 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADE: Beyond Scoring via a Multilingual Agentic Diagnosing Engine for Fine-Grained Evaluation Insights
Jun 05, 2026Multilingual and multicultural benchmarks now cover dozens of languages and model families, but the resulting score landscapes remain metric-rich and insight-poor, necessitating fine-grained multilingual post-evaluation diagnosis. However, single LLMs and open-ended agents are easily swamped by the long, noisy diagnostic input, and no reusable taxonomy exists for it. To address this, we propose MADE, a Multilingual Agentic Diagnosing Engine that decomposes post-evaluation analysis into planning, aggregate analysis, instance-level case inspection, multilingual and cultural reflection, and grounded report synthesis. MADE is paired with an expert-led 54-query and 15-language diagnostic set, evaluated on top of a large-scale multilingual evaluation substrate (33 model families, 11 benchmarks, 26 languages, 34 cultures, 8.66M evaluation records). Experiments show that MADE outperforms the strongest shared baseline by 47% in diagnosis report quality and is preferred by human multilingual experts in 87.9% of pairwise comparisons. Applied with multilingual experts, MADE further surfaces four actionable findings on deployment, iteration, and cross-cultural pitfalls, turning benchmark score tables into model-selection and remediation guidance.
The GaoYao Benchmark: A Comprehensive Framework for Evaluating Multilingual and Multicultural Abilities of Large Language Models
Apr 22, 2026Evaluating the multilingual and multicultural capabilities of Large Language Models (LLMs) is essential for their global utility. However, current benchmarks face three critical limitations: (1) fragmented evaluation dimensions that often neglect deep cultural nuances; (2) insufficient language coverage in subjective tasks relying on low-quality machine translation; and (3) shallow analysis that lacks diagnostic depth beyond simple rankings. To address these, we introduce GaoYao, a comprehensive benchmark with 182.3k samples, 26 languages and 51 nations/areas. First, GaoYao proposes a unified framework categorizing evaluation tasks into three cultural layers (General Multilingual, Cross-cultural, Monocultural) and nine cognitive sub-layers. Second, we achieve native-quality expansion by leveraging experts to rigorously localize subjective benchmarks into 19 languages and synthesizing cross-cultural test sets for 34 cultures, surpassing prior coverage by up to 111%. Third, we conduct an in-depth diagnostic analysis on 20+ flagship and compact LLMs. Our findings reveal significant geographical performance disparities and distinct gaps between tasks, offering a reliable map for future work. We release the benchmark (https://github.com/lunyiliu/GaoYao).
MathAgent: Adversarial Evolution of Constraint Graphs for Mathematical Reasoning Data Synthesis
Apr 13, 2026Synthesizing high-quality mathematical reasoning data without human priors remains a significant challenge. Current approaches typically rely on seed data mutation or simple prompt engineering, often suffering from mode collapse and limited logical complexity. This paper proposes a hierarchical synthesis framework that formulates data synthesis as an unsupervised optimization problem over a constraint graph followed by semantic instantiation, rather than treating it as a direct text generation task. We introduce a Legislator-Executor paradigm: The Legislator adversarially evolves structured generation blueprints encoding the constraints of the problem, while the Executor instantiates these specifications into diverse natural language scenarios. This decoupling of skeleton design from linguistic realization enables a prioritized focus on constructing complex and diverse logical structures, thereby guiding high-quality data synthesis. Experiments conducted on a total of 10 models across the Qwen, Llama, Mistral, and Gemma series demonstrate that our method achieves notable results: models fine-tuned on 1K synthesized samples outperform widely-used datasets of comparable scale (LIMO, s1K) across eight mathematical benchmarks, exhibiting superior out-of-distribution generalization.
PACE: Defying the Scaling Hypothesis of Exploration in Iterative Alignment for Mathematical Reasoning
Feb 05, 2026Iterative Direct Preference Optimization has emerged as the state-of-the-art paradigm for aligning Large Language Models on reasoning tasks. Standard implementations (DPO-R1) rely on Best-of-N sampling (e.g., $N \ge 8$) to mine golden trajectories from the distribution tail. In this paper, we challenge this scaling hypothesis and reveal a counter-intuitive phenomenon: in mathematical reasoning, aggressive exploration yields diminishing returns and even catastrophic policy collapse. We theoretically demonstrate that scaling $N$ amplifies verifier noise and induces detrimental distribution shifts. To resolve this, we introduce \textbf{PACE} (Proximal Alignment via Corrective Exploration), which replaces brute-force mining with a generation-based corrective strategy. Operating with a minimal budget ($2<N<3$), PACE synthesizes high-fidelity preference pairs from failed explorations. Empirical evaluations show that PACE outperforms DPO-R1 $(N=16)$ while using only about $1/5$ of the compute, demonstrating superior robustness against reward hacking and label noise.
Pangu Pro MoE: Mixture of Grouped Experts for Efficient Sparsity
May 28, 2025The surgence of Mixture of Experts (MoE) in Large Language Models promises a small price of execution cost for a much larger model parameter count and learning capacity, because only a small fraction of parameters are activated for each input token. However, it is commonly observed that some experts are activated far more often than others, leading to system inefficiency when running the experts on different devices in parallel. Therefore, we introduce Mixture of Grouped Experts (MoGE), which groups the experts during selection and balances the expert workload better than MoE in nature. It constrains tokens to activate an equal number of experts within each predefined expert group. When a model execution is distributed on multiple devices, this architectural design ensures a balanced computational load across devices, significantly enhancing throughput, particularly for the inference phase. Further, we build Pangu Pro MoE on Ascend NPUs, a sparse model based on MoGE with 72 billion total parameters, 16 billion of which are activated for each token. The configuration of Pangu Pro MoE is optimized for Ascend 300I Duo and 800I A2 through extensive system simulation studies. Our experiments indicate that MoGE indeed leads to better expert load balancing and more efficient execution for both model training and inference on Ascend NPUs. The inference performance of Pangu Pro MoE achieves 1148 tokens/s per card and can be further improved to 1528 tokens/s per card by speculative acceleration, outperforming comparable 32B and 72B Dense models. Furthermore, we achieve an excellent cost-to-performance ratio for model inference on Ascend 300I Duo. Our studies show that Ascend NPUs are capable of training Pangu Pro MoE with massive parallelization to make it a leading model within the sub-100B total parameter class, outperforming prominent open-source models like GLM-Z1-32B and Qwen3-32B.
Pangu Light: Weight Re-Initialization for Pruning and Accelerating LLMs
May 26, 2025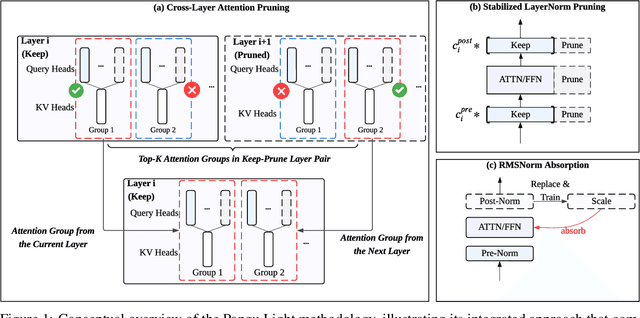

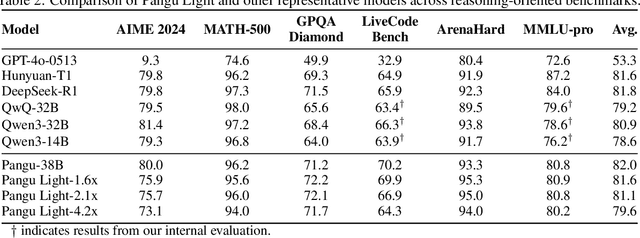
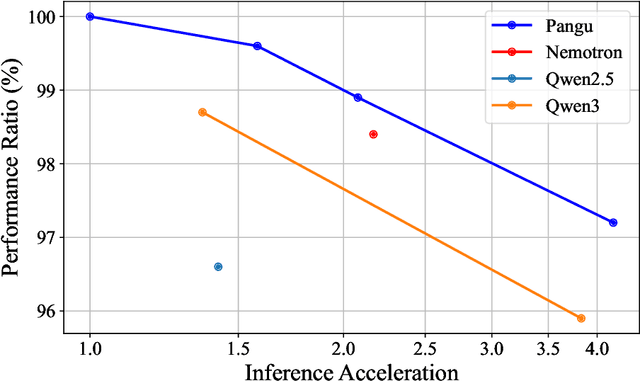
Large Language Models (LLMs) deliver state-of-the-art capabilities across numerous tasks, but their immense size and inference costs pose significant computational challenges for practical deployment. While structured pruning offers a promising avenue for model compression, existing methods often struggle with the detrimental effects of aggressive, simultaneous width and depth reductions, leading to substantial performance degradation. This paper argues that a critical, often overlooked, aspect in making such aggressive joint pruning viable is the strategic re-initialization and adjustment of remaining weights to improve the model post-pruning training accuracies. We introduce Pangu Light, a framework for LLM acceleration centered around structured pruning coupled with novel weight re-initialization techniques designed to address this ``missing piece''. Our framework systematically targets multiple axes, including model width, depth, attention heads, and RMSNorm, with its effectiveness rooted in novel re-initialization methods like Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP) that mitigate performance drops by providing the network a better training starting point. Further enhancing efficiency, Pangu Light incorporates specialized optimizations such as absorbing Post-RMSNorm computations and tailors its strategies to Ascend NPU characteristics. The Pangu Light models consistently exhibit a superior accuracy-efficiency trade-off, outperforming prominent baseline pruning methods like Nemotron and established LLMs like Qwen3 series. For instance, on Ascend NPUs, Pangu Light-32B's 81.6 average score and 2585 tokens/s throughput exceed Qwen3-32B's 80.9 average score and 2225 tokens/s.
Dynamic Sampling that Adapts: Iterative DPO for Self-Aware Mathematical Reasoning
May 22, 2025In the realm of data selection for reasoning tasks, existing approaches predominantly rely on externally predefined static metrics such as difficulty and diversity, which are often designed for supervised fine-tuning (SFT) and lack adaptability to continuous training processes. A critical limitation of these methods is their inability to dynamically align with the evolving capabilities of models during online training, a gap that becomes increasingly pronounced with the rise of dynamic training paradigms and online reinforcement learning (RL) frameworks (e.g., R1 models). To address this, we introduce SAI-DPO, an algorithm that dynamically selects training data by continuously assessing a model's stage-specific reasoning abilities across different training phases. By integrating real-time model performance feedback, SAI-DPO adaptively adapts data selection to the evolving strengths and weaknesses of the model, thus enhancing both data utilization efficiency and final task performance. Extensive experiments on three state-of-the-art models and eight mathematical reasoning benchmarks, including challenging competition-level datasets (e.g., AIME24 and AMC23), demonstrate that SAI-DPO achieves an average performance boost of up to 21.3 percentage points, with particularly notable improvements of 10 and 15 points on AIME24 and AMC23, respectively. These results highlight the superiority of dynamic, model-adaptive data selection over static, externally defined strategies in advancing reasoning.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
Friends-MMC: A Dataset for Multi-modal Multi-party Conversation Understanding
Dec 23, 2024Multi-modal multi-party conversation (MMC) is a less studied yet important topic of research due to that it well fits real-world scenarios and thus potentially has more widely-used applications. Compared with the traditional multi-modal conversations, MMC requires stronger character-centered understanding abilities as there are many interlocutors appearing in both the visual and textual context. To facilitate the study of this problem, we present Friends-MMC in this paper, an MMC dataset that contains 24,000+ unique utterances paired with video context. To explore the character-centered understanding of the dialogue, we also annotate the speaker of each utterance, the names and bounding bboxes of faces that appear in the video. Based on this Friends-MMC dataset, we further study two fundamental MMC tasks: conversation speaker identification and conversation response prediction, both of which have the multi-party nature with the video or image as visual context. For conversation speaker identification, we demonstrate the inefficiencies of existing methods such as pre-trained models, and propose a simple yet effective baseline method that leverages an optimization solver to utilize the context of two modalities to achieve better performance. For conversation response prediction, we fine-tune generative dialogue models on Friend-MMC, and analyze the benefits of speaker information. The code and dataset is publicly available at https://github.com/yellow-binary-tree/Friends-MMC and thus we call for more attention on modeling speaker information when understanding conversations.