 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlux Already Knows - Activating Subject-Driven Image Generation without Training
Apr 12, 2025We propose a simple yet effective zero-shot framework for subject-driven image generation using a vanilla Flux model. By framing the task as grid-based image completion and simply replicating the subject image(s) in a mosaic layout, we activate strong identity-preserving capabilities without any additional data, training, or inference-time fine-tuning. This "free lunch" approach is further strengthened by a novel cascade attention design and meta prompting technique, boosting fidelity and versatility. Experimental results show that our method outperforms baselines across multiple key metrics in benchmarks and human preference studies, with trade-offs in certain aspects. Additionally, it supports diverse edits, including logo insertion, virtual try-on, and subject replacement or insertion. These results demonstrate that a pre-trained foundational text-to-image model can enable high-quality, resource-efficient subject-driven generation, opening new possibilities for lightweight customization in downstream applications.
JoJoGAN: One Shot Face Stylization
Dec 22, 2021



While there have been recent advances in few-shot image stylization, these methods fail to capture stylistic details that are obvious to humans. Details such as the shape of the eyes, the boldness of the lines, are especially difficult for a model to learn, especially so under a limited data setting. In this work, we aim to perform one-shot image stylization that gets the details right. Given a reference style image, we approximate paired real data using GAN inversion and finetune a pretrained StyleGAN using that approximate paired data. We then encourage the StyleGAN to generalize so that the learned style can be applied to all other images.
StyleGAN of All Trades: Image Manipulation with Only Pretrained StyleGAN
Nov 02, 2021
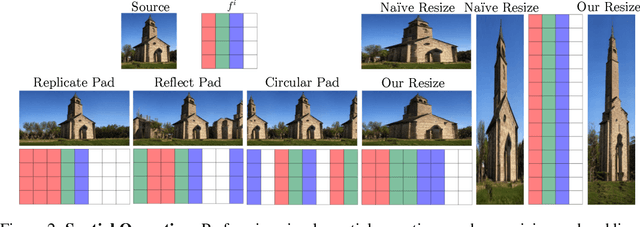


Recently, StyleGAN has enabled various image manipulation and editing tasks thanks to the high-quality generation and the disentangled latent space. However, additional architectures or task-specific training paradigms are usually required for different tasks. In this work, we take a deeper look at the spatial properties of StyleGAN. We show that with a pretrained StyleGAN along with some operations, without any additional architecture, we can perform comparably to the state-of-the-art methods on various tasks, including image blending, panorama generation, generation from a single image, controllable and local multimodal image to image translation, and attributes transfer. The proposed method is simple, effective, efficient, and applicable to any existing pretrained StyleGAN model.
Retrieve in Style: Unsupervised Facial Feature Transfer and Retrieval
Jul 17, 2021



We present Retrieve in Style (RIS), an unsupervised framework for fine-grained facial feature transfer and retrieval on real images. Recent work shows that it is possible to learn a catalog that allows local semantic transfers of facial features on generated images by capitalizing on the disentanglement property of the StyleGAN latent space. RIS improves existing art on: 1) feature disentanglement and allows for challenging transfers (i.e., hair and pose) that were not shown possible in SoTA methods. 2) eliminating the need for per-image hyperparameter tuning, and for computing a catalog over a large batch of images. 3) enabling face retrieval using the proposed facial features (e.g., eyes), and to our best knowledge, is the first work to retrieve face images at the fine-grained level. 4) robustness and natural application to real images. Our qualitative and quantitative analyses show RIS achieves both high-fidelity feature transfers and accurate fine-grained retrievals on real images. We discuss the responsible application of RIS.
GANs N' Roses: Stable, Controllable, Diverse Image to Image Translation (works for videos too!)
Jun 11, 2021
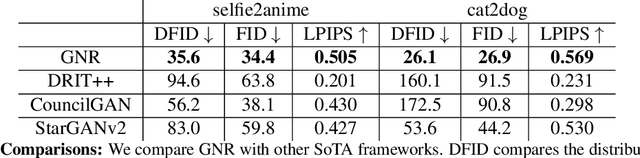
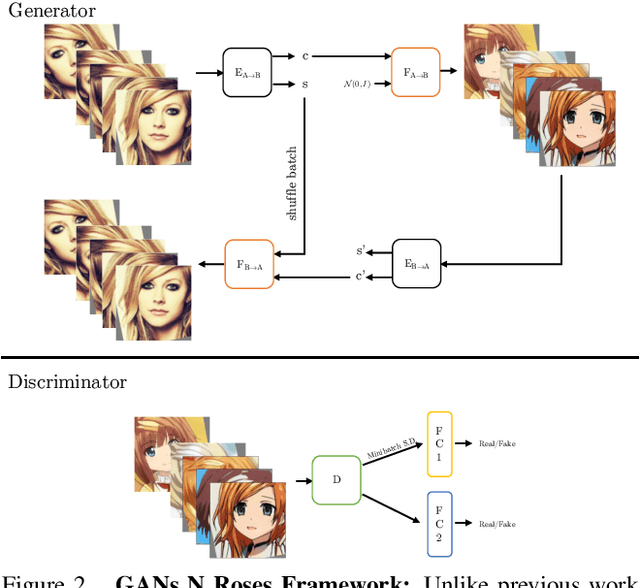

We show how to learn a map that takes a content code, derived from a face image, and a randomly chosen style code to an anime image. We derive an adversarial loss from our simple and effective definitions of style and content. This adversarial loss guarantees the map is diverse -- a very wide range of anime can be produced from a single content code. Under plausible assumptions, the map is not just diverse, but also correctly represents the probability of an anime, conditioned on an input face. In contrast, current multimodal generation procedures cannot capture the complex styles that appear in anime. Extensive quantitative experiments support the idea the map is correct. Extensive qualitative results show that the method can generate a much more diverse range of styles than SOTA comparisons. Finally, we show that our formalization of content and style allows us to perform video to video translation without ever training on videos.
Toward Accurate and Realistic Virtual Try-on Through Shape Matching and Multiple Warps
Mar 27, 2020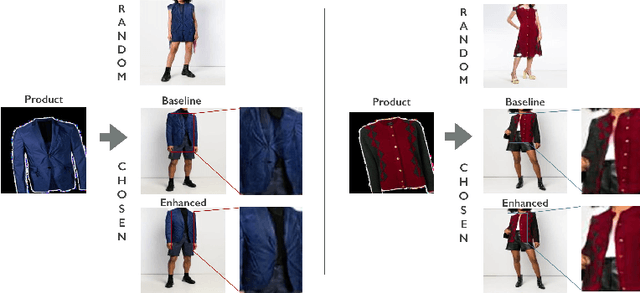
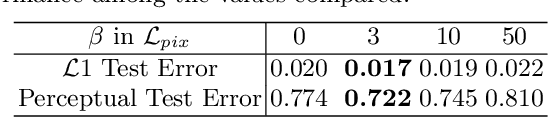
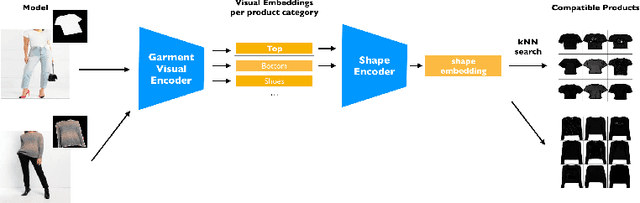
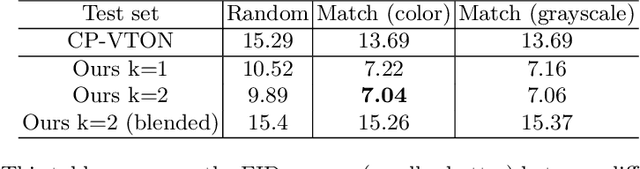
A virtual try-on method takes a product image and an image of a model and produces an image of the model wearing the product. Most methods essentially compute warps from the product image to the model image and combine using image generation methods. However, obtaining a realistic image is challenging because the kinematics of garments is complex and because outline, texture, and shading cues in the image reveal errors to human viewers. The garment must have appropriate drapes; texture must be warped to be consistent with the shape of a draped garment; small details (buttons, collars, lapels, pockets, etc.) must be placed appropriately on the garment, and so on. Evaluation is particularly difficult and is usually qualitative. This paper uses quantitative evaluation on a challenging, novel dataset to demonstrate that (a) for any warping method, one can choose target models automatically to improve results, and (b) learning multiple coordinated specialized warpers offers further improvements on results. Target models are chosen by a learned embedding procedure that predicts a representation of the products the model is wearing. This prediction is used to match products to models. Specialized warpers are trained by a method that encourages a second warper to perform well in locations where the first works poorly. The warps are then combined using a U-Net. Qualitative evaluation confirms that these improvements are wholesale over outline, texture shading, and garment details.
Effectively Unbiased FID and Inception Score and where to find them
Nov 16, 2019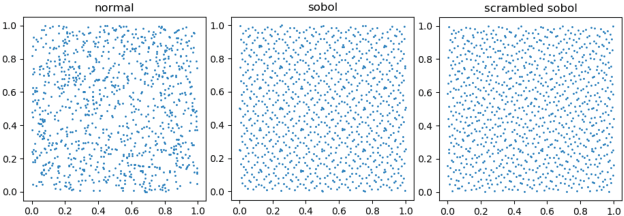

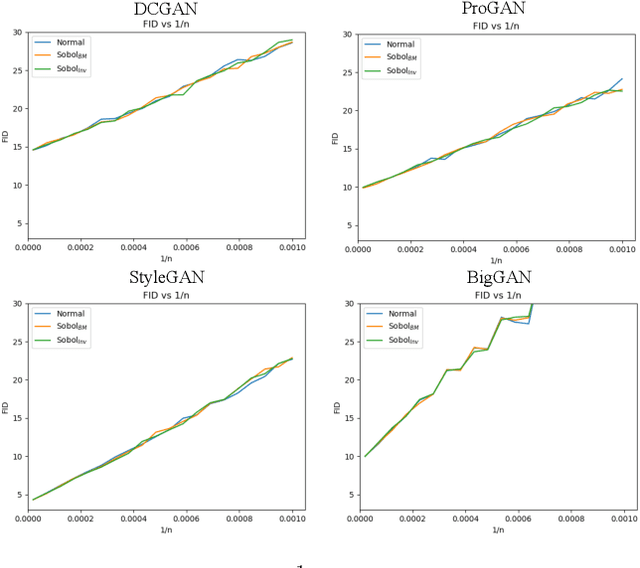
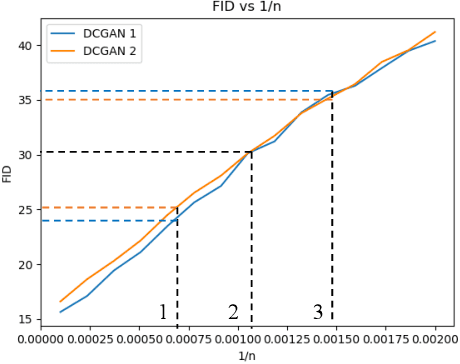
This paper shows that two commonly used evaluation metrics for generative models, the Fr\'echet Inception Distance (FID) and the Inception Score (IS), are biased -- the expected value of the score computed for a finite sample set is not the true value of the score. Worse, the paper shows that the bias term depends on the particular model being evaluated, so model A may get a better score than model B simply because model A's bias term is smaller. This effect cannot be fixed by evaluating at a fixed number of samples. This means all comparisons using FID or IS as currently computed are unreliable. We then show how to extrapolate the score to obtain an effectively bias-free estimate of scores computed with an infinite number of samples, which we term $\overline{\textrm{FID}}_\infty$ and $\overline{\textrm{IS}}_\infty$. In turn, this effectively bias-free estimate requires good estimates of scores with a finite number of samples. We show that using Quasi-Monte Carlo integration notably improves estimates of FID and IS for finite sample sets. Our extrapolated scores are simple, drop-in replacements for the finite sample scores. Additionally, we show that using low discrepancy sequence in GAN training offers small improvements in the resulting generator.
Big but Imperceptible Adversarial Perturbations via Semantic Manipulation
Apr 12, 2019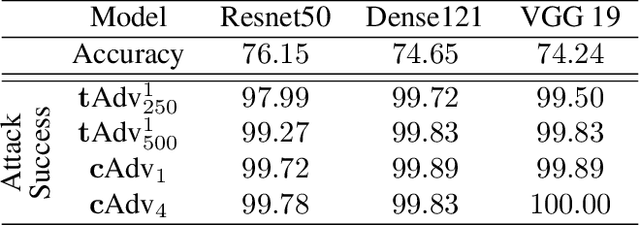

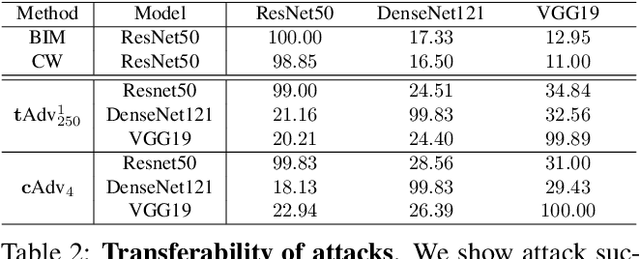

Machine learning, especially deep learning, is widely applied to a range of applications including computer vision, robotics and natural language processing. However, it has been shown that machine learning models are vulnerable to adversarial examples, carefully crafted samples that deceive learning models. In-depth studies on adversarial examples can help better understand potential vulnerabilities and therefore improve model robustness. Recent works have introduced various methods which generate adversarial examples. However, all require the perturbation to be of small magnitude ($\mathcal{L}_p$ norm) for them to be imperceptible to humans, which is hard to deploy in practice. In this paper we propose two novel methods, tAdv and cAdv, which leverage texture transfer and colorization to generate natural perturbation with a large $\mathcal{L}_p$ norm. We conduct extensive experiments to show that the proposed methods are general enough to attack both image classification and image captioning tasks on ImageNet and MSCOCO dataset. In addition, we conduct comprehensive user studies under various conditions to show that our generated adversarial examples are imperceptible to humans even when the perturbations are large. We also evaluate the transferability and robustness of the proposed attacks against several state-of-the-art defenses.
Learning Diverse Image Colorization
Apr 27, 2017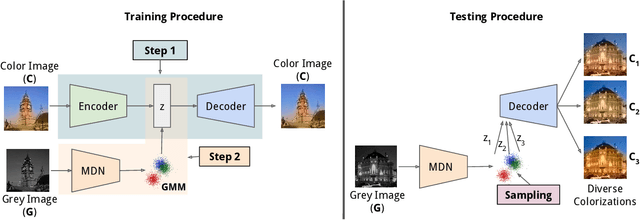
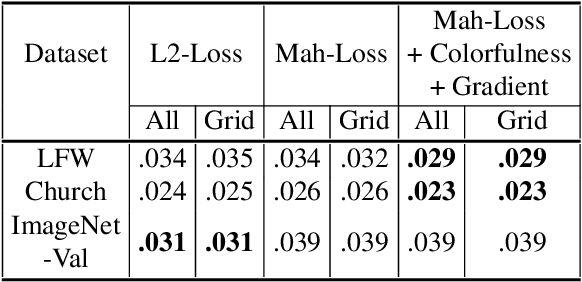

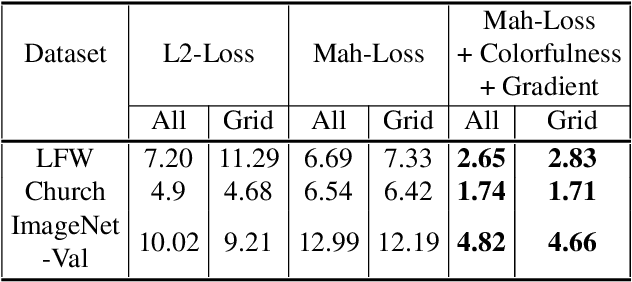
Colorization is an ambiguous problem, with multiple viable colorizations for a single grey-level image. However, previous methods only produce the single most probable colorization. Our goal is to model the diversity intrinsic to the problem of colorization and produce multiple colorizations that display long-scale spatial co-ordination. We learn a low dimensional embedding of color fields using a variational autoencoder (VAE). We construct loss terms for the VAE decoder that avoid blurry outputs and take into account the uneven distribution of pixel colors. Finally, we build a conditional model for the multi-modal distribution between grey-level image and the color field embeddings. Samples from this conditional model result in diverse colorization. We demonstrate that our method obtains better diverse colorizations than a standard conditional variational autoencoder (CVAE) model, as well as a recently proposed conditional generative adversarial network (cGAN).