 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Spatial Modeling for Combinatorial Information Extraction From Documents
Paper and Code
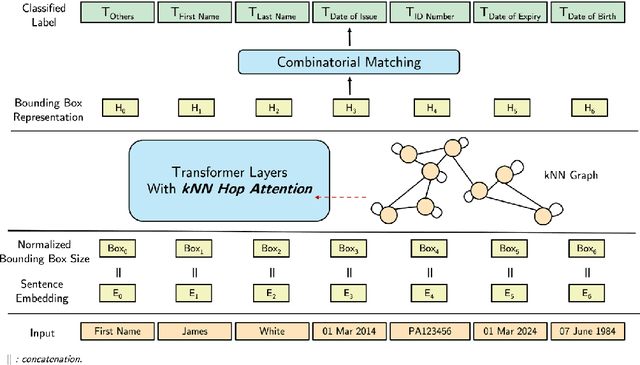



Documents that consist of diverse templates and exhibit complex spatial structures pose a challenge for document entity classification. We propose KNN-former, which incorporates a new kind of spatial bias in attention calculation based on the K-nearest-neighbor (KNN) graph of document entities. We limit entities' attention only to their local radius defined by the KNN graph. We also use combinatorial matching to address the one-to-one mapping property that exists in many documents, where one field has only one corresponding entity. Moreover, our method is highly parameter-efficient compared to existing approaches in terms of the number of trainable parameters. Despite this, experiments across various datasets show our method outperforms baselines in most entity types. Many real-world documents exhibit combinatorial properties which can be leveraged as inductive biases to improve extraction accuracy, but existing datasets do not cover these documents. To facilitate future research into these types of documents, we release a new ID document dataset that covers diverse templates and languages. We also release enhanced annotations for an existing dataset.