 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoAtlas: A Foundation Model for Zero-Shot Statistical Dependence Estimate
May 29, 2026Measuring statistical dependency between high-dimensional random variables is a fundamental task in data science and machine learning. Neural mutual information (MI) estimators offer a promising avenue, but they typically require costly iterative optimization for each new dataset, making them impractical for real-time applications. We present InfoAtlas, a foundation model-like architecture that eliminates this bottleneck by directly inferring MI in a single forward pass. Pretrained on large-scale synthetic data with rich dependence patterns, InfoAtlas learns to identify diverse dependence structures and predict MI directly from the dataset. Comprehensive experiments demonstrate that InfoAtlas matches state-of-the-art neural estimators in accuracy while achieving $100\times$ speedup, can flexibly handle varying dimensions and sample sizes through a single unified model, and generalizes effectively to complex, real-world scenarios. By reformulating MI estimation as an inference task, InfoAtlas establishes a foundation for real-time dependency analysis.
ACON: Optimizing Context Compression for Long-horizon LLM Agents
Oct 01, 2025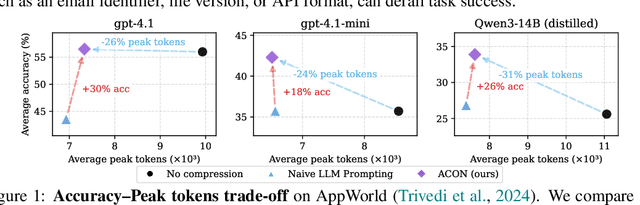
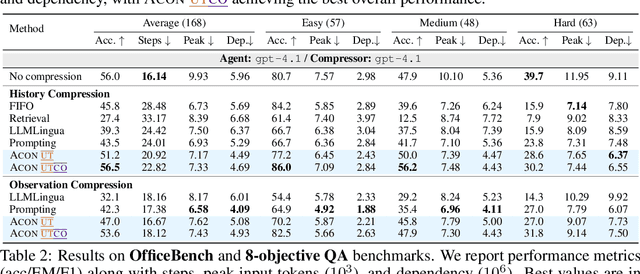
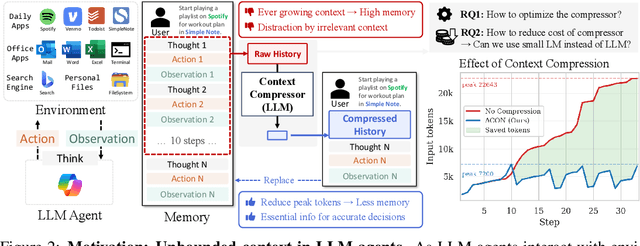
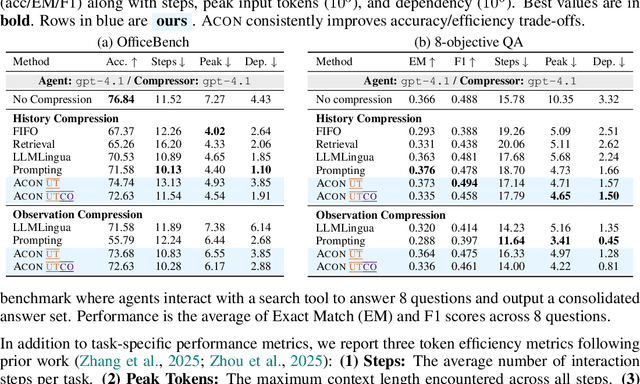
Large language models (LLMs) are increasingly deployed as agents in dynamic, real-world environments, where success requires both reasoning and effective tool use. A central challenge for agentic tasks is the growing context length, as agents must accumulate long histories of actions and observations. This expansion raises costs and reduces efficiency in long-horizon tasks, yet prior work on context compression has mostly focused on single-step tasks or narrow applications. We introduce Agent Context Optimization (ACON), a unified framework that optimally compresses both environment observations and interaction histories into concise yet informative condensations. ACON leverages compression guideline optimization in natural language space: given paired trajectories where full context succeeds but compressed context fails, capable LLMs analyze the causes of failure, and the compression guideline is updated accordingly. Furthermore, we propose distilling the optimized LLM compressor into smaller models to reduce the overhead of the additional module. Experiments on AppWorld, OfficeBench, and Multi-objective QA show that ACON reduces memory usage by 26-54% (peak tokens) while largely preserving task performance, preserves over 95% of accuracy when distilled into smaller compressors, and enhances smaller LMs as long-horizon agents with up to 46% performance improvement.
On Evaluating LLMs' Capabilities as Functional Approximators: A Bayesian Perspective
Oct 06, 2024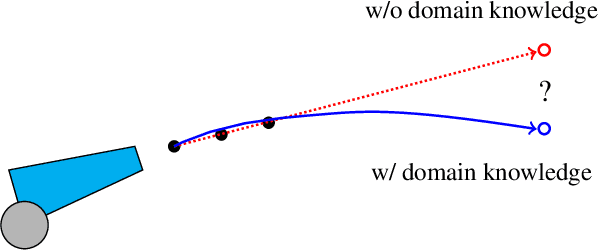


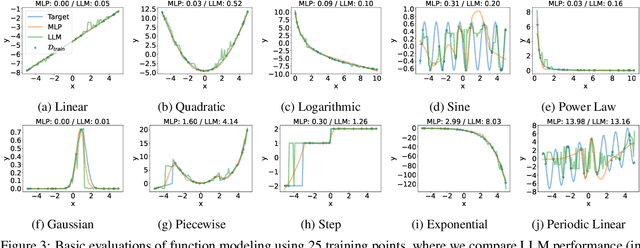
Recent works have successfully applied Large Language Models (LLMs) to function modeling tasks. However, the reasons behind this success remain unclear. In this work, we propose a new evaluation framework to comprehensively assess LLMs' function modeling abilities. By adopting a Bayesian perspective of function modeling, we discover that LLMs are relatively weak in understanding patterns in raw data, but excel at utilizing prior knowledge about the domain to develop a strong understanding of the underlying function. Our findings offer new insights about the strengths and limitations of LLMs in the context of function modeling.
On the Weaknesses of Backdoor-based Model Watermarking: An Information-theoretic Perspective
Sep 10, 2024

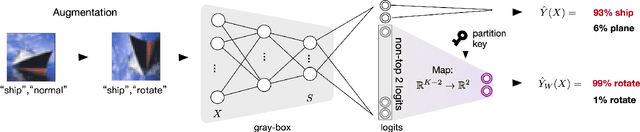
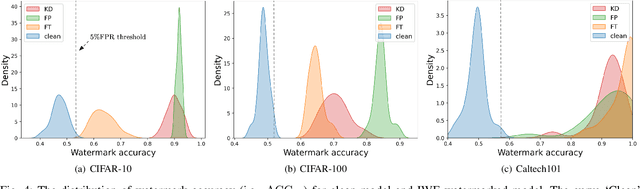
Safeguarding the intellectual property of machine learning models has emerged as a pressing concern in AI security. Model watermarking is a powerful technique for protecting ownership of machine learning models, yet its reliability has been recently challenged by recent watermark removal attacks. In this work, we investigate why existing watermark embedding techniques particularly those based on backdooring are vulnerable. Through an information-theoretic analysis, we show that the resilience of watermarking against erasure attacks hinges on the choice of trigger-set samples, where current uses of out-distribution trigger-set are inherently vulnerable to white-box adversaries. Based on this discovery, we propose a novel model watermarking scheme, In-distribution Watermark Embedding (IWE), to overcome the limitations of existing method. To further minimise the gap to clean models, we analyze the role of logits as watermark information carriers and propose a new approach to better conceal watermark information within the logits. Experiments on real-world datasets including CIFAR-100 and Caltech-101 demonstrate that our method robustly defends against various adversaries with negligible accuracy loss (< 0.1%).
Mutual Information Multinomial Estimation
Aug 18, 2024Estimating mutual information (MI) is a fundamental yet challenging task in data science and machine learning. This work proposes a new estimator for mutual information. Our main discovery is that a preliminary estimate of the data distribution can dramatically help estimate. This preliminary estimate serves as a bridge between the joint and the marginal distribution, and by comparing with this bridge distribution we can easily obtain the true difference between the joint distributions and the marginal distributions. Experiments on diverse tasks including non-Gaussian synthetic problems with known ground-truth and real-world applications demonstrate the advantages of our method.
Scalable Infomin Learning
Feb 21, 2023The task of infomin learning aims to learn a representation with high utility while being uninformative about a specified target, with the latter achieved by minimising the mutual information between the representation and the target. It has broad applications, ranging from training fair prediction models against protected attributes, to unsupervised learning with disentangled representations. Recent works on infomin learning mainly use adversarial training, which involves training a neural network to estimate mutual information or its proxy and thus is slow and difficult to optimise. Drawing on recent advances in slicing techniques, we propose a new infomin learning approach, which uses a novel proxy metric to mutual information. We further derive an accurate and analytically computable approximation to this proxy metric, thereby removing the need of constructing neural network-based mutual information estimators. Experiments on algorithmic fairness, disentangled representation learning and domain adaptation verify that our method can effectively remove unwanted information with limited time budget.
A Generalizable Model-and-Data Driven Approach for Open-Set RFF Authentication
Aug 10, 2021
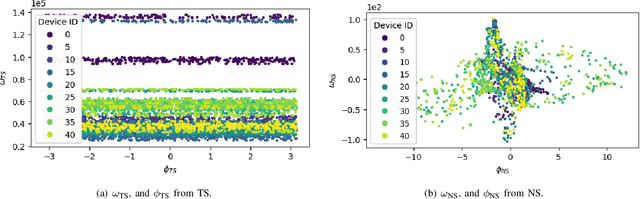

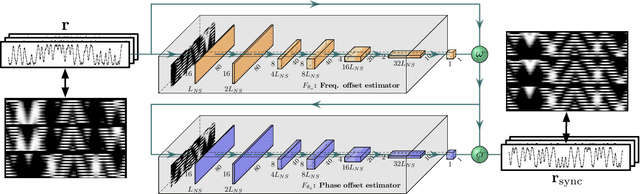
Radio-frequency fingerprints~(RFFs) are promising solutions for realizing low-cost physical layer authentication. Machine learning-based methods have been proposed for RFF extraction and discrimination. However, most existing methods are designed for the closed-set scenario where the set of devices is remains unchanged. These methods can not be generalized to the RFF discrimination of unknown devices. To enable the discrimination of RFF from both known and unknown devices, we propose a new end-to-end deep learning framework for extracting RFFs from raw received signals. The proposed framework comprises a novel preprocessing module, called neural synchronization~(NS), which incorporates the data-driven learning with signal processing priors as an inductive bias from communication-model based processing. Compared to traditional carrier synchronization techniques, which are static, this module estimates offsets by two learnable deep neural networks jointly trained by the RFF extractor. Additionally, a hypersphere representation is proposed to further improve the discrimination of RFF. Theoretical analysis shows that such a data-and-model framework can better optimize the mutual information between device identity and the RFF, which naturally leads to better performance. Experimental results verify that the proposed RFF significantly outperforms purely data-driven DNN-design and existing handcrafted RFF methods in terms of both discrimination and network generalizability.
Do Concept Bottleneck Models Learn as Intended?
May 10, 2021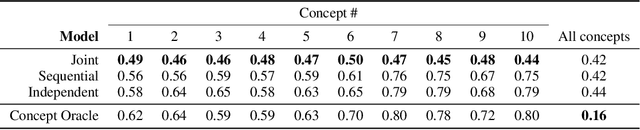
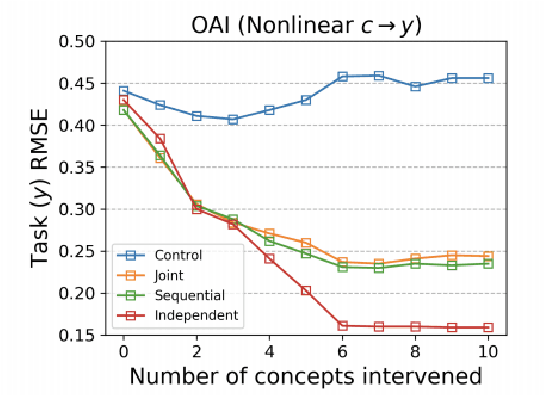
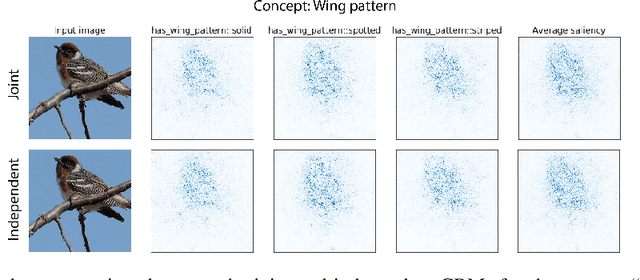
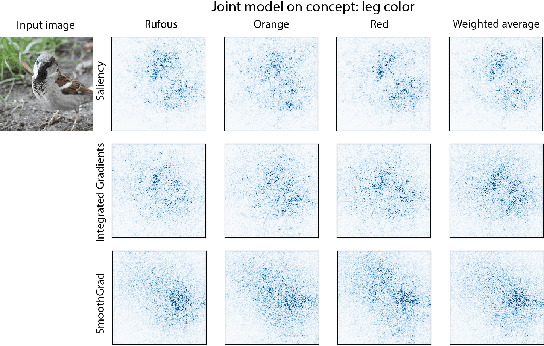
Concept bottleneck models map from raw inputs to concepts, and then from concepts to targets. Such models aim to incorporate pre-specified, high-level concepts into the learning procedure, and have been motivated to meet three desiderata: interpretability, predictability, and intervenability. However, we find that concept bottleneck models struggle to meet these goals. Using post hoc interpretability methods, we demonstrate that concepts do not correspond to anything semantically meaningful in input space, thus calling into question the usefulness of concept bottleneck models in their current form.
Neural Approximate Sufficient Statistics for Implicit Models
Oct 20, 2020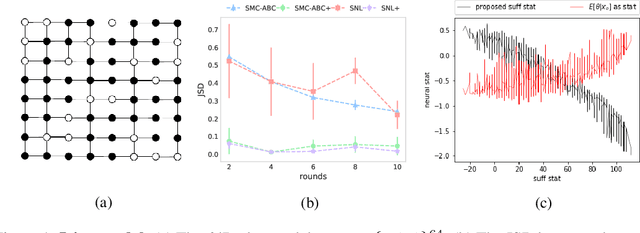

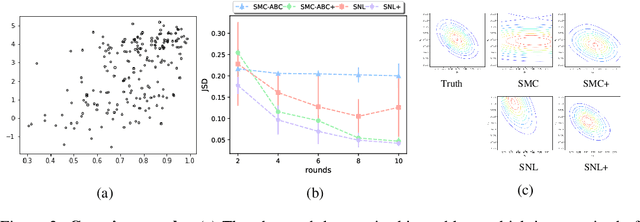

We consider the fundamental problem of how to automatically construct summary statistics for implicit generative models where the evaluation of likelihood function is intractable but sampling / simulating data from the model is possible. The idea is to frame the task of constructing sufficient statistics as learning mutual information maximizing representation of the data. This representation is computed by a deep neural network trained by a joint statistic-posterior learning strategy. We apply our approach to both traditional approximate Bayesian computation (ABC) and recent neural likelihood approaches, boosting their performance on a range of tasks.
Adaptive Gaussian Copula ABC
Feb 27, 2019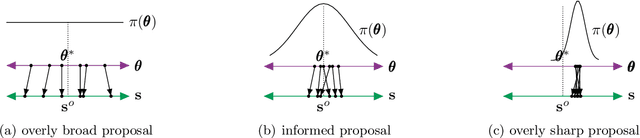

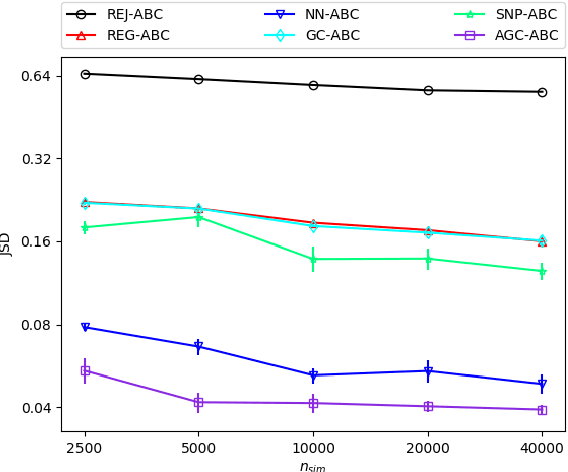

Approximate Bayesian computation (ABC) is a set of techniques for Bayesian inference when the likelihood is intractable but sampling from the model is possible. This work presents a simple yet effective ABC algorithm based on the combination of two classical ABC approaches --- regression ABC and sequential ABC. The key idea is that rather than learning the posterior directly, we first target another auxiliary distribution that can be learned accurately by existing methods, through which we then subsequently learn the desired posterior with the help of a Gaussian copula. During this process, the complexity of the model changes adaptively according to the data at hand. Experiments on a synthetic dataset as well as three real-world inference tasks demonstrates that the proposed method is fast, accurate, and easy to use.