 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree energy Estimation on Any State Space
May 29, 2026Free energy estimation is a fundamental yet challenging problem, from physics to statistics. Classical approaches rely on thermodynamic transformations, ranging from direct estimation, quasistatic integration, to finite-time averaging. Recent work [He and Du et al., 2025] learns neural transports to significantly accelerate the efficiency in the finite-time regime. In this paper, we generalize this framework to arbitrary state spaces. Building on this view, we develop a generalized neural transport learning approach for efficient estimation. Experiments validate the effectiveness and efficiency of the proposed method beyond continuous settings, extending to discrete and multimodal spaces as well as autoregressive settings. Beyond free energy estimation, we establish algebraic identities and reveal a group-theoretic structure linking infinitesimal time reversal and generalized Doob's $h$-transforms, showing that their compositions form a generalized dihedral group.
Diffusion Alignment Beyond KL: Variance Minimisation as Effective Policy Optimiser
Feb 12, 2026Diffusion alignment adapts pretrained diffusion models to sample from reward-tilted distributions along the denoising trajectory. This process naturally admits a Sequential Monte Carlo (SMC) interpretation, where the denoising model acts as a proposal and reward guidance induces importance weights. Motivated by this view, we introduce Variance Minimisation Policy Optimisation (VMPO), which formulates diffusion alignment as minimising the variance of log importance weights rather than directly optimising a Kullback-Leibler (KL) based objective. We prove that the variance objective is minimised by the reward-tilted target distribution and that, under on-policy sampling, its gradient coincides with that of standard KL-based alignment. This perspective offers a common lens for understanding diffusion alignment. Under different choices of potential functions and variance minimisation strategies, VMPO recovers various existing methods, while also suggesting new design directions beyond KL.
VarDiU: A Variational Diffusive Upper Bound for One-Step Diffusion Distillation
Aug 28, 2025
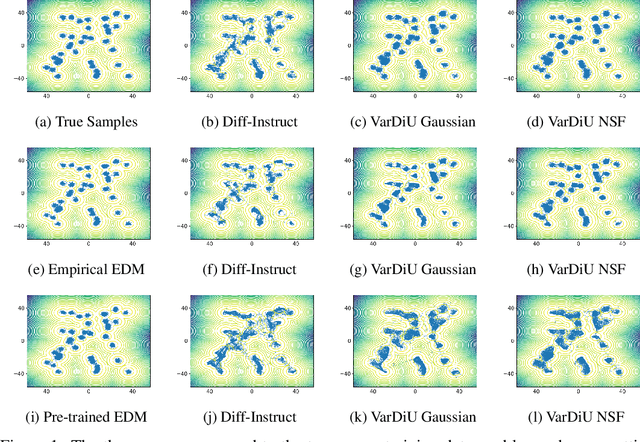


Recently, diffusion distillation methods have compressed thousand-step teacher diffusion models into one-step student generators while preserving sample quality. Most existing approaches train the student model using a diffusive divergence whose gradient is approximated via the student's score function, learned through denoising score matching (DSM). Since DSM training is imperfect, the resulting gradient estimate is inevitably biased, leading to sub-optimal performance. In this paper, we propose VarDiU (pronounced /va:rdju:/), a Variational Diffusive Upper Bound that admits an unbiased gradient estimator and can be directly applied to diffusion distillation. Using this objective, we compare our method with Diff-Instruct and demonstrate that it achieves higher generation quality and enables a more efficient and stable training procedure for one-step diffusion distillation.
Test-Time Alignment of Discrete Diffusion Models with Sequential Monte Carlo
May 28, 2025Discrete diffusion models have become highly effective across various domains. However, real-world applications often require the generative process to adhere to certain constraints but without task-specific fine-tuning. To this end, we propose a training-free method based on Sequential Monte Carlo (SMC) to sample from the reward-aligned target distribution at the test time. Our approach leverages twisted SMC with an approximate locally optimal proposal, obtained via a first-order Taylor expansion of the reward function. To address the challenge of ill-defined gradients in discrete spaces, we incorporate a Gumbel-Softmax relaxation, enabling efficient gradient-based approximation within the discrete generative framework. Empirical results on both synthetic datasets and image modelling validate the effectiveness of our approach.
Discrete Neural Flow Samplers with Locally Equivariant Transformer
May 23, 2025Sampling from unnormalised discrete distributions is a fundamental problem across various domains. While Markov chain Monte Carlo offers a principled approach, it often suffers from slow mixing and poor convergence. In this paper, we propose Discrete Neural Flow Samplers (DNFS), a trainable and efficient framework for discrete sampling. DNFS learns the rate matrix of a continuous-time Markov chain such that the resulting dynamics satisfy the Kolmogorov equation. As this objective involves the intractable partition function, we then employ control variates to reduce the variance of its Monte Carlo estimation, leading to a coordinate descent learning algorithm. To further facilitate computational efficiency, we propose locally equivaraint Transformer, a novel parameterisation of the rate matrix that significantly improves training efficiency while preserving powerful network expressiveness. Empirically, we demonstrate the efficacy of DNFS in a wide range of applications, including sampling from unnormalised distributions, training discrete energy-based models, and solving combinatorial optimisation problems.
Target Concrete Score Matching: A Holistic Framework for Discrete Diffusion
Apr 23, 2025



Discrete diffusion is a promising framework for modeling and generating discrete data. In this work, we present Target Concrete Score Matching (TCSM), a novel and versatile objective for training and fine-tuning discrete diffusion models. TCSM provides a general framework with broad applicability. It supports pre-training discrete diffusion models directly from data samples, and many existing discrete diffusion approaches naturally emerge as special cases of our more general TCSM framework. Furthermore, the same TCSM objective extends to post-training of discrete diffusion models, including fine-tuning using reward functions or preference data, and distillation of knowledge from pre-trained autoregressive models. These new capabilities stem from the core idea of TCSM, estimating the concrete score of the target distribution, which resides in the original (clean) data space. This allows seamless integration with reward functions and pre-trained models, which inherently only operate in the clean data space rather than the noisy intermediate spaces of diffusion processes. Our experiments on language modeling tasks demonstrate that TCSM matches or surpasses current methods. Additionally, TCSM is versatile, applicable to both pre-training and post-training scenarios, offering greater flexibility and sample efficiency.
TabRep: a Simple and Effective Continuous Representation for Training Tabular Diffusion Models
Apr 09, 2025Diffusion models have been the predominant generative model for tabular data generation. However, they face the conundrum of modeling under a separate versus a unified data representation. The former encounters the challenge of jointly modeling all multi-modal distributions of tabular data in one model. While the latter alleviates this by learning a single representation for all features, it currently leverages sparse suboptimal encoding heuristics and necessitates additional computation costs. In this work, we address the latter by presenting TabRep, a tabular diffusion architecture trained with a unified continuous representation. To motivate the design of our representation, we provide geometric insights into how the data manifold affects diffusion models. The key attributes of our representation are composed of its density, flexibility to provide ample separability for nominal features, and ability to preserve intrinsic relationships. Ultimately, TabRep provides a simple yet effective approach for training tabular diffusion models under a continuous data manifold. Our results showcase that TabRep achieves superior performance across a broad suite of evaluations. It is the first to synthesize tabular data that exceeds the downstream quality of the original datasets while preserving privacy and remaining computationally efficient.
Neural Flow Samplers with Shortcut Models
Feb 11, 2025Sampling from unnormalized densities is a fundamental task across various domains. Flow-based samplers generate samples by learning a velocity field that satisfies the continuity equation, but this requires estimating the intractable time derivative of the partition function. While importance sampling provides an approximation, it suffers from high variance. To mitigate this, we introduce a velocity-driven Sequential Monte Carlo method combined with control variates to reduce variance. Additionally, we incorporate a shortcut model to improve efficiency by minimizing the number of sampling steps. Empirical results on both synthetic datasets and $n$-body system targets validate the effectiveness of our approach.
Towards Training One-Step Diffusion Models Without Distillation
Feb 11, 2025



Recent advances in one-step generative models typically follow a two-stage process: first training a teacher diffusion model and then distilling it into a one-step student model. This distillation process traditionally relies on both the teacher model's score function to compute the distillation loss and its weights for student initialization. In this paper, we explore whether one-step generative models can be trained directly without this distillation process. First, we show that the teacher's score function is not essential and propose a family of distillation methods that achieve competitive results without relying on score estimation. Next, we demonstrate that initialization from teacher weights is indispensable in successful training. Surprisingly, we find that this benefit is not due to improved ``input-output" mapping but rather the learned feature representations, which dominate distillation quality. Our findings provide a better understanding of the role of initialization in one-step model training and its impact on distillation quality.
Energy-Based Modelling for Discrete and Mixed Data via Heat Equations on Structured Spaces
Dec 02, 2024



Energy-based models (EBMs) offer a flexible framework for probabilistic modelling across various data domains. However, training EBMs on data in discrete or mixed state spaces poses significant challenges due to the lack of robust and fast sampling methods. In this work, we propose to train discrete EBMs with Energy Discrepancy, a loss function which only requires the evaluation of the energy function at data points and their perturbed counterparts, thus eliminating the need for Markov chain Monte Carlo. We introduce perturbations of the data distribution by simulating a diffusion process on the discrete state space endowed with a graph structure. This allows us to inform the choice of perturbation from the structure of the modelled discrete variable, while the continuous time parameter enables fine-grained control of the perturbation. Empirically, we demonstrate the efficacy of the proposed approaches in a wide range of applications, including the estimation of discrete densities with non-binary vocabulary and binary image modelling. Finally, we train EBMs on tabular data sets with applications in synthetic data generation and calibrated classification.