 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCA-HFP: Curvature-Aware Heterogeneous Federated Pruning with Model Reconstruction
Mar 13, 2026Federated learning on heterogeneous edge devices requires personalized compression while preserving aggregation compatibility and stable convergence. We present Curvature-Aware Heterogeneous Federated Pruning (CA-HFP), a practical framework that enables each client perform structured, device-specific pruning guided by a curvature-informed significance score, and subsequently maps its compact submodel back into a common global parameter space via a lightweight reconstruction. We derive a convergence bound for federated optimization with multiple local SGD steps that explicitly accounts for local computation, data heterogeneity, and pruning-induced perturbations; from which a principled loss-based pruning criterion is derived. Extensive experiments on FMNIST, CIFAR-10, and CIFAR-100 using VGG and ResNet architectures under varying degrees of data heterogeneity demonstrate that CA-HFP preserves model accuracy while significantly reducing per-client computation and communication costs, outperforming standard federated training and existing pruning-based baselines.
Detecting Deepfakes with Multivariate Soft Blending and CLIP-based Image-Text Alignment
Feb 14, 2026The proliferation of highly realistic facial forgeries necessitates robust detection methods. However, existing approaches often suffer from limited accuracy and poor generalization due to significant distribution shifts among samples generated by diverse forgery techniques. To address these challenges, we propose a novel Multivariate and Soft Blending Augmentation with CLIP-guided Forgery Intensity Estimation (MSBA-CLIP) framework. Our method leverages the multimodal alignment capabilities of CLIP to capture subtle forgery traces. We introduce a Multivariate and Soft Blending Augmentation (MSBA) strategy that synthesizes images by blending forgeries from multiple methods with random weights, forcing the model to learn generalizable patterns. Furthermore, a dedicated Multivariate Forgery Intensity Estimation (MFIE) module is designed to explicitly guide the model in learning features related to varied forgery modes and intensities. Extensive experiments demonstrate state-of-the-art performance. On in-domain tests, our method improves Accuracy and AUC by 3.32\% and 4.02\%, respectively, over the best baseline. In cross-domain evaluations across five datasets, it achieves an average AUC gain of 3.27\%. Ablation studies confirm the efficacy of both proposed components. While the reliance on a large vision-language model entails higher computational cost, our work presents a significant step towards more generalizable and robust deepfake detection.
A Specialized Large Language Model for Clinical Reasoning and Diagnosis in Rare Diseases
Nov 18, 2025Rare diseases affect hundreds of millions worldwide, yet diagnosis often spans years. Convectional pipelines decouple noisy evidence extraction from downstream inferential diagnosis, and general/medical large language models (LLMs) face scarce real world electronic health records (EHRs), stale domain knowledge, and hallucinations. We assemble a large, domain specialized clinical corpus and a clinician validated reasoning set, and develop RareSeek R1 via staged instruction tuning, chain of thought learning, and graph grounded retrieval. Across multicenter EHR narratives and public benchmarks, RareSeek R1 attains state of the art accuracy, robust generalization, and stability under noisy or overlapping phenotypes. Augmented retrieval yields the largest gains when narratives pair with prioritized variants by resolving ambiguity and aligning candidates to mechanisms. Human studies show performance on par with experienced physicians and consistent gains in assistive use. Notably, transparent reasoning highlights decisive non phenotypic evidence (median 23.1%, such as imaging, interventions, functional tests) underpinning many correct diagnoses. This work advances a narrative first, knowledge integrated reasoning paradigm that shortens the diagnostic odyssey and enables auditable, clinically translatable decision support.
FFT-MoE: Efficient Federated Fine-Tuning for Foundation Models via Large-scale Sparse MoE under Heterogeneous Edge
Aug 26, 2025As FMs drive progress toward Artificial General Intelligence (AGI), fine-tuning them under privacy and resource constraints has become increasingly critical particularly when highquality training data resides on distributed edge devices. Federated Learning (FL) offers a compelling solution through Federated Fine-Tuning (FFT), which enables collaborative model adaptation without sharing raw data. Recent approaches incorporate Parameter-Efficient Fine-Tuning (PEFT) techniques such as Low Rank Adaptation (LoRA) to reduce computational overhead. However, LoRA-based FFT faces two major limitations in heterogeneous FL environments: structural incompatibility across clients with varying LoRA configurations and limited adaptability to non-IID data distributions, which hinders convergence and generalization. To address these challenges, we propose FFT MoE, a novel FFT framework that replaces LoRA with sparse Mixture of Experts (MoE) adapters. Each client trains a lightweight gating network to selectively activate a personalized subset of experts, enabling fine-grained adaptation to local resource budgets while preserving aggregation compatibility. To further combat the expert load imbalance caused by device and data heterogeneity, we introduce a heterogeneity-aware auxiliary loss that dynamically regularizes the routing distribution to ensure expert diversity and balanced utilization. Extensive experiments spanning both IID and non-IID conditions demonstrate that FFT MoE consistently outperforms state of the art FFT baselines in generalization performance and training efficiency.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
An Attention-Assisted AI Model for Real-Time Underwater Sound Speed Estimation Leveraging Remote Sensing Sea Surface Temperature Data
Feb 19, 2025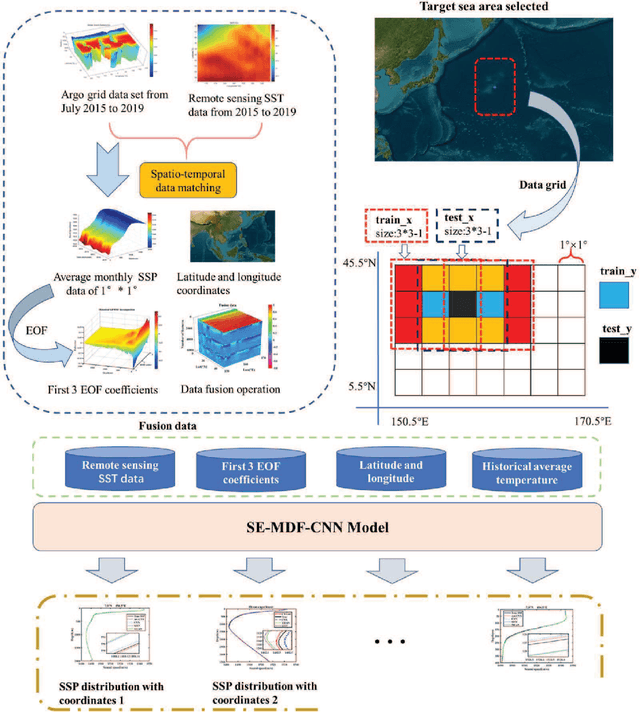
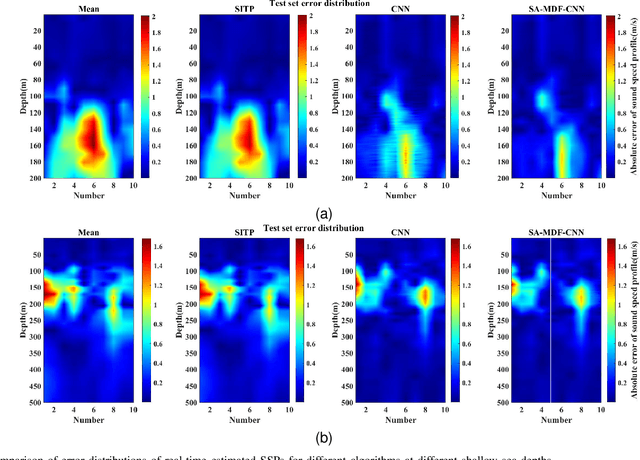
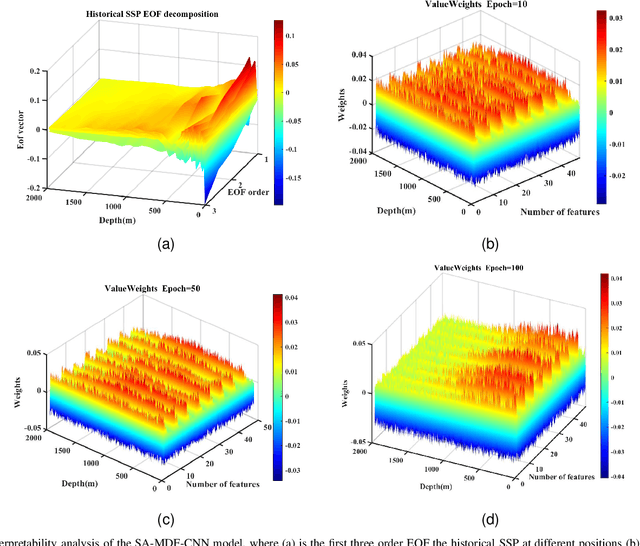
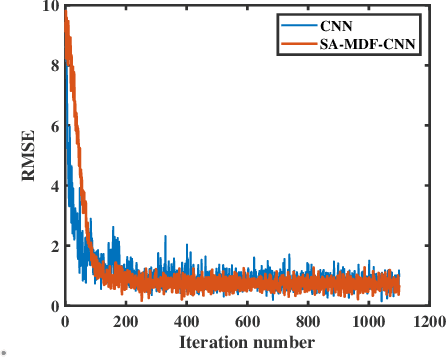
The estimation of underwater sound velocity distribution serves as a critical basis for facilitating effective underwater communication and precise positioning, given that variations in sound velocity influence the path of signal transmission. Conventional techniques for the direct measurement of sound velocity, as well as methods that involve the inversion of sound velocity utilizing acoustic field data, necessitate on--site data collection. This requirement not only places high demands on device deployment, but also presents challenges in achieving real-time estimation of sound velocity distribution. In order to construct a real-time sound velocity field and eliminate the need for underwater onsite data measurement operations, we propose a self-attention embedded multimodal data fusion convolutional neural network (SA-MDF-CNN) for real-time underwater sound speed profile (SSP) estimation. The proposed model seeks to elucidate the inherent relationship between remote sensing sea surface temperature (SST) data, the primary component characteristics of historical SSPs, and their spatial coordinates. This is achieved by employing CNNs and attention mechanisms to extract local and global correlations from the input data, respectively. The ultimate objective is to facilitate a rapid and precise estimation of sound velocity distribution within a specified task area. Experimental results show that the method proposed in this paper has lower root mean square error (RMSE) and stronger robustness than other state-of-the-art methods.
FIRP: Faster LLM inference via future intermediate representation prediction
Oct 27, 2024Recent advancements in Large Language Models (LLMs) have shown remarkable performance across a wide range of tasks. Despite this, the auto-regressive nature of LLM decoding, which generates only a single token per forward propagation, fails to fully exploit the parallel computational power of GPUs, leading to considerable latency. To address this, we introduce a novel speculative decoding method named FIRP which generates multiple tokens instead of one at each decoding step. We achieve this by predicting the intermediate hidden states of future tokens (tokens have not been decoded yet) and then using these pseudo hidden states to decode future tokens, specifically, these pseudo hidden states are predicted with simple linear transformation in intermediate layers of LLMs. Once predicted, they participate in the computation of all the following layers, thereby assimilating richer semantic information. As the layers go deeper, the semantic gap between pseudo and real hidden states is narrowed and it becomes feasible to decode future tokens with high accuracy. To validate the effectiveness of FIRP, we conduct extensive experiments, showing a speedup ratio of 1.9x-3x in several models and datasets, analytical experiments also prove our motivations.
Graph-Structured Speculative Decoding
Jul 23, 2024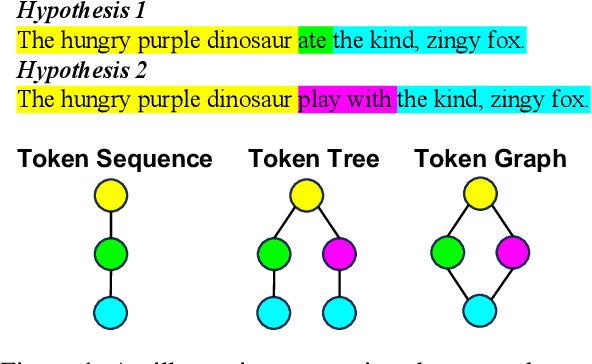
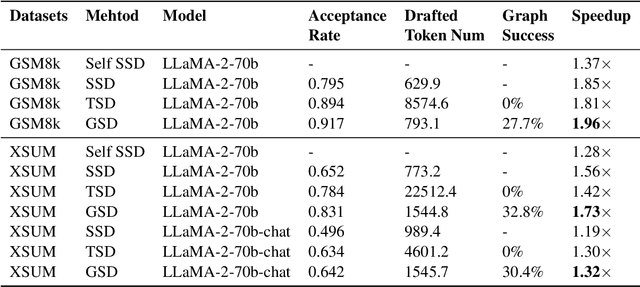
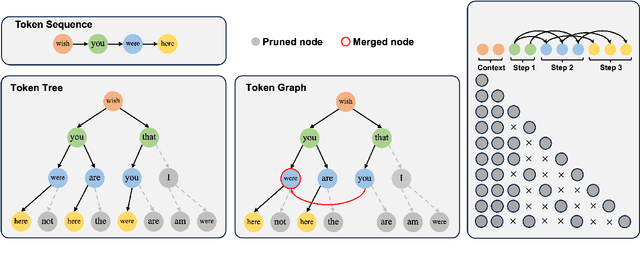
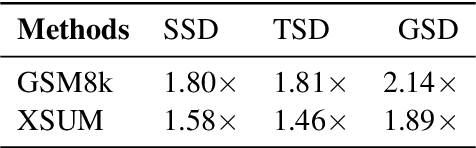
Speculative decoding has emerged as a promising technique to accelerate the inference of Large Language Models (LLMs) by employing a small language model to draft a hypothesis sequence, which is then validated by the LLM. The effectiveness of this approach heavily relies on the balance between performance and efficiency of the draft model. In our research, we focus on enhancing the proportion of draft tokens that are accepted to the final output by generating multiple hypotheses instead of just one. This allows the LLM more options to choose from and select the longest sequence that meets its standards. Our analysis reveals that hypotheses produced by the draft model share many common token sequences, suggesting a potential for optimizing computation. Leveraging this observation, we introduce an innovative approach utilizing a directed acyclic graph (DAG) to manage the drafted hypotheses. This structure enables us to efficiently predict and merge recurring token sequences, vastly reducing the computational demands of the draft model. We term this approach Graph-structured Speculative Decoding (GSD). We apply GSD across a range of LLMs, including a 70-billion parameter LLaMA-2 model, and observe a remarkable speedup of 1.73$\times$ to 1.96$\times$, significantly surpassing standard speculative decoding.
AnyTaskTune: Advanced Domain-Specific Solutions through Task-Fine-Tuning
Jul 09, 2024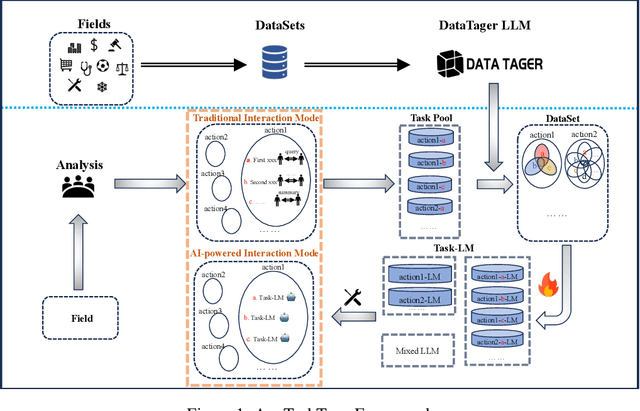
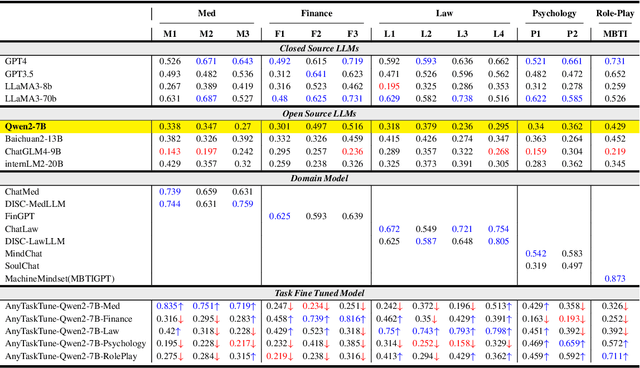


The pervasive deployment of Large Language Models-LLMs in various sectors often neglects the nuanced requirements of individuals and small organizations, who benefit more from models precisely tailored to their specific business contexts rather than those with broadly superior general capabilities. This work introduces \textbf{AnyTaskTune}, a novel fine-tuning methodology coined as \textbf{Task-Fine-Tune}, specifically developed to elevate model performance on a diverse array of domain-specific tasks. This method involves a meticulous process to identify and define targeted sub-tasks within a domain, followed by the creation of specialized enhancement datasets for fine-tuning, thereby optimizing task-specific model performance. We conducted comprehensive fine-tuning experiments not only in the legal domain for tasks such as keyword extraction and sentence prediction but across over twenty different sub-tasks derived from the domains of finance, healthcare, law, psychology, consumer services, and human resources. To substantiate our approach and facilitate community engagement, we will open-source these bilingual task datasets. Our findings demonstrate that models fine-tuned using the \textbf{Task-Fine-Tune} methodology not only achieve superior performance on these specific tasks but also significantly outperform models with higher general capabilities in their respective domains. Our work is publicly available at \url{https://github.com/PandaVT/DataTager}.
Optimal Reference Nodes Deployment for Positioning Seafloor Anchor Nodes
May 24, 2024



Seafloor anchor nodes, which form a geodetic network, are designed to provide surface and underwater users with positioning, navigation and timing (PNT) services. Due to the non-uniform distribution of underwater sound speed, accurate positioning of underwater anchor nodes is a challenge work. Traditional anchor node positioning typically uses cross or circular shapes, however, how to optimize the deployment of reference nodes for positioning underwater anchor nodes considering the variability of sound speed has not yet been studied. This paper focuses on the optimal reference nodes deployment strategies for time--of--arrival (TOA) localization in the three-dimensional (3D) underwater space. We adopt the criterion that minimizing the trace of the inverse Fisher information matrix (FIM) to determine optimal reference nodes deployment with Gaussian measurement noise, which is positive related to the signal propagation path. A comprehensive analysis of optimal reference-target geometries is provided in the general circumstance with no restriction on the number of reference nodes, elevation angle and reference-target range. A new semi-closed form solution is found to detemine the optimal geometries. To demonstrate the findings in this paper, we conducted both simulations and sea trials on underwater anchor node positioning. Both the simulation and experiment results are consistent with theoretical analysis.