 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTNet: Prediction of Underwater Sound Speed Profiles with An Advanced Semi-Transformer Neural Network
Apr 24, 2025



Real time acquisition of accurate underwater sound velocity profile (SSP) is crucial for tracking the propagation trajectory of underwater acoustic signals, making it play a key role in ocean communication positioning. SSPs can be directly measured by instruments or inverted leveraging sound field data. Although measurement techniques provide a good accuracy, they are constrained by limited spatial coverage and require substantial time investment. The inversion method based on real-time measurement of acoustic field data improves operational efficiency, but loses the accuracy of SSP estimation and suffers from limited spatial applicability due to its stringent requirements for ocean observation infrastructure. To achieve accurate long-term ocean SSP estimation independent of real-time underwater data measurements, we propose a Semi-Transformer neural network (STNet) specifically designed for simulating sound velocity distribution patterns from the perspective of time series prediction. The proposed network architecture incorporates an optimized self-attention mechanism to effectively capture long-range temporal dependencies within historical sound velocity time-series data, facilitating accurate estimation of current SSPs or prediction of future SSPs. Through architectural optimization of the Transformer framework and integration of a time encoding mechanism, STNet could effectively improve computational efficiency. Comparative experimental results reveal that STNet outperforms state-of-the-art models in predictive accuracy and maintain good computational efficiency, demonstrating its potential for enabling accurate long-term full-depth ocean SSP forecasting.
Future Full-Ocean Deep SSPs Prediction based on Hierarchical Long Short-Term Memory Neural Networks
Nov 16, 2023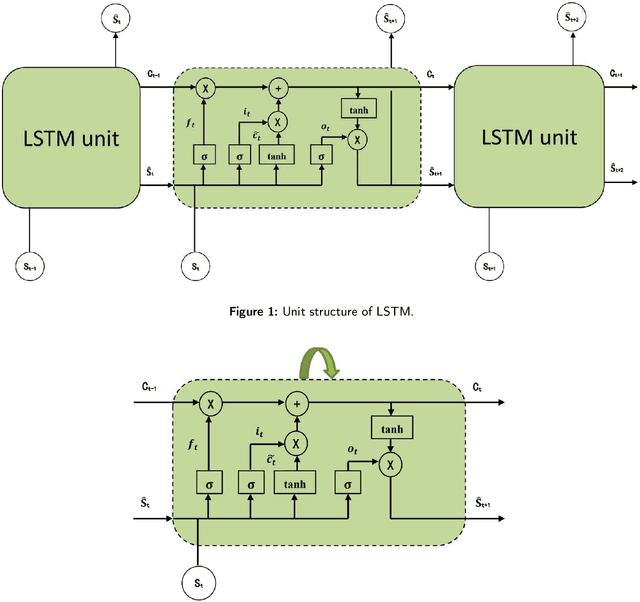


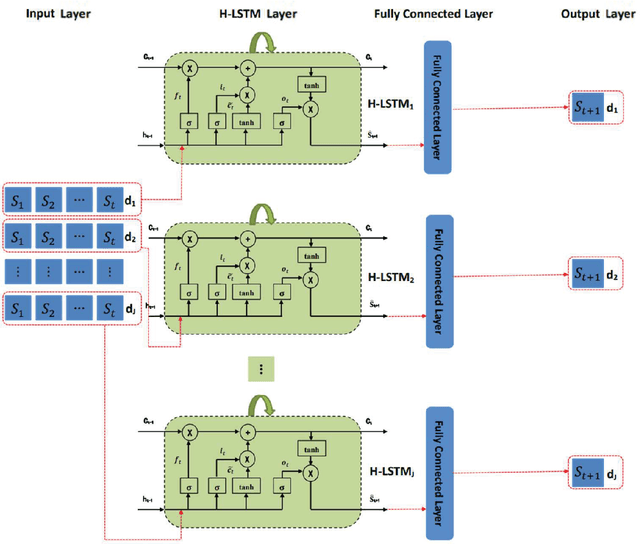
The spatial-temporal distribution of underwater sound velocity affects the propagation mode of underwater acoustic signals. Therefore, rapid estimation and prediction of underwater sound velocity distribution is crucial for providing underwater positioning, navigation and timing (PNT) services. Currently, sound speed profile (SSP) inversion methods have a faster time response rate compared to direct measurement methods, however, most SSP inversion methods focus on constructing spatial dimensional sound velocity fields and are highly dependent on sonar observation data, thus high requirements have been placed on observation data sources. To explore the distribution pattern of sound velocity in the time dimension and achieve future SSP prediction without sonar observation data, we propose a hierarchical long short-term memory (H-LSTM) neural network for SSP prediction. By our SSP prediction method, the sound speed distribution could be estimated without any on-site data measurement process, so that the time efficiency could be greatly improved. Through comparing with other state-of-the-art methods, H-LSTM has better accuracy performance on prediction of monthly average sound velocity distribution, which is less than 1 m/s in different depth layers.
Dynamic Prediction of Full-Ocean Depth SSP by Hierarchical LSTM: An Experimental Result
Oct 14, 2023SSP distribution is an important parameter for underwater positioning, navigation and timing (PNT) because it affects the propagation mode of underwater acoustic signals. To accurate predict future sound speed distribution, we propose a hierarchical long short--term memory (H--LSTM) neural network for future sound speed prediction, which explore the distribution pattern of sound velocity in the time dimension. To verify the feasibility and effectiveness, we conducted both simulations and real experiments. The ocean experiment was held in the South China Sea in April, 2023. Results show that the accuracy of the proposed method outperforms the state--of--the--art methods.
Underwater Sound Speed Profile Construction: A Review
Oct 12, 2023



Real--time and accurate construction of regional sound speed profiles (SSP) is important for building underwater positioning, navigation, and timing (PNT) systems as it greatly affect the signal propagation modes such as trajectory. In this paper, we summarizes and analyzes the current research status in the field of underwater SSP construction, and the mainstream methods include direct SSP measurement and SSP inversion. In the direct measurement method, we compare the performance of popular international commercial temperature, conductivity, and depth profilers (CTD). While for the inversion methods, the framework and basic principles of matched field processing (MFP), compressive sensing (CS), and deep learning (DL) for constructing SSP are introduced, and their advantages and disadvantages are compared. The traditional direct measurement method has good accuracy performance, but it usually takes a long time. The proposal of SSP inversion method greatly improves the convenience and real--time performance, but the accuracy is not as good as the direct measurement method. Currently, the SSP inversion relies on sonar observation data, making it difficult to apply to areas that couldn't be covered by underwater observation systems, and these methods are unable to predict the distribution of sound velocity at future times. How to comprehensively utilize multi-source data and provide elastic sound velocity distribution estimation services with different accuracy and real-time requirements for underwater users without sonar observation data is the mainstream trend in future research on SSP construction.
Adversarial Examples that Fool Detectors
Dec 07, 2017



An adversarial example is an example that has been adjusted to produce a wrong label when presented to a system at test time. To date, adversarial example constructions have been demonstrated for classifiers, but not for detectors. If adversarial examples that could fool a detector exist, they could be used to (for example) maliciously create security hazards on roads populated with smart vehicles. In this paper, we demonstrate a construction that successfully fools two standard detectors, Faster RCNN and YOLO. The existence of such examples is surprising, as attacking a classifier is very different from attacking a detector, and that the structure of detectors - which must search for their own bounding box, and which cannot estimate that box very accurately - makes it quite likely that adversarial patterns are strongly disrupted. We show that our construction produces adversarial examples that generalize well across sequences digitally, even though large perturbations are needed. We also show that our construction yields physical objects that are adversarial.
Standard detectors aren't fooled by physical adversarial stop signs
Oct 26, 2017



An adversarial example is an example that has been adjusted to produce the wrong label when presented to a system at test time. If adversarial examples existed that could fool a detector, they could be used to (for example) wreak havoc on roads populated with smart vehicles. Recently, we described our difficulties creating physical adversarial stop signs that fool a detector. More recently, Evtimov et al. produced a physical adversarial stop sign that fools a proxy model of a detector. In this paper, we show that these physical adversarial stop signs do not fool two standard detectors (YOLO and Faster RCNN) in standard configuration. Evtimov et al.'s construction relies on a crop of the image to the stop sign; this crop is then resized and presented to a classifier. We argue that the cropping and resizing procedure largely eliminates the effects of rescaling and of view angle. Whether an adversarial attack is robust under rescaling and change of view direction remains moot. We argue that attacking a classifier is very different from attacking a detector, and that the structure of detectors - which must search for their own bounding box, and which cannot estimate that box very accurately - likely makes it difficult to make adversarial patterns. Finally, an adversarial pattern on a physical object that could fool a detector would have to be adversarial in the face of a wide family of parametric distortions (scale; view angle; box shift inside the detector; illumination; and so on). Such a pattern would be of great theoretical and practical interest. There is currently no evidence that such patterns exist.
SafetyNet: Detecting and Rejecting Adversarial Examples Robustly
Aug 15, 2017

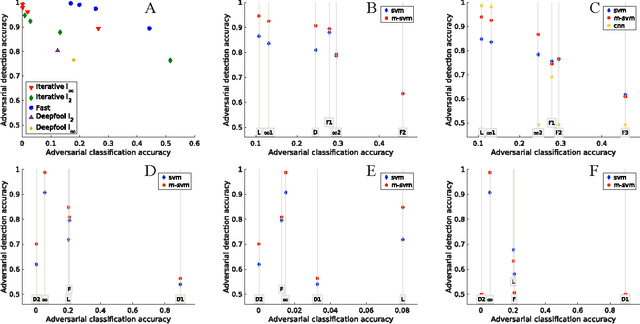
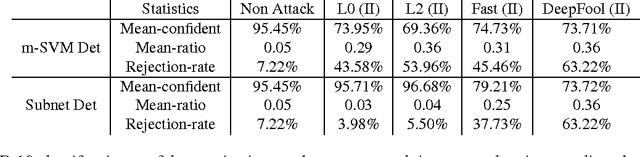
We describe a method to produce a network where current methods such as DeepFool have great difficulty producing adversarial samples. Our construction suggests some insights into how deep networks work. We provide a reasonable analyses that our construction is difficult to defeat, and show experimentally that our method is hard to defeat with both Type I and Type II attacks using several standard networks and datasets. This SafetyNet architecture is used to an important and novel application SceneProof, which can reliably detect whether an image is a picture of a real scene or not. SceneProof applies to images captured with depth maps (RGBD images) and checks if a pair of image and depth map is consistent. It relies on the relative difficulty of producing naturalistic depth maps for images in post processing. We demonstrate that our SafetyNet is robust to adversarial examples built from currently known attacking approaches.
NO Need to Worry about Adversarial Examples in Object Detection in Autonomous Vehicles
Jul 12, 2017



It has been shown that most machine learning algorithms are susceptible to adversarial perturbations. Slightly perturbing an image in a carefully chosen direction in the image space may cause a trained neural network model to misclassify it. Recently, it was shown that physical adversarial examples exist: printing perturbed images then taking pictures of them would still result in misclassification. This raises security and safety concerns. However, these experiments ignore a crucial property of physical objects: the camera can view objects from different distances and at different angles. In this paper, we show experiments that suggest that current constructions of physical adversarial examples do not disrupt object detection from a moving platform. Instead, a trained neural network classifies most of the pictures taken from different distances and angles of a perturbed image correctly. We believe this is because the adversarial property of the perturbation is sensitive to the scale at which the perturbed picture is viewed, so (for example) an autonomous car will misclassify a stop sign only from a small range of distances. Our work raises an important question: can one construct examples that are adversarial for many or most viewing conditions? If so, the construction should offer very significant insights into the internal representation of patterns by deep networks. If not, there is a good prospect that adversarial examples can be reduced to a curiosity with little practical impact.
Learning Diverse Image Colorization
Apr 27, 2017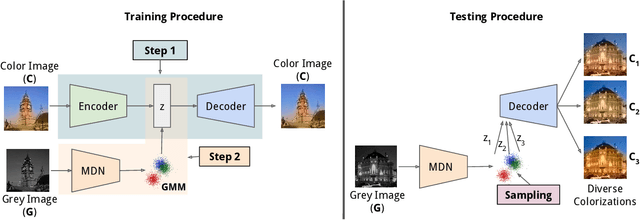

Colorization is an ambiguous problem, with multiple viable colorizations for a single grey-level image. However, previous methods only produce the single most probable colorization. Our goal is to model the diversity intrinsic to the problem of colorization and produce multiple colorizations that display long-scale spatial co-ordination. We learn a low dimensional embedding of color fields using a variational autoencoder (VAE). We construct loss terms for the VAE decoder that avoid blurry outputs and take into account the uneven distribution of pixel colors. Finally, we build a conditional model for the multi-modal distribution between grey-level image and the color field embeddings. Samples from this conditional model result in diverse colorization. We demonstrate that our method obtains better diverse colorizations than a standard conditional variational autoencoder (CVAE) model, as well as a recently proposed conditional generative adversarial network (cGAN).
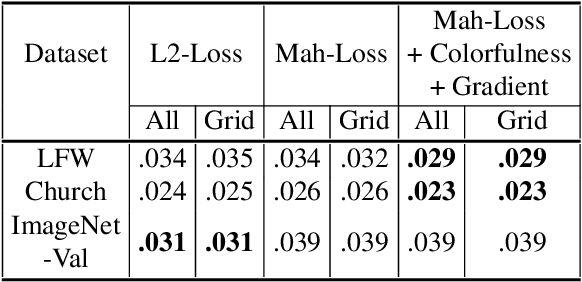
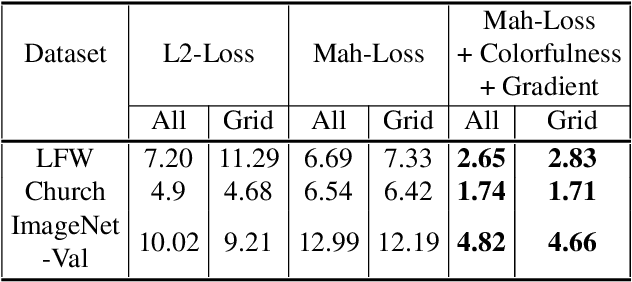
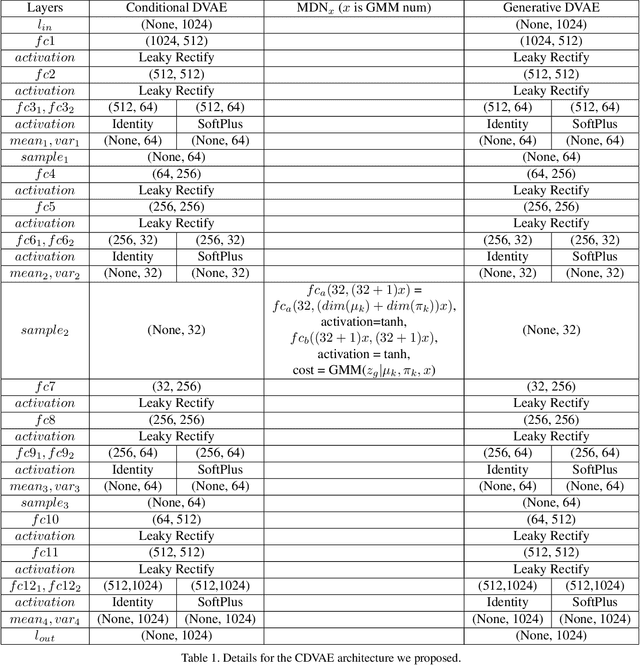
CDVAE: Co-embedding Deep Variational Auto Encoder for Conditional Variational Generation
Mar 28, 2017
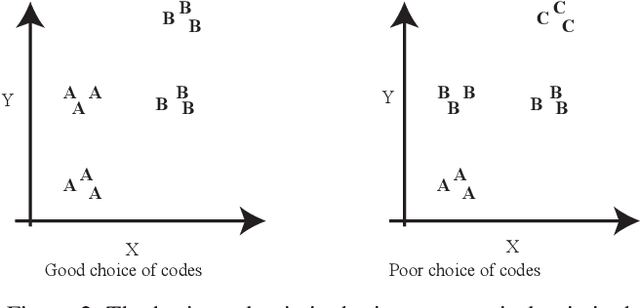
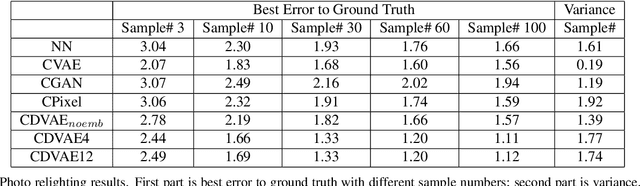
Problems such as predicting a new shading field (Y) for an image (X) are ambiguous: many very distinct solutions are good. Representing this ambiguity requires building a conditional model P(Y|X) of the prediction, conditioned on the image. Such a model is difficult to train, because we do not usually have training data containing many different shadings for the same image. As a result, we need different training examples to share data to produce good models. This presents a danger we call "code space collapse" - the training procedure produces a model that has a very good loss score, but which represents the conditional distribution poorly. We demonstrate an improved method for building conditional models by exploiting a metric constraint on training data that prevents code space collapse. We demonstrate our model on two example tasks using real data: image saturation adjustment, image relighting. We describe quantitative metrics to evaluate ambiguous generation results. Our results quantitatively and qualitatively outperform different strong baselines.