 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Text Semantic Similarity Modeling through a 3D Siamese Network
Paper and Code
Jul 18, 2023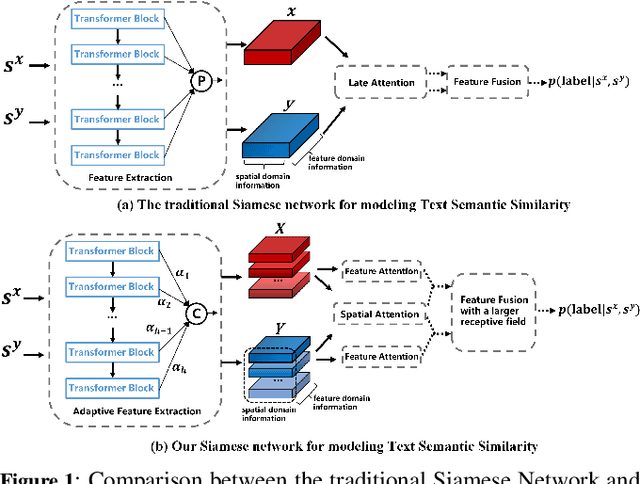
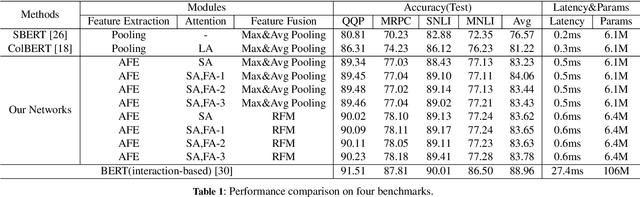
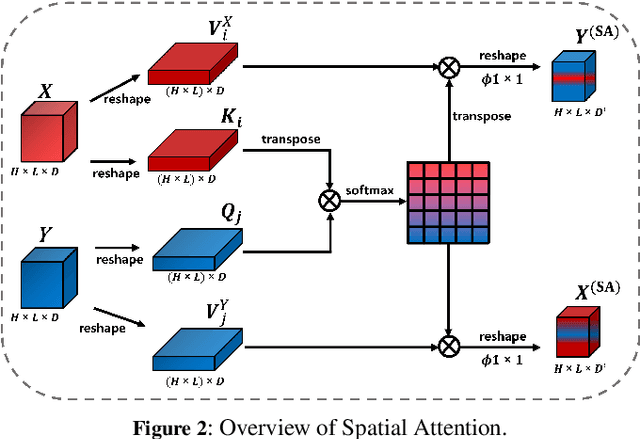
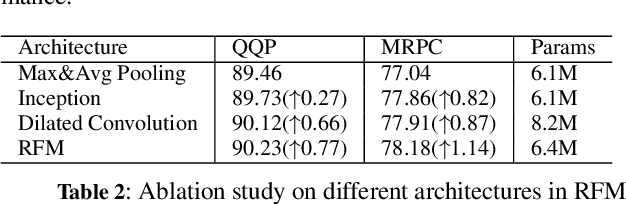
Siamese networks have gained popularity as a method for modeling text semantic similarity. Traditional methods rely on pooling operation to compress the semantic representations from Transformer blocks in encoding, resulting in two-dimensional semantic vectors and the loss of hierarchical semantic information from Transformer blocks. Moreover, this limited structure of semantic vectors is akin to a flattened landscape, which restricts the methods that can be applied in downstream modeling, as they can only navigate this flat terrain. To address this issue, we propose a novel 3D Siamese network for text semantic similarity modeling, which maps semantic information to a higher-dimensional space. The three-dimensional semantic tensors not only retains more precise spatial and feature domain information but also provides the necessary structural condition for comprehensive downstream modeling strategies to capture them. Leveraging this structural advantage, we introduce several modules to reinforce this 3D framework, focusing on three aspects: feature extraction, attention, and feature fusion. Our extensive experiments on four text semantic similarity benchmarks demonstrate the effectiveness and efficiency of our 3D Siamese Network.