 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextSSR: Diffusion-based Data Synthesis for Scene Text Recognition
Dec 02, 2024



Scene text recognition (STR) suffers from the challenges of either less realistic synthetic training data or the difficulty of collecting sufficient high-quality real-world data, limiting the effectiveness of trained STR models. Meanwhile, despite producing holistically appealing text images, diffusion-based text image generation methods struggle to generate accurate and realistic instance-level text on a large scale. To tackle this, we introduce TextSSR: a novel framework for Synthesizing Scene Text Recognition data via a diffusion-based universal text region synthesis model. It ensures accuracy by focusing on generating text within a specified image region and leveraging rich glyph and position information to create the less complex text region compared to the entire image. Furthermore, we utilize neighboring text within the region as a prompt to capture real-world font styles and layout patterns, guiding the generated text to resemble actual scenes. Finally, due to its prompt-free nature and capability for character-level synthesis, TextSSR enjoys a wonderful scalability and we construct an anagram-based TextSSR-F dataset with 0.4 million text instances with complexity and realism. Experiments show that models trained on added TextSSR-F data exhibit better accuracy compared to models trained on 4 million existing synthetic data. Moreover, its accuracy margin to models trained fully on a real-world dataset is less than 3.7%, confirming TextSSR's effectiveness and its great potential in scene text image synthesis. Our code is available at https://github.com/YesianRohn/TextSSR.
Hard-Label Black-Box Attacks on 3D Point Clouds
Nov 30, 2024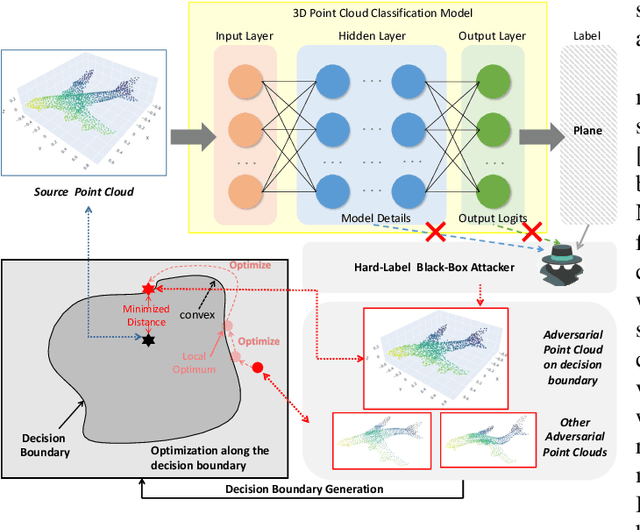
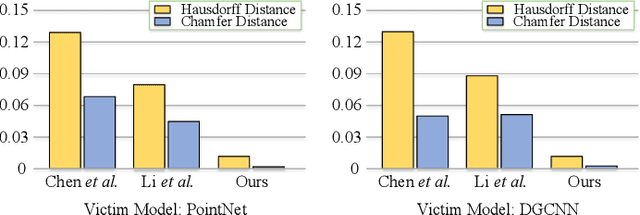
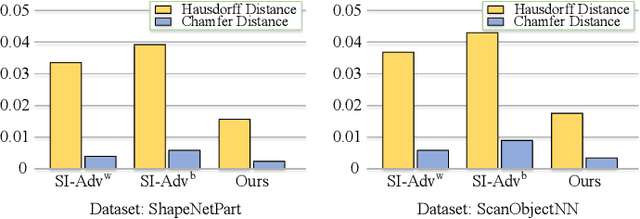
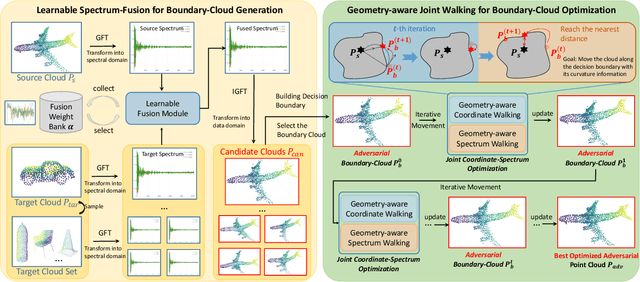
With the maturity of depth sensors in various 3D safety-critical applications, 3D point cloud models have been shown to be vulnerable to adversarial attacks. Almost all existing 3D attackers simply follow the white-box or black-box setting to iteratively update coordinate perturbations based on back-propagated or estimated gradients. However, these methods are hard to deploy in real-world scenarios (no model details are provided) as they severely rely on parameters or output logits of victim models. To this end, we propose point cloud attacks from a more practical setting, i.e., hard-label black-box attack, in which attackers can only access the prediction label of 3D input. We introduce a novel 3D attack method based on a new spectrum-aware decision boundary algorithm to generate high-quality adversarial samples. In particular, we first construct a class-aware model decision boundary, by developing a learnable spectrum-fusion strategy to adaptively fuse point clouds of different classes in the spectral domain, aiming to craft their intermediate samples without distorting the original geometry. Then, we devise an iterative coordinate-spectrum optimization method with curvature-aware boundary search to move the intermediate sample along the decision boundary for generating adversarial point clouds with trivial perturbations. Experiments demonstrate that our attack competitively outperforms existing white/black-box attackers in terms of attack performance and adversary quality.
Multi-Programming Language Sandbox for LLMs
Oct 30, 2024



We introduce MPLSandbox, an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for Large Language Models (LLMs). It can automatically identify the programming language of the code, compiling and executing it within an isolated sub-sandbox to ensure safety and stability. In addition, MPLSandbox also integrates both traditional and LLM-based code analysis tools, providing a comprehensive analysis of generated code. MPLSandbox can be effortlessly integrated into the training and deployment of LLMs to improve the quality and correctness of their generated code. It also helps researchers streamline their workflows for various LLM-based code-related tasks, reducing the development cost. To validate the effectiveness of MPLSandbox, we integrate it into training and deployment approaches, and also employ it to optimize workflows for a wide range of real-world code-related tasks. Our goal is to enhance researcher productivity on LLM-based code-related tasks by simplifying and automating workflows through delegation to MPLSandbox.
What's Wrong with Your Code Generated by Large Language Models? An Extensive Study
Jul 08, 2024
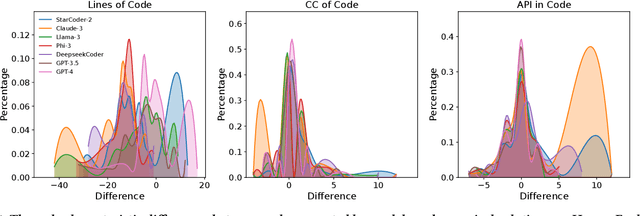


The increasing development of large language models (LLMs) in code generation has drawn significant attention among researchers. To enhance LLM-based code generation ability, current efforts are predominantly directed towards collecting high-quality datasets and leveraging diverse training technologies. However, there is a notable lack of comprehensive studies examining the limitations and boundaries of these existing methods. To bridge this gap, we conducted an extensive empirical study evaluating the performance of three leading closed-source LLMs and four popular open-source LLMs on three commonly used benchmarks. Our investigation, which evaluated the length, cyclomatic complexity and API number of the generated code, revealed that these LLMs face challenges in generating successful code for more complex problems, and tend to produce code that is shorter yet more complicated as compared to canonical solutions. Additionally, we developed a taxonomy of bugs for incorrect codes that includes three categories and 12 sub-categories, and analyze the root cause for common bug types. Furthermore, to better understand the performance of LLMs in real-world projects, we manually created a real-world benchmark comprising 140 code generation tasks. Our analysis highlights distinct differences in bug distributions between actual scenarios and existing benchmarks. Finally, we propose a novel training-free iterative method that introduces self-critique, enabling LLMs to critique and correct their generated code based on bug types and compiler feedback. Experimental results demonstrate that our approach can significantly mitigate bugs and increase the passing rate by 29.2% after two iterations, indicating substantial potential for LLMs to handle more complex problems.
3DHacker: Spectrum-based Decision Boundary Generation for Hard-label 3D Point Cloud Attack
Aug 15, 2023



With the maturity of depth sensors, the vulnerability of 3D point cloud models has received increasing attention in various applications such as autonomous driving and robot navigation. Previous 3D adversarial attackers either follow the white-box setting to iteratively update the coordinate perturbations based on gradients, or utilize the output model logits to estimate noisy gradients in the black-box setting. However, these attack methods are hard to be deployed in real-world scenarios since realistic 3D applications will not share any model details to users. Therefore, we explore a more challenging yet practical 3D attack setting, \textit{i.e.}, attacking point clouds with black-box hard labels, in which the attacker can only have access to the prediction label of the input. To tackle this setting, we propose a novel 3D attack method, termed \textbf{3D} \textbf{H}ard-label att\textbf{acker} (\textbf{3DHacker}), based on the developed decision boundary algorithm to generate adversarial samples solely with the knowledge of class labels. Specifically, to construct the class-aware model decision boundary, 3DHacker first randomly fuses two point clouds of different classes in the spectral domain to craft their intermediate sample with high imperceptibility, then projects it onto the decision boundary via binary search. To restrict the final perturbation size, 3DHacker further introduces an iterative optimization strategy to move the intermediate sample along the decision boundary for generating adversarial point clouds with smallest trivial perturbations. Extensive evaluations show that, even in the challenging hard-label setting, 3DHacker still competitively outperforms existing 3D attacks regarding the attack performance as well as adversary quality.