 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Weaknesses of Backdoor-based Model Watermarking: An Information-theoretic Perspective
Paper and Code


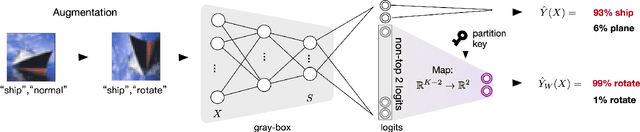
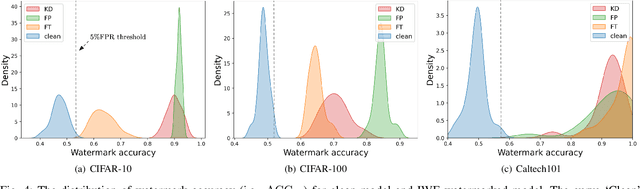
Safeguarding the intellectual property of machine learning models has emerged as a pressing concern in AI security. Model watermarking is a powerful technique for protecting ownership of machine learning models, yet its reliability has been recently challenged by recent watermark removal attacks. In this work, we investigate why existing watermark embedding techniques particularly those based on backdooring are vulnerable. Through an information-theoretic analysis, we show that the resilience of watermarking against erasure attacks hinges on the choice of trigger-set samples, where current uses of out-distribution trigger-set are inherently vulnerable to white-box adversaries. Based on this discovery, we propose a novel model watermarking scheme, In-distribution Watermark Embedding (IWE), to overcome the limitations of existing method. To further minimise the gap to clean models, we analyze the role of logits as watermark information carriers and propose a new approach to better conceal watermark information within the logits. Experiments on real-world datasets including CIFAR-100 and Caltech-101 demonstrate that our method robustly defends against various adversaries with negligible accuracy loss (< 0.1%).