 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2Sent: Nested Selectivity Aware Sentence Representation Learning
Aug 25, 2025The combination of Transformer-based encoders with contrastive learning represents the current mainstream paradigm for sentence representation learning. This paradigm is typically based on the hidden states of the last Transformer block of the encoder. However, within Transformer-based encoders, different blocks exhibit varying degrees of semantic perception ability. From the perspective of interpretability, the semantic perception potential of knowledge neurons is modulated by stimuli, thus rational cross-block representation fusion is a direction worth optimizing. To balance the semantic redundancy and loss across block fusion, we propose a sentence representation selection mechanism S\textsuperscript{2}Sent, which integrates a parameterized nested selector downstream of the Transformer-based encoder. This selector performs spatial selection (SS) and nested frequency selection (FS) from a modular perspective. The SS innovatively employs a spatial squeeze based self-gating mechanism to obtain adaptive weights, which not only achieves fusion with low information redundancy but also captures the dependencies between embedding features. The nested FS replaces GAP with different DCT basis functions to achieve spatial squeeze with low semantic loss. Extensive experiments have demonstrated that S\textsuperscript{2}Sent achieves significant improvements over baseline methods with negligible additional parameters and inference latency, while highlighting high integrability and scalability.
Compression Hacking: A Supplementary Perspective on Informatics Metric of Language Models from Geometric Distortion
May 23, 2025Recently, the concept of ``compression as intelligence'' has provided a novel informatics metric perspective for language models (LMs), emphasizing that highly structured representations signify the intelligence level of LMs. However, from a geometric standpoint, the word representation space of highly compressed LMs tends to degenerate into a highly anisotropic state, which hinders the LM's ability to comprehend instructions and directly impacts its performance. We found this compression-anisotropy synchronicity is essentially the ``Compression Hacking'' in LM representations, where noise-dominated directions tend to create the illusion of high compression rates by sacrificing spatial uniformity. Based on this, we propose three refined compression metrics by incorporating geometric distortion analysis and integrate them into a self-evaluation pipeline. The refined metrics exhibit strong alignment with the LM's comprehensive capabilities, achieving Spearman correlation coefficients above 0.9, significantly outperforming both the original compression and other internal structure-based metrics. This confirms that compression hacking substantially enhances the informatics interpretation of LMs by incorporating geometric distortion of representations.
Multi-Programming Language Sandbox for LLMs
Oct 30, 2024



We introduce MPLSandbox, an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for Large Language Models (LLMs). It can automatically identify the programming language of the code, compiling and executing it within an isolated sub-sandbox to ensure safety and stability. In addition, MPLSandbox also integrates both traditional and LLM-based code analysis tools, providing a comprehensive analysis of generated code. MPLSandbox can be effortlessly integrated into the training and deployment of LLMs to improve the quality and correctness of their generated code. It also helps researchers streamline their workflows for various LLM-based code-related tasks, reducing the development cost. To validate the effectiveness of MPLSandbox, we integrate it into training and deployment approaches, and also employ it to optimize workflows for a wide range of real-world code-related tasks. Our goal is to enhance researcher productivity on LLM-based code-related tasks by simplifying and automating workflows through delegation to MPLSandbox.
Modeling Selective Feature Attention for Representation-based Siamese Text Matching
Apr 25, 2024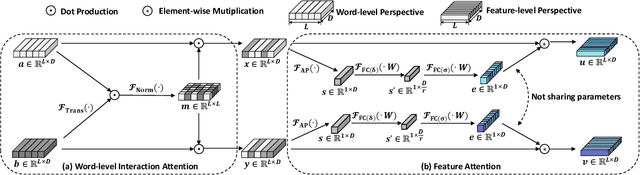
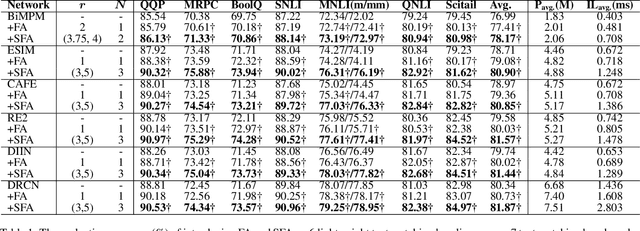
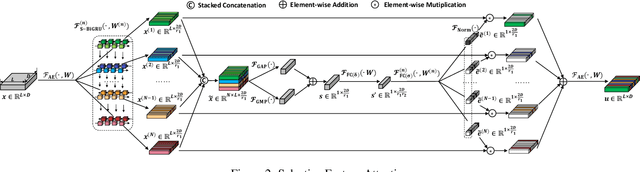
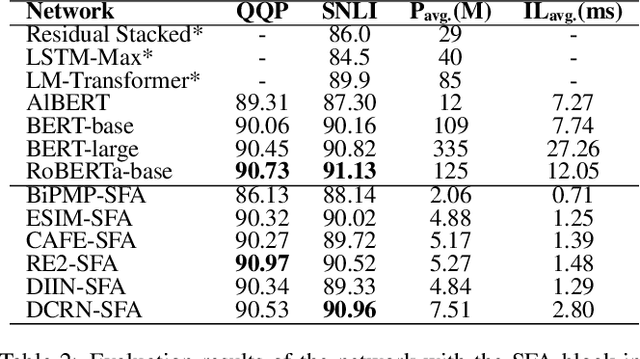
Representation-based Siamese networks have risen to popularity in lightweight text matching due to their low deployment and inference costs. While word-level attention mechanisms have been implemented within Siamese networks to improve performance, we propose Feature Attention (FA), a novel downstream block designed to enrich the modeling of dependencies among embedding features. Employing "squeeze-and-excitation" techniques, the FA block dynamically adjusts the emphasis on individual features, enabling the network to concentrate more on features that significantly contribute to the final classification. Building upon FA, we introduce a dynamic "selection" mechanism called Selective Feature Attention (SFA), which leverages a stacked BiGRU Inception structure. The SFA block facilitates multi-scale semantic extraction by traversing different stacked BiGRU layers, encouraging the network to selectively concentrate on semantic information and embedding features across varying levels of abstraction. Both the FA and SFA blocks offer a seamless integration capability with various Siamese networks, showcasing a plug-and-play characteristic. Experimental evaluations conducted across diverse text matching baselines and benchmarks underscore the indispensability of modeling feature attention and the superiority of the "selection" mechanism.
Explanation based Bias Decoupling Regularization for Natural Language Inference
Apr 20, 2024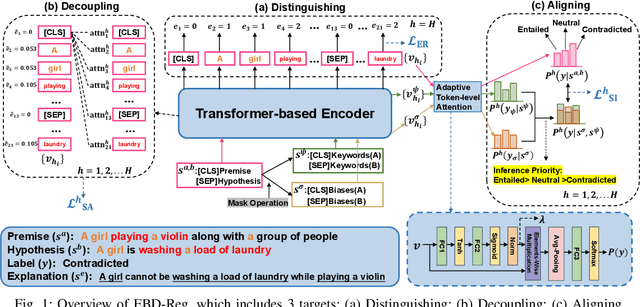
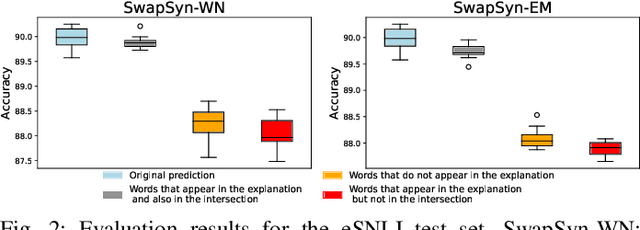
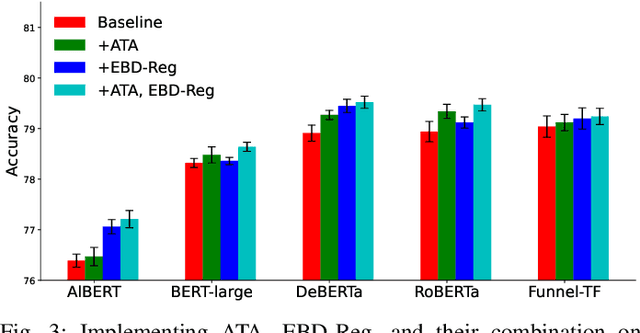
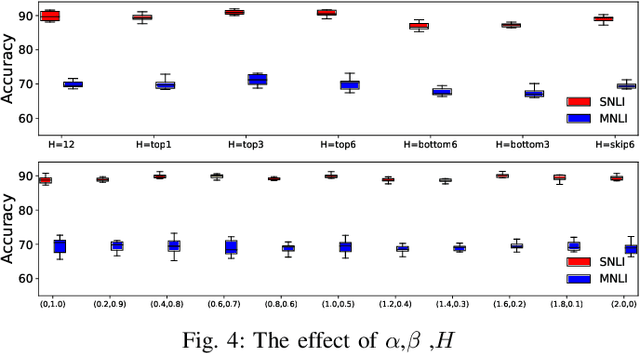
The robustness of Transformer-based Natural Language Inference encoders is frequently compromised as they tend to rely more on dataset biases than on the intended task-relevant features. Recent studies have attempted to mitigate this by reducing the weight of biased samples during the training process. However, these debiasing methods primarily focus on identifying which samples are biased without explicitly determining the biased components within each case. This limitation restricts those methods' capability in out-of-distribution inference. To address this issue, we aim to train models to adopt the logic humans use in explaining causality. We propose a simple, comprehensive, and interpretable method: Explanation based Bias Decoupling Regularization (EBD-Reg). EBD-Reg employs human explanations as criteria, guiding the encoder to establish a tripartite parallel supervision of Distinguishing, Decoupling and Aligning. This method enables encoders to identify and focus on keywords that represent the task-relevant features during inference, while discarding the residual elements acting as biases. Empirical evidence underscores that EBD-Reg effectively guides various Transformer-based encoders to decouple biases through a human-centric lens, significantly surpassing other methods in terms of out-of-distribution inference capabilities.
Improving Text Semantic Similarity Modeling through a 3D Siamese Network
Jul 18, 2023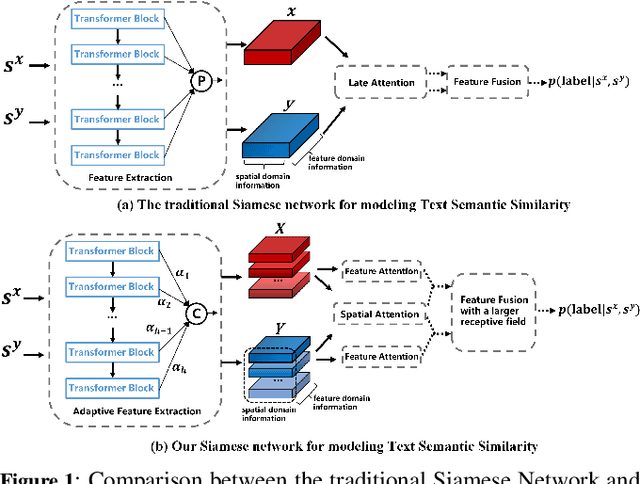
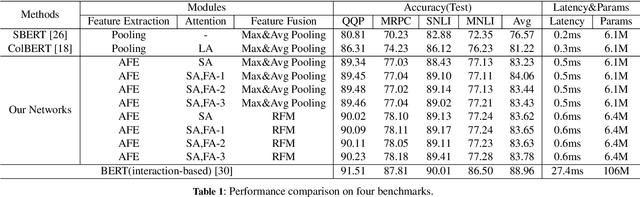
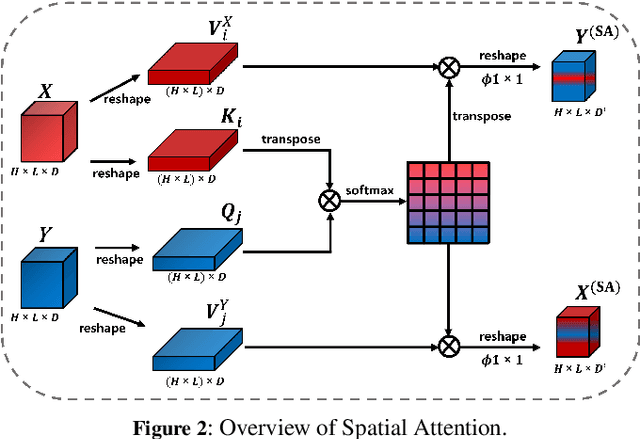
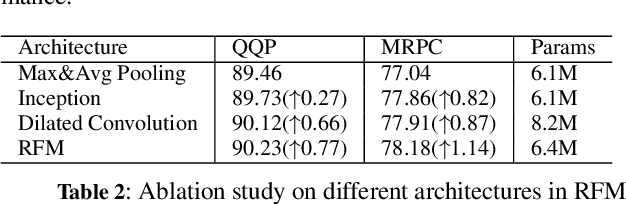
Siamese networks have gained popularity as a method for modeling text semantic similarity. Traditional methods rely on pooling operation to compress the semantic representations from Transformer blocks in encoding, resulting in two-dimensional semantic vectors and the loss of hierarchical semantic information from Transformer blocks. Moreover, this limited structure of semantic vectors is akin to a flattened landscape, which restricts the methods that can be applied in downstream modeling, as they can only navigate this flat terrain. To address this issue, we propose a novel 3D Siamese network for text semantic similarity modeling, which maps semantic information to a higher-dimensional space. The three-dimensional semantic tensors not only retains more precise spatial and feature domain information but also provides the necessary structural condition for comprehensive downstream modeling strategies to capture them. Leveraging this structural advantage, we introduce several modules to reinforce this 3D framework, focusing on three aspects: feature extraction, attention, and feature fusion. Our extensive experiments on four text semantic similarity benchmarks demonstrate the effectiveness and efficiency of our 3D Siamese Network.