 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMMI: A Comprehensive Multi-modal Interaction Benchmark in Streaming Video Contexts
Mar 29, 2025The rapid advancement of multi-modal language models (MLLMs) like GPT-4o has propelled the development of Omni language models, designed to process and proactively respond to continuous streams of multi-modal data. Despite their potential, evaluating their real-world interactive capabilities in streaming video contexts remains a formidable challenge. In this work, we introduce OmniMMI, a comprehensive multi-modal interaction benchmark tailored for OmniLLMs in streaming video contexts. OmniMMI encompasses over 1,121 videos and 2,290 questions, addressing two critical yet underexplored challenges in existing video benchmarks: streaming video understanding and proactive reasoning, across six distinct subtasks. Moreover, we propose a novel framework, Multi-modal Multiplexing Modeling (M4), designed to enable an inference-efficient streaming model that can see, listen while generating.
Friends-MMC: A Dataset for Multi-modal Multi-party Conversation Understanding
Dec 23, 2024Multi-modal multi-party conversation (MMC) is a less studied yet important topic of research due to that it well fits real-world scenarios and thus potentially has more widely-used applications. Compared with the traditional multi-modal conversations, MMC requires stronger character-centered understanding abilities as there are many interlocutors appearing in both the visual and textual context. To facilitate the study of this problem, we present Friends-MMC in this paper, an MMC dataset that contains 24,000+ unique utterances paired with video context. To explore the character-centered understanding of the dialogue, we also annotate the speaker of each utterance, the names and bounding bboxes of faces that appear in the video. Based on this Friends-MMC dataset, we further study two fundamental MMC tasks: conversation speaker identification and conversation response prediction, both of which have the multi-party nature with the video or image as visual context. For conversation speaker identification, we demonstrate the inefficiencies of existing methods such as pre-trained models, and propose a simple yet effective baseline method that leverages an optimization solver to utilize the context of two modalities to achieve better performance. For conversation response prediction, we fine-tune generative dialogue models on Friend-MMC, and analyze the benefits of speaker information. The code and dataset is publicly available at https://github.com/yellow-binary-tree/Friends-MMC and thus we call for more attention on modeling speaker information when understanding conversations.
VideoLLM Knows When to Speak: Enhancing Time-Sensitive Video Comprehension with Video-Text Duet Interaction Format
Nov 27, 2024



Recent researches on video large language models (VideoLLM) predominantly focus on model architectures and training datasets, leaving the interaction format between the user and the model under-explored. In existing works, users often interact with VideoLLMs by using the entire video and a query as input, after which the model generates a response. This interaction format constrains the application of VideoLLMs in scenarios such as live-streaming comprehension where videos do not end and responses are required in a real-time manner, and also results in unsatisfactory performance on time-sensitive tasks that requires localizing video segments. In this paper, we focus on a video-text duet interaction format. This interaction format is characterized by the continuous playback of the video, and both the user and the model can insert their text messages at any position during the video playback. When a text message ends, the video continues to play, akin to the alternative of two performers in a duet. We construct MMDuetIT, a video-text training dataset designed to adapt VideoLLMs to video-text duet interaction format. We also introduce the Multi-Answer Grounded Video Question Answering (MAGQA) task to benchmark the real-time response ability of VideoLLMs. Trained on MMDuetIT, MMDuet demonstrates that adopting the video-text duet interaction format enables the model to achieve significant improvements in various time-sensitive tasks (76% CIDEr on YouCook2 dense video captioning, 90\% mAP on QVHighlights highlight detection and 25% R@0.5 on Charades-STA temporal video grounding) with minimal training efforts, and also enable VideoLLMs to reply in a real-time manner as the video plays. Code, data and demo are available at: https://github.com/yellow-binary-tree/MMDuet.
Understanding Multimodal Hallucination with Parameter-Free Representation Alignment
Sep 02, 2024



Hallucination is a common issue in Multimodal Large Language Models (MLLMs), yet the underlying principles remain poorly understood. In this paper, we investigate which components of MLLMs contribute to object hallucinations. To analyze image representations while completely avoiding the influence of all other factors other than the image representation itself, we propose a parametric-free representation alignment metric (Pfram) that can measure the similarities between any two representation systems without requiring additional training parameters. Notably, Pfram can also assess the alignment of a neural representation system with the human representation system, represented by ground-truth annotations of images. By evaluating the alignment with object annotations, we demonstrate that this metric shows strong and consistent correlations with object hallucination across a wide range of state-of-the-art MLLMs, spanning various model architectures and sizes. Furthermore, using this metric, we explore other key issues related to image representations in MLLMs, such as the role of different modules, the impact of textual instructions, and potential improvements including the use of alternative visual encoders. Our code is available at: https://github.com/yellow-binary-tree/Pfram.
End-to-End Video Question Answering with Frame Scoring Mechanisms and Adaptive Sampling
Jul 23, 2024



Video Question Answering (VideoQA) has emerged as a challenging frontier in the field of multimedia processing, requiring intricate interactions between visual and textual modalities. Simply uniformly sampling frames or indiscriminately aggregating frame-level visual features often falls short in capturing the nuanced and relevant contexts of videos to well perform VideoQA. To mitigate these issues, we propose VidF4, a novel VideoQA framework equipped with tailored frame selection strategy for effective and efficient VideoQA. We propose three frame-scoring mechanisms that consider both question relevance and inter-frame similarity to evaluate the importance of each frame for a given question on the video. Furthermore, we design a differentiable adaptive frame sampling mechanism to facilitate end-to-end training for the frame selector and answer generator. The experimental results across three widely adopted benchmarks demonstrate that our model consistently outperforms existing VideoQA methods, establishing a new SOTA across NExT-QA (+0.3%), STAR (+0.9%), and TVQA (+1.0%). Furthermore, through both quantitative and qualitative analyses, we validate the effectiveness of each design choice.
VideoHallucer: Evaluating Intrinsic and Extrinsic Hallucinations in Large Video-Language Models
Jun 24, 2024



Recent advancements in Multimodal Large Language Models (MLLMs) have extended their capabilities to video understanding. Yet, these models are often plagued by "hallucinations", where irrelevant or nonsensical content is generated, deviating from the actual video context. This work introduces VideoHallucer, the first comprehensive benchmark for hallucination detection in large video-language models (LVLMs). VideoHallucer categorizes hallucinations into two main types: intrinsic and extrinsic, offering further subcategories for detailed analysis, including object-relation, temporal, semantic detail, extrinsic factual, and extrinsic non-factual hallucinations. We adopt an adversarial binary VideoQA method for comprehensive evaluation, where pairs of basic and hallucinated questions are crafted strategically. By evaluating eleven LVLMs on VideoHallucer, we reveal that i) the majority of current models exhibit significant issues with hallucinations; ii) while scaling datasets and parameters improves models' ability to detect basic visual cues and counterfactuals, it provides limited benefit for detecting extrinsic factual hallucinations; iii) existing models are more adept at detecting facts than identifying hallucinations. As a byproduct, these analyses further instruct the development of our self-PEP framework, achieving an average of 5.38% improvement in hallucination resistance across all model architectures.
HawkEye: Training Video-Text LLMs for Grounding Text in Videos
Mar 15, 2024



Video-text Large Language Models (video-text LLMs) have shown remarkable performance in answering questions and holding conversations on simple videos. However, they perform almost the same as random on grounding text queries in long and complicated videos, having little ability to understand and reason about temporal information, which is the most fundamental difference between videos and images. In this paper, we propose HawkEye, one of the first video-text LLMs that can perform temporal video grounding in a fully text-to-text manner. To collect training data that is applicable for temporal video grounding, we construct InternVid-G, a large-scale video-text corpus with segment-level captions and negative spans, with which we introduce two new time-aware training objectives to video-text LLMs. We also propose a coarse-grained method of representing segments in videos, which is more robust and easier for LLMs to learn and follow than other alternatives. Extensive experiments show that HawkEye is better at temporal video grounding and comparable on other video-text tasks with existing video-text LLMs, which verifies its superior video-text multi-modal understanding abilities.
LSTP: Language-guided Spatial-Temporal Prompt Learning for Long-form Video-Text Understanding
Feb 25, 2024



Despite progress in video-language modeling, the computational challenge of interpreting long-form videos in response to task-specific linguistic queries persists, largely due to the complexity of high-dimensional video data and the misalignment between language and visual cues over space and time. To tackle this issue, we introduce a novel approach called Language-guided Spatial-Temporal Prompt Learning (LSTP). This approach features two key components: a Temporal Prompt Sampler (TPS) with optical flow prior that leverages temporal information to efficiently extract relevant video content, and a Spatial Prompt Solver (SPS) that adeptly captures the intricate spatial relationships between visual and textual elements. By harmonizing TPS and SPS with a cohesive training strategy, our framework significantly enhances computational efficiency, temporal understanding, and spatial-temporal alignment. Empirical evaluations across two challenging tasks--video question answering and temporal question grounding in videos--using a variety of video-language pretrainings (VLPs) and large language models (LLMs) demonstrate the superior performance, speed, and versatility of our proposed LSTP paradigm.
STAIR: Spatial-Temporal Reasoning with Auditable Intermediate Results for Video Question Answering
Jan 08, 2024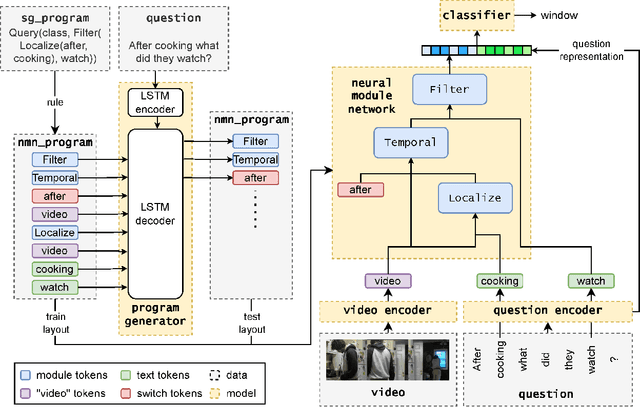



Recently we have witnessed the rapid development of video question answering models. However, most models can only handle simple videos in terms of temporal reasoning, and their performance tends to drop when answering temporal-reasoning questions on long and informative videos. To tackle this problem we propose STAIR, a Spatial-Temporal Reasoning model with Auditable Intermediate Results for video question answering. STAIR is a neural module network, which contains a program generator to decompose a given question into a hierarchical combination of several sub-tasks, and a set of lightweight neural modules to complete each of these sub-tasks. Though neural module networks are already widely studied on image-text tasks, applying them to videos is a non-trivial task, as reasoning on videos requires different abilities. In this paper, we define a set of basic video-text sub-tasks for video question answering and design a set of lightweight modules to complete them. Different from most prior works, modules of STAIR return intermediate outputs specific to their intentions instead of always returning attention maps, which makes it easier to interpret and collaborate with pre-trained models. We also introduce intermediate supervision to make these intermediate outputs more accurate. We conduct extensive experiments on several video question answering datasets under various settings to show STAIR's performance, explainability, compatibility with pre-trained models, and applicability when program annotations are not available. Code: https://github.com/yellow-binary-tree/STAIR
VSTAR: A Video-grounded Dialogue Dataset for Situated Semantic Understanding with Scene and Topic Transitions
May 30, 2023


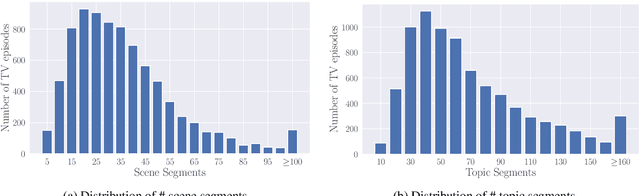
Video-grounded dialogue understanding is a challenging problem that requires machine to perceive, parse and reason over situated semantics extracted from weakly aligned video and dialogues. Most existing benchmarks treat both modalities the same as a frame-independent visual understanding task, while neglecting the intrinsic attributes in multimodal dialogues, such as scene and topic transitions. In this paper, we present Video-grounded Scene&Topic AwaRe dialogue (VSTAR) dataset, a large scale video-grounded dialogue understanding dataset based on 395 TV series. Based on VSTAR, we propose two benchmarks for video-grounded dialogue understanding: scene segmentation and topic segmentation, and one benchmark for video-grounded dialogue generation. Comprehensive experiments are performed on these benchmarks to demonstrate the importance of multimodal information and segments in video-grounded dialogue understanding and generation.