 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Weaknesses of Backdoor-based Model Watermarking: An Information-theoretic Perspective
Sep 10, 2024

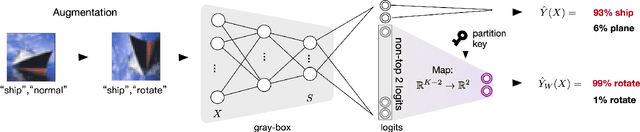
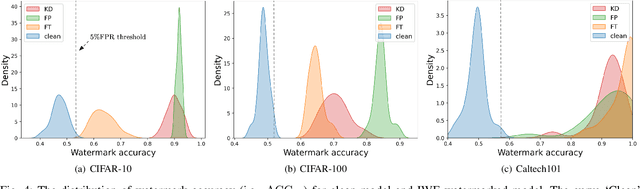
Safeguarding the intellectual property of machine learning models has emerged as a pressing concern in AI security. Model watermarking is a powerful technique for protecting ownership of machine learning models, yet its reliability has been recently challenged by recent watermark removal attacks. In this work, we investigate why existing watermark embedding techniques particularly those based on backdooring are vulnerable. Through an information-theoretic analysis, we show that the resilience of watermarking against erasure attacks hinges on the choice of trigger-set samples, where current uses of out-distribution trigger-set are inherently vulnerable to white-box adversaries. Based on this discovery, we propose a novel model watermarking scheme, In-distribution Watermark Embedding (IWE), to overcome the limitations of existing method. To further minimise the gap to clean models, we analyze the role of logits as watermark information carriers and propose a new approach to better conceal watermark information within the logits. Experiments on real-world datasets including CIFAR-100 and Caltech-101 demonstrate that our method robustly defends against various adversaries with negligible accuracy loss (< 0.1%).
Research on Dangerous Flight Weather Prediction based on Machine Learning
Jun 18, 2024
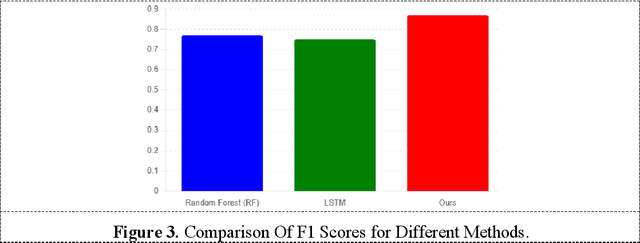
With the continuous expansion of the scale of air transport, the demand for aviation meteorological support also continues to grow. The impact of hazardous weather on flight safety is critical. How to effectively use meteorological data to improve the early warning capability of flight dangerous weather and ensure the safe flight of aircraft is the primary task of aviation meteorological services. In this work, support vector machine (SVM) models are used to predict hazardous flight weather, especially for meteorological conditions with high uncertainty such as storms and turbulence. SVM is a supervised learning method that distinguishes between different classes of data by finding optimal decision boundaries in a high-dimensional space. In order to meet the needs of this study, we chose the radial basis function (RBF) as the kernel function, which helps to deal with nonlinear problems and enables the model to better capture complex meteorological data structures. During the model training phase, we used historical meteorological observations from multiple weather stations, including temperature, humidity, wind speed, wind direction, and other meteorological indicators closely related to flight safety. From this data, the SVM model learns how to distinguish between normal and dangerous flight weather conditions.
Deep CSI Compression for Dual-Polarized Massive MIMO Channels with Disentangled Representation Learning
Mar 28, 2024Channel state information (CSI) feedback is critical for achieving the promised advantages of enhancing spectral and energy efficiencies in massive multiple-input multiple-output (MIMO) wireless communication systems. Deep learning (DL)-based methods have been proven effective in reducing the required signaling overhead for CSI feedback. In practical dual-polarized MIMO scenarios, channels in the vertical and horizontal polarization directions tend to exhibit high polarization correlation. To fully exploit the inherent propagation similarity within dual-polarized channels, we propose a disentangled representation neural network (NN) for CSI feedback, referred to as DiReNet. The proposed DiReNet disentangles dual-polarized CSI into three components: polarization-shared information, vertical polarization-specific information, and horizontal polarization-specific information. This disentanglement of dual-polarized CSI enables the minimization of information redundancy caused by the polarization correlation and improves the performance of CSI compression and recovery. Additionally, flexible quantization and network extension schemes are designed. Consequently, our method provides a pragmatic solution for CSI feedback to harness the physical MIMO polarization as a priori information. Our experimental results show that the performance of our proposed DiReNet surpasses that of existing DL-based networks, while also effectively reducing the number of network parameters by nearly one third.
Self-information Domain-based Neural CSI Compression with Feature Coupling
Apr 30, 2023Deep learning (DL)-based channel state information (CSI) feedback methods compressed the CSI matrix by exploiting its delay and angle features straightforwardly, while the measure in terms of information contained in the CSI matrix has rarely been considered. Based on this observation, we introduce self-information as an informative CSI representation from the perspective of information theory, which reflects the amount of information of the original CSI matrix in an explicit way. Then, a novel DL-based network is proposed for temporal CSI compression in the self-information domain, namely SD-CsiNet. The proposed SD-CsiNet projects the raw CSI onto a self-information matrix in the newly-defined self-information domain, extracts both temporal and spatial features of the self-information matrix, and then couples these two features for effective compression. Experimental results verify the effectiveness of the proposed SD-CsiNet by exploiting the self-information of CSI. Particularly for compression ratios 1/8 and 1/16, the SD-CsiNet respectively achieves 7.17 dB and 3.68 dB performance gains compared to state-of-the-art methods.
Understanding and Improving Deep Graph Neural Networks: A Probabilistic Graphical Model Perspective
Jan 25, 2023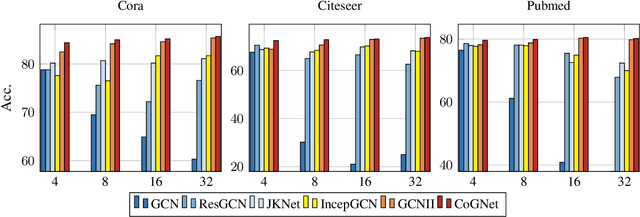
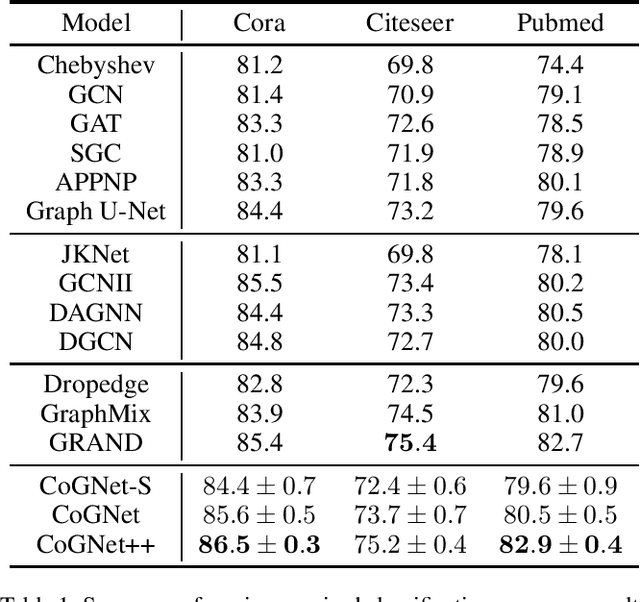

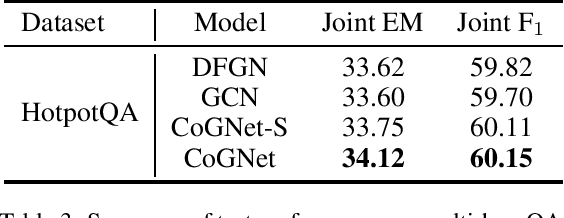
Recently, graph-based models designed for downstream tasks have significantly advanced research on graph neural networks (GNNs). GNN baselines based on neural message-passing mechanisms such as GCN and GAT perform worse as the network deepens. Therefore, numerous GNN variants have been proposed to tackle this performance degradation problem, including many deep GNNs. However, a unified framework is still lacking to connect these existing models and interpret their effectiveness at a high level. In this work, we focus on deep GNNs and propose a novel view for understanding them. We establish a theoretical framework via inference on a probabilistic graphical model. Given the fixed point equation (FPE) derived from the variational inference on the Markov random fields, the deep GNNs, including JKNet, GCNII, DGCN, and the classical GNNs, such as GCN, GAT, and APPNP, can be regarded as different approximations of the FPE. Moreover, given this framework, more accurate approximations of FPE are brought, guiding us to design a more powerful GNN: coupling graph neural network (CoGNet). Extensive experiments are carried out on citation networks and natural language processing downstream tasks. The results demonstrate that the CoGNet outperforms the SOTA models.
Disentangled Representation Learning for RF Fingerprint Extraction under Unknown Channel Statistics
Aug 04, 2022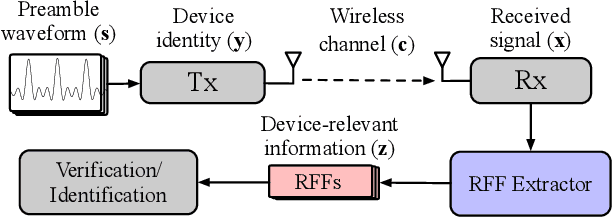
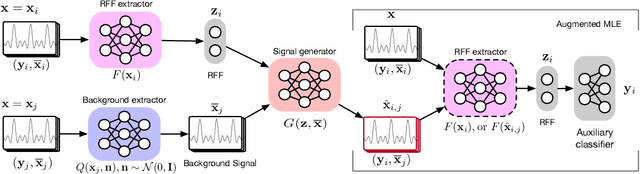

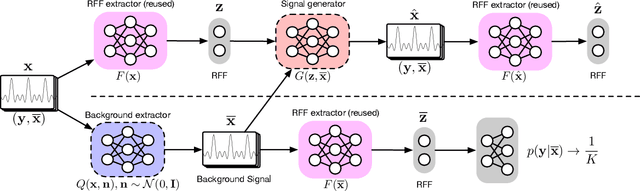
Deep learning (DL) applied to a device's radio-frequency fingerprint~(RFF) has attracted significant attention in physical-layer authentications due to its extraordinary classification performance. Conventional DL-RFF techniques, trained by adopting maximum likelihood estimation~(MLE), tend to overfit the channel statistics embedded in the training dataset. This restricts their practical applications as it is challenging to collect sufficient training data capturing the characteristics of all possible wireless channel environments. To address this challenge, we propose a DL framework of disentangled representation learning~(DRL) that first learns to factor the input signals into a device-relevant component and a device-irrelevant component via adversarial learning. Then, it synthesizes a set of augmented signals by shuffling these two parts within a given training dataset for training of subsequent RFF extractor. The implicit data augmentation in the proposed framework imposes a regularization on the RFF extractor to avoid the possible overfitting of device-irrelevant channel statistics, without collecting additional data from unknown channels. Experiments validate that the proposed approach, referred to as DR-RFF, outperforms conventional methods in terms of generalizability to unknown complicated propagation environments, e.g., dispersive multipath fading channels, even though all the training data are collected in a simple environment with dominated direct line-of-sight~(LoS) propagation paths.
Deep CSI Compression for Massive MIMO: A Self-information Model-driven Neural Network
Apr 25, 2022
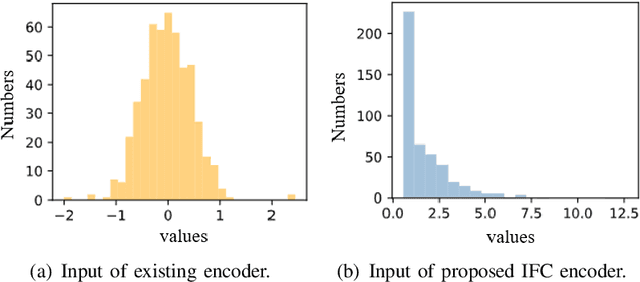
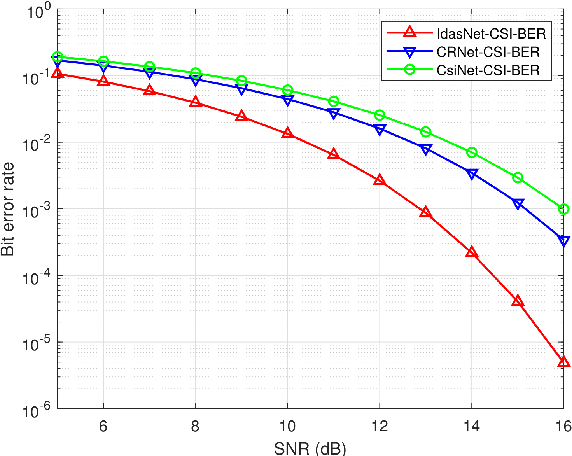
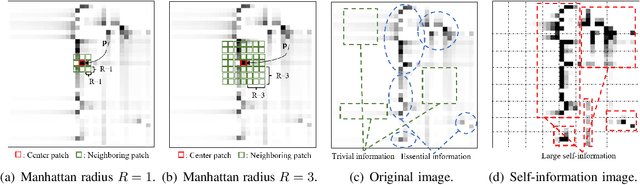
In order to fully exploit the advantages of massive multiple-input multiple-output (mMIMO), it is critical for the transmitter to accurately acquire the channel state information (CSI). Deep learning (DL)-based methods have been proposed for CSI compression and feedback to the transmitter. Although most existing DL-based methods consider the CSI matrix as an image, structural features of the CSI image are rarely exploited in neural network design. As such, we propose a model of self-information that dynamically measures the amount of information contained in each patch of a CSI image from the perspective of structural features. Then, by applying the self-information model, we propose a model-and-data-driven network for CSI compression and feedback, namely IdasNet. The IdasNet includes the design of a module of self-information deletion and selection (IDAS), an encoder of informative feature compression (IFC), and a decoder of informative feature recovery (IFR). In particular, the model-driven module of IDAS pre-compresses the CSI image by removing informative redundancy in terms of the self-information. The encoder of IFC then conducts feature compression to the pre-compressed CSI image and generates a feature codeword which contains two components, i.e., codeword values and position indices of the codeword values. Subsequently, the IFR decoder decouples the codeword values as well as position indices to recover the CSI image. Experimental results verify that the proposed IdasNet noticeably outperforms existing DL-based networks under various compression ratios while it has the number of network parameters reduced by orders-of-magnitude compared with various existing methods.
A Generalizable Model-and-Data Driven Approach for Open-Set RFF Authentication
Aug 10, 2021
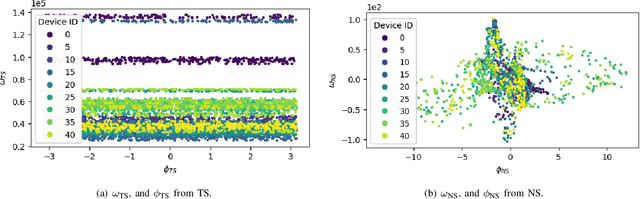

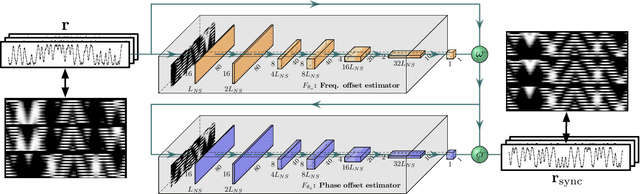
Radio-frequency fingerprints~(RFFs) are promising solutions for realizing low-cost physical layer authentication. Machine learning-based methods have been proposed for RFF extraction and discrimination. However, most existing methods are designed for the closed-set scenario where the set of devices is remains unchanged. These methods can not be generalized to the RFF discrimination of unknown devices. To enable the discrimination of RFF from both known and unknown devices, we propose a new end-to-end deep learning framework for extracting RFFs from raw received signals. The proposed framework comprises a novel preprocessing module, called neural synchronization~(NS), which incorporates the data-driven learning with signal processing priors as an inductive bias from communication-model based processing. Compared to traditional carrier synchronization techniques, which are static, this module estimates offsets by two learnable deep neural networks jointly trained by the RFF extractor. Additionally, a hypersphere representation is proposed to further improve the discrimination of RFF. Theoretical analysis shows that such a data-and-model framework can better optimize the mutual information between device identity and the RFF, which naturally leads to better performance. Experimental results verify that the proposed RFF significantly outperforms purely data-driven DNN-design and existing handcrafted RFF methods in terms of both discrimination and network generalizability.
Unsupervised Classification of Street Architectures Based on InfoGAN
May 30, 2019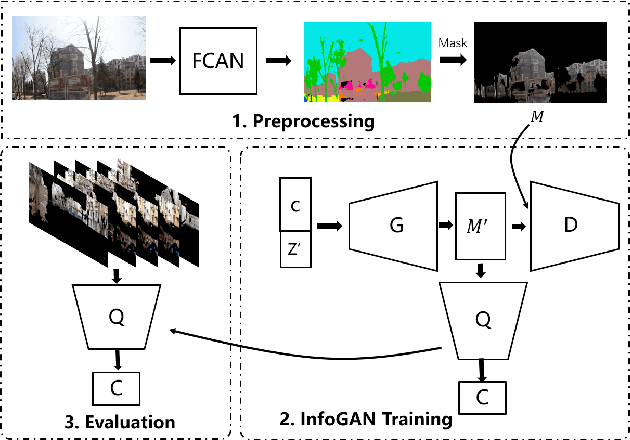
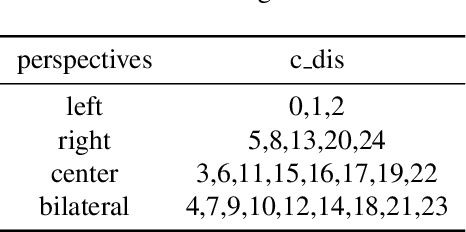

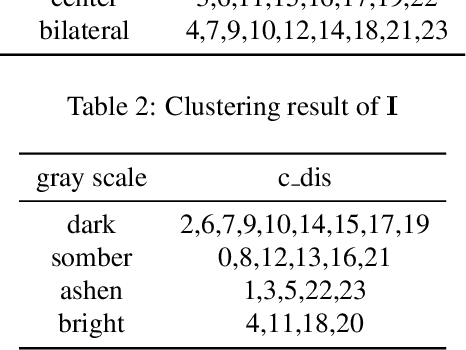
Street architectures play an essential role in city image and streetscape analysing. However, existing approaches are all supervised which require costly labeled data. To solve this, we propose a street architectural unsupervised classification framework based on Information maximizing Generative Adversarial Nets (InfoGAN), in which we utilize the auxiliary distribution $Q$ of InfoGAN as an unsupervised classifier. Experiments on database of true street view images in Nanjing, China validate the practicality and accuracy of our framework. Furthermore, we draw a series of heuristic conclusions from the intrinsic information hidden in true images. These conclusions will assist planners to know the architectural categories better.
A Deep, Information-theoretic Framework for Robust Biometric Recognition
Feb 23, 2019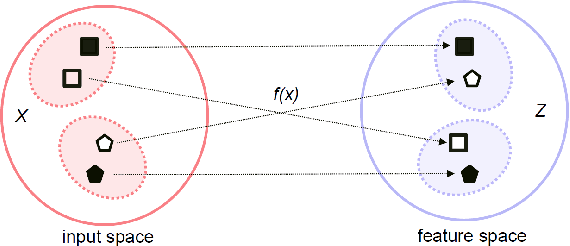

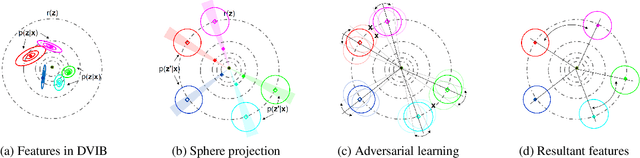

Deep neural networks (DNN) have been a de facto standard for nowadays biometric recognition solutions. A serious, but still overlooked problem in these DNN-based recognition systems is their vulnerability against adversarial attacks. Adversarial attacks can easily cause the output of a DNN system to greatly distort with only tiny changes in its input. Such distortions can potentially lead to an unexpected match between a valid biometric and a synthetic one constructed by a strategic attacker, raising security issue. In this work, we show how this issue can be resolved by learning robust biometric features through a deep, information-theoretic framework, which builds upon the recent deep variational information bottleneck method but is carefully adapted to biometric recognition tasks. Empirical evaluation demonstrates that our method not only offers stronger robustness against adversarial attacks but also provides better recognition performance over state-of-the-art approaches.