 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery and Reinforcement of Tool-Integrated Reasoning Chains via Rollout Trees
Jan 13, 2026Tool-Integrated Reasoning has emerged as a key paradigm to augment Large Language Models (LLMs) with computational capabilities, yet integrating tool-use into long Chain-of-Thought (long CoT) remains underexplored, largely due to the scarcity of training data and the challenge of integrating tool-use without compromising the model's intrinsic long-chain reasoning. In this paper, we introduce DART (Discovery And Reinforcement of Tool-Integrated Reasoning Chains via Rollout Trees), a reinforcement learning framework that enables spontaneous tool-use during long CoT reasoning without human annotation. DART operates by constructing dynamic rollout trees during training to discover valid tool-use opportunities, branching out at promising positions to explore diverse tool-integrated trajectories. Subsequently, a tree-based process advantage estimation identifies and credits specific sub-trajectories where tool invocation positively contributes to the solution, effectively reinforcing these beneficial behaviors. Extensive experiments on challenging benchmarks like AIME and GPQA-Diamond demonstrate that DART significantly outperforms existing methods, successfully harmonizing tool execution with long CoT reasoning.
ConMax: Confidence-Maximizing Compression for Efficient Chain-of-Thought Reasoning
Jan 08, 2026Recent breakthroughs in Large Reasoning Models (LRMs) have demonstrated that extensive Chain-of-Thought (CoT) generation is critical for enabling intricate cognitive behaviors, such as self-verification and backtracking, to solve complex tasks. However, this capability often leads to ``overthinking'', where models generate redundant reasoning paths that inflate computational costs without improving accuracy. While Supervised Fine-Tuning (SFT) on reasoning traces is a standard paradigm for the 'cold start' phase, applying existing compression techniques to these traces often compromises logical coherence or incurs prohibitive sampling costs. In this paper, we introduce ConMax (Confidence-Maximizing Compression), a novel reinforcement learning framework designed to automatically compress reasoning traces while preserving essential reasoning patterns. ConMax formulates compression as a reward-driven optimization problem, training a policy to prune redundancy by maximizing a weighted combination of answer confidence for predictive fidelity and thinking confidence for reasoning validity through a frozen auxiliary LRM. Extensive experiments across five reasoning datasets demonstrate that ConMax achieves a superior efficiency-performance trade-off. Specifically, it reduces inference length by 43% over strong baselines at the cost of a mere 0.7% dip in accuracy, proving its effectiveness in generating high-quality, efficient training data for LRMs.
Adaptive Termination for Multi-round Parallel Reasoning: An Universal Semantic Entropy-Guided Framework
Jul 09, 2025Recent advances in large language models (LLMs) have accelerated progress toward artificial general intelligence, with inference-time scaling emerging as a key technique. Contemporary approaches leverage either sequential reasoning (iteratively extending chains of thought) or parallel reasoning (generating multiple solutions simultaneously) to scale inference. However, both paradigms face fundamental limitations: sequential scaling typically relies on arbitrary token budgets for termination, leading to inefficiency or premature cutoff; while parallel scaling often lacks coordination among parallel branches and requires intrusive fine-tuning to perform effectively. In light of these challenges, we aim to design a flexible test-time collaborative inference framework that exploits the complementary strengths of both sequential and parallel reasoning paradigms. Towards this goal, the core challenge lies in developing an efficient and accurate intrinsic quality metric to assess model responses during collaborative inference, enabling dynamic control and early termination of the reasoning trace. To address this challenge, we introduce semantic entropy (SE), which quantifies the semantic diversity of parallel model responses and serves as a robust indicator of reasoning quality due to its strong negative correlation with accuracy...
A Survey of Personalized Large Language Models: Progress and Future Directions
Feb 17, 2025Large Language Models (LLMs) excel in handling general knowledge tasks, yet they struggle with user-specific personalization, such as understanding individual emotions, writing styles, and preferences. Personalized Large Language Models (PLLMs) tackle these challenges by leveraging individual user data, such as user profiles, historical dialogues, content, and interactions, to deliver responses that are contextually relevant and tailored to each user's specific needs. This is a highly valuable research topic, as PLLMs can significantly enhance user satisfaction and have broad applications in conversational agents, recommendation systems, emotion recognition, medical assistants, and more. This survey reviews recent advancements in PLLMs from three technical perspectives: prompting for personalized context (input level), finetuning for personalized adapters (model level), and alignment for personalized preferences (objective level). To provide deeper insights, we also discuss current limitations and outline several promising directions for future research. Updated information about this survey can be found at the https://github.com/JiahongLiu21/Awesome-Personalized-Large-Language-Models.
Entropy-Based Decoding for Retrieval-Augmented Large Language Models
Jun 25, 2024Augmenting Large Language Models (LLMs) with retrieved external knowledge has proven effective for improving the factual accuracy of generated responses. Despite their success, retrieval-augmented LLMs still face the distractibility issue, where the generated responses are negatively influenced by noise from both external and internal knowledge sources. In this paper, we introduce a novel, training-free decoding method guided by entropy considerations to mitigate this issue. Our approach utilizes entropy-based document-parallel ensemble decoding to prioritize low-entropy distributions from retrieved documents, thereby enhancing the extraction of relevant information of context. Additionally, it incorporates a contrastive decoding mechanism that contrasts the obtained low-entropy ensemble distribution with the high-entropy distribution derived from the model's internal knowledge across layers, which ensures a greater emphasis on reliable external information. Extensive experiments on open-domain question answering datasets demonstrate the superiority of our method.
Contrastive Quantization based Semantic Code for Generative Recommendation
Apr 23, 2024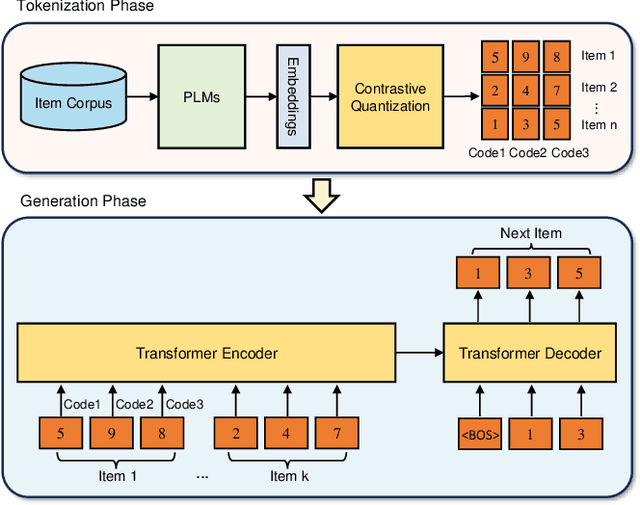
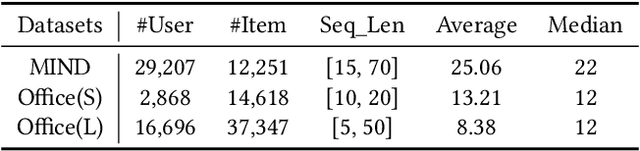
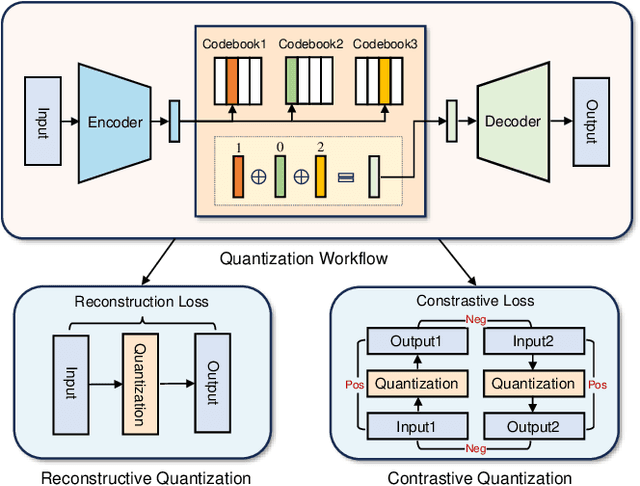

With the success of large language models, generative retrieval has emerged as a new retrieval technique for recommendation. It can be divided into two stages: the first stage involves constructing discrete Codes (i.e., codes), and the second stage involves decoding the code sequentially via the transformer architecture. Current methods often construct item semantic codes by reconstructing based quantization on item textual representation, but they fail to capture item discrepancy that is essential in modeling item relationships in recommendation sytems. In this paper, we propose to construct the code representation of items by simultaneously considering both item relationships and semantic information. Specifically, we employ a pre-trained language model to extract item's textual description and translate it into item's embedding. Then we propose to enhance the encoder-decoder based RQVAE model with contrastive objectives to learn item code. To be specific, we employ the embeddings generated by the decoder from the samples themselves as positive instances and those from other samples as negative instances. Thus we effectively enhance the item discrepancy across all items, better preserving the item neighbourhood. Finally, we train and test semantic code with with generative retrieval on a sequential recommendation model. Our experiments demonstrate that our method improves NDCG@5 with 43.76% on the MIND dataset and Recall@10 with 80.95% on the Office dataset compared to the previous baselines.
CLongEval: A Chinese Benchmark for Evaluating Long-Context Large Language Models
Mar 06, 2024Developing Large Language Models (LLMs) with robust long-context capabilities has been the recent research focus, resulting in the emergence of long-context LLMs proficient in Chinese. However, the evaluation of these models remains underdeveloped due to a lack of benchmarks. To address this gap, we present CLongEval, a comprehensive Chinese benchmark for evaluating long-context LLMs. CLongEval is characterized by three key features: (1) Sufficient data volume, comprising 7 distinct tasks and 7,267 examples; (2) Broad applicability, accommodating to models with context windows size from 1K to 100K; (3) High quality, with over 2,000 manually annotated question-answer pairs in addition to the automatically constructed labels. With CLongEval, we undertake a comprehensive assessment of 6 open-source long-context LLMs and 2 leading commercial counterparts that feature both long-context abilities and proficiency in Chinese. We also provide in-depth analysis based on the empirical results, trying to shed light on the critical capabilities that present challenges in long-context settings. The dataset, evaluation scripts, and model outputs will be released.
HiHPQ: Hierarchical Hyperbolic Product Quantization for Unsupervised Image Retrieval
Jan 14, 2024



Existing unsupervised deep product quantization methods primarily aim for the increased similarity between different views of the identical image, whereas the delicate multi-level semantic similarities preserved between images are overlooked. Moreover, these methods predominantly focus on the Euclidean space for computational convenience, compromising their ability to map the multi-level semantic relationships between images effectively. To mitigate these shortcomings, we propose a novel unsupervised product quantization method dubbed \textbf{Hi}erarchical \textbf{H}yperbolic \textbf{P}roduct \textbf{Q}uantization (HiHPQ), which learns quantized representations by incorporating hierarchical semantic similarity within hyperbolic geometry. Specifically, we propose a hyperbolic product quantizer, where the hyperbolic codebook attention mechanism and the quantized contrastive learning on the hyperbolic product manifold are introduced to expedite quantization. Furthermore, we propose a hierarchical semantics learning module, designed to enhance the distinction between similar and non-matching images for a query by utilizing the extracted hierarchical semantics as an additional training supervision. Experiments on benchmarks show that our proposed method outperforms state-of-the-art baselines.
Learning Summary-Worthy Visual Representation for Abstractive Summarization in Video
May 08, 2023Multimodal abstractive summarization for videos (MAS) requires generating a concise textual summary to describe the highlights of a video according to multimodal resources, in our case, the video content and its transcript. Inspired by the success of the large-scale generative pre-trained language model (GPLM) in generating high-quality textual content (e.g., summary), recent MAS methods have proposed to adapt the GPLM to this task by equipping it with the visual information, which is often obtained through a general-purpose visual feature extractor. However, the generally extracted visual features may overlook some summary-worthy visual information, which impedes model performance. In this work, we propose a novel approach to learning the summary-worthy visual representation that facilitates abstractive summarization. Our method exploits the summary-worthy information from both the cross-modal transcript data and the knowledge that distills from the pseudo summary. Extensive experiments on three public multimodal datasets show that our method outperforms all competing baselines. Furthermore, with the advantages of summary-worthy visual information, our model can have a significant improvement on small datasets or even datasets with limited training data.
Efficient Document Retrieval by End-to-End Refining and Quantizing BERT Embedding with Contrastive Product Quantization
Oct 31, 2022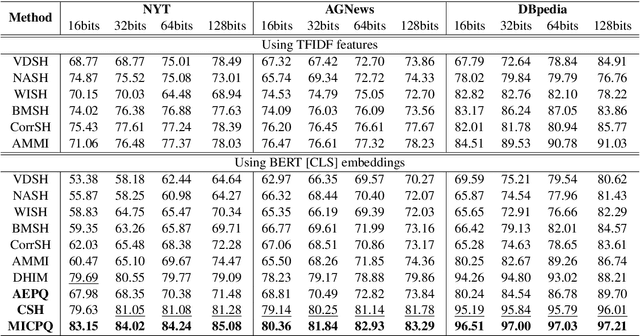
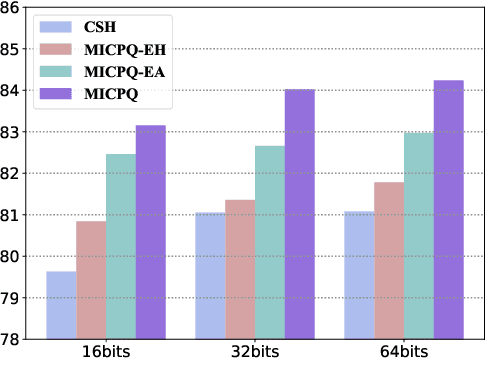
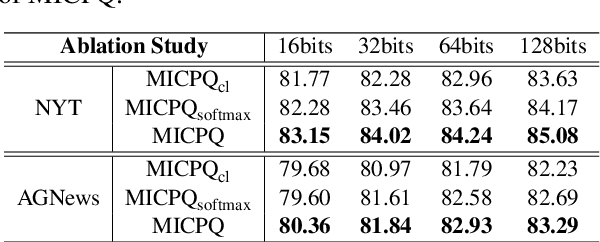
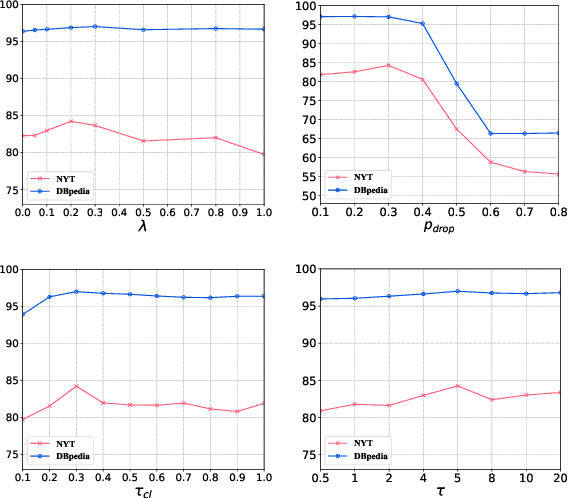
Efficient document retrieval heavily relies on the technique of semantic hashing, which learns a binary code for every document and employs Hamming distance to evaluate document distances. However, existing semantic hashing methods are mostly established on outdated TFIDF features, which obviously do not contain lots of important semantic information about documents. Furthermore, the Hamming distance can only be equal to one of several integer values, significantly limiting its representational ability for document distances. To address these issues, in this paper, we propose to leverage BERT embeddings to perform efficient retrieval based on the product quantization technique, which will assign for every document a real-valued codeword from the codebook, instead of a binary code as in semantic hashing. Specifically, we first transform the original BERT embeddings via a learnable mapping and feed the transformed embedding into a probabilistic product quantization module to output the assigned codeword. The refining and quantizing modules can be optimized in an end-to-end manner by minimizing the probabilistic contrastive loss. A mutual information maximization based method is further proposed to improve the representativeness of codewords, so that documents can be quantized more accurately. Extensive experiments conducted on three benchmarks demonstrate that our proposed method significantly outperforms current state-of-the-art baselines.