state information for more accurate advantage estimation. To stabilize training under noisy feedback, DFPO further integrates conditional risk control and consistency constraints along value flow trajectories. Experiments on dialogue, math reasoning, and scientific tasks show that DFPO outperforms PPO, FlowRL, and other robust baselines under noisy supervision, achieving improved training stability and generalization.
AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning
Sep 10, 2025Developing autonomous LLM agents capable of making a series of intelligent decisions to solve complex, real-world tasks is a fast-evolving frontier. Like human cognitive development, agents are expected to acquire knowledge and skills through exploration and interaction with the environment. Despite advances, the community still lacks a unified, interactive reinforcement learning (RL) framework that can effectively train such agents from scratch -- without relying on supervised fine-tuning (SFT) -- across diverse and realistic environments. To bridge this gap, we introduce AgentGym-RL, a new framework to train LLM agents for multi-turn interactive decision-making through RL. The framework features a modular and decoupled architecture, ensuring high flexibility and extensibility. It encompasses a wide variety of real-world scenarios, and supports mainstream RL algorithms. Furthermore, we propose ScalingInter-RL, a training approach designed for exploration-exploitation balance and stable RL optimization. In early stages, it emphasizes exploitation by restricting the number of interactions, and gradually shifts towards exploration with larger horizons to encourage diverse problem-solving strategies. In this way, the agent develops more diverse behaviors and is less prone to collapse under long horizons. We perform extensive experiments to validate the stability and effectiveness of both the AgentGym-RL framework and the ScalingInter-RL approach. Our agents match or surpass commercial models on 27 tasks across diverse environments. We offer key insights and will open-source the complete AgentGym-RL framework -- including code and datasets -- to empower the research community in developing the next generation of intelligent agents.
Understanding and Mitigating Errors of LLM-Generated RTL Code
Aug 07, 2025Despite the promising potential of large language model (LLM) based register-transfer-level (RTL) code generation, the overall success rate remains unsatisfactory. Errors arise from various factors, with limited understanding of specific failure causes hindering improvement. To address this, we conduct a comprehensive error analysis and manual categorization. Our findings reveal that most errors stem not from LLM reasoning limitations, but from insufficient RTL programming knowledge, poor understanding of circuit concepts, ambiguous design descriptions, or misinterpretation of complex multimodal inputs. Leveraging in-context learning, we propose targeted error correction techniques. Specifically, we construct a domain-specific knowledge base and employ retrieval-augmented generation (RAG) to supply necessary RTL knowledge. To mitigate ambiguity errors, we introduce design description rules and implement a rule-checking mechanism. For multimodal misinterpretation, we integrate external tools to convert inputs into LLM-compatible meta-formats. For remaining errors, we adopt an iterative debugging loop (simulation-error localization-correction). Integrating these techniques into an LLM-based framework significantly improves performance. We incorporate these error correction techniques into a foundational LLM-based RTL code generation framework, resulting in significantly improved performance. Experimental results show that our enhanced framework achieves 91.0\% accuracy on the VerilogEval benchmark, surpassing the baseline code generation approach by 32.7\%, demonstrating the effectiveness of our methods.
Compression Hacking: A Supplementary Perspective on Informatics Metric of Language Models from Geometric Distortion
May 23, 2025Recently, the concept of ``compression as intelligence'' has provided a novel informatics metric perspective for language models (LMs), emphasizing that highly structured representations signify the intelligence level of LMs. However, from a geometric standpoint, the word representation space of highly compressed LMs tends to degenerate into a highly anisotropic state, which hinders the LM's ability to comprehend instructions and directly impacts its performance. We found this compression-anisotropy synchronicity is essentially the ``Compression Hacking'' in LM representations, where noise-dominated directions tend to create the illusion of high compression rates by sacrificing spatial uniformity. Based on this, we propose three refined compression metrics by incorporating geometric distortion analysis and integrate them into a self-evaluation pipeline. The refined metrics exhibit strong alignment with the LM's comprehensive capabilities, achieving Spearman correlation coefficients above 0.9, significantly outperforming both the original compression and other internal structure-based metrics. This confirms that compression hacking substantially enhances the informatics interpretation of LMs by incorporating geometric distortion of representations.
FRAbench and GenEval: Scaling Fine-Grained Aspect Evaluation across Tasks, Modalities
May 19, 2025Evaluating the open-ended outputs of large language models (LLMs) has become a bottleneck as model capabilities, task diversity, and modality coverage rapidly expand. Existing "LLM-as-a-Judge" evaluators are typically narrow in a few tasks, aspects, or modalities, and easily suffer from low consistency. In this paper, we argue that explicit, fine-grained aspect specification is the key to both generalizability and objectivity in automated evaluation. To do so, we introduce a hierarchical aspect taxonomy spanning 112 aspects that unifies evaluation across four representative settings - Natural Language Generation, Image Understanding, Image Generation, and Interleaved Text-and-Image Generation. Building on this taxonomy, we create FRAbench, a benchmark comprising 60.4k pairwise samples with 325k aspect-level labels obtained from a combination of human and LLM annotations. FRAbench provides the first large-scale, multi-modal resource for training and meta-evaluating fine-grained LMM judges. Leveraging FRAbench, we develop GenEval, a fine-grained evaluator generalizable across tasks and modalities. Experiments show that GenEval (i) attains high agreement with GPT-4o and expert annotators, (ii) transfers robustly to unseen tasks and modalities, and (iii) reveals systematic weaknesses of current LMMs on evaluation.
Two Minds Better Than One: Collaborative Reward Modeling for LLM Alignment
May 19, 2025Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human values. However, noisy preferences in human feedback can lead to reward misgeneralization - a phenomenon where reward models learn spurious correlations or overfit to noisy preferences, which poses important challenges to the generalization of RMs. This paper systematically analyzes the characteristics of preference pairs and aims to identify how noisy preferences differ from human-aligned preferences in reward modeling. Our analysis reveals that noisy preferences are difficult for RMs to fit, as they cause sharp training fluctuations and irregular gradient updates. These distinctive dynamics suggest the feasibility of identifying and excluding such noisy preferences. Empirical studies demonstrate that policy LLM optimized with a reward model trained on the full preference dataset, which includes substantial noise, performs worse than the one trained on a subset of exclusively high quality preferences. To address this challenge, we propose an online Collaborative Reward Modeling (CRM) framework to achieve robust preference learning through peer review and curriculum learning. In particular, CRM maintains two RMs that collaboratively filter potential noisy preferences by peer-reviewing each other's data selections. Curriculum learning synchronizes the capabilities of two models, mitigating excessive disparities to promote the utility of peer review. Extensive experiments demonstrate that CRM significantly enhances RM generalization, with up to 9.94 points improvement on RewardBench under an extreme 40\% noise. Moreover, CRM can seamlessly extend to implicit-reward alignment methods, offering a robust and versatile alignment strategy.
Better Process Supervision with Bi-directional Rewarding Signals
Mar 06, 2025Process supervision, i.e., evaluating each step, is critical for complex large language model (LLM) reasoning and test-time searching with increased inference compute. Existing approaches, represented by process reward models (PRMs), primarily focus on rewarding signals up to the current step, exhibiting a one-directional nature and lacking a mechanism to model the distance to the final target. To address this problem, we draw inspiration from the A* algorithm, which states that an effective supervisory signal should simultaneously consider the incurred cost and the estimated cost for reaching the target. Building on this key insight, we introduce BiRM, a novel process supervision model that not only evaluates the correctness of previous steps but also models the probability of future success. We conduct extensive experiments on mathematical reasoning tasks and demonstrate that BiRM provides more precise evaluations of LLM reasoning steps, achieving an improvement of 3.1% on Gaokao2023 over PRM under the Best-of-N sampling method. Besides, in search-based strategies, BiRM provides more comprehensive guidance and outperforms ORM by 5.0% and PRM by 3.8% respectively on MATH-500.
DocFusion: A Unified Framework for Document Parsing Tasks
Dec 17, 2024



Document parsing is essential for analyzing complex document structures and extracting fine-grained information, supporting numerous downstream applications. However, existing methods often require integrating multiple independent models to handle various parsing tasks, leading to high complexity and maintenance overhead. To address this, we propose DocFusion, a lightweight generative model with only 0.28B parameters. It unifies task representations and achieves collaborative training through an improved objective function. Experiments reveal and leverage the mutually beneficial interaction among recognition tasks, and integrating recognition data significantly enhances detection performance. The final results demonstrate that DocFusion achieves state-of-the-art (SOTA) performance across four key tasks.
Multi-Programming Language Sandbox for LLMs
Oct 30, 2024



We introduce MPLSandbox, an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for Large Language Models (LLMs). It can automatically identify the programming language of the code, compiling and executing it within an isolated sub-sandbox to ensure safety and stability. In addition, MPLSandbox also integrates both traditional and LLM-based code analysis tools, providing a comprehensive analysis of generated code. MPLSandbox can be effortlessly integrated into the training and deployment of LLMs to improve the quality and correctness of their generated code. It also helps researchers streamline their workflows for various LLM-based code-related tasks, reducing the development cost. To validate the effectiveness of MPLSandbox, we integrate it into training and deployment approaches, and also employ it to optimize workflows for a wide range of real-world code-related tasks. Our goal is to enhance researcher productivity on LLM-based code-related tasks by simplifying and automating workflows through delegation to MPLSandbox.
Lightweight Spatial Modeling for Combinatorial Information Extraction From Documents
May 08, 2024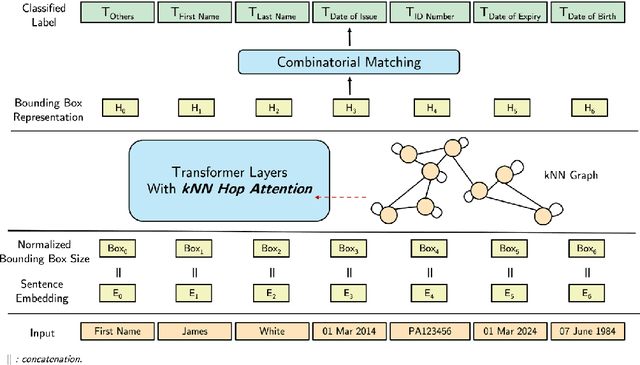



Documents that consist of diverse templates and exhibit complex spatial structures pose a challenge for document entity classification. We propose KNN-former, which incorporates a new kind of spatial bias in attention calculation based on the K-nearest-neighbor (KNN) graph of document entities. We limit entities' attention only to their local radius defined by the KNN graph. We also use combinatorial matching to address the one-to-one mapping property that exists in many documents, where one field has only one corresponding entity. Moreover, our method is highly parameter-efficient compared to existing approaches in terms of the number of trainable parameters. Despite this, experiments across various datasets show our method outperforms baselines in most entity types. Many real-world documents exhibit combinatorial properties which can be leveraged as inductive biases to improve extraction accuracy, but existing datasets do not cover these documents. To facilitate future research into these types of documents, we release a new ID document dataset that covers diverse templates and languages. We also release enhanced annotations for an existing dataset.