 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperating RPN's Improve Few-Shot Object Detection
Nov 19, 2020
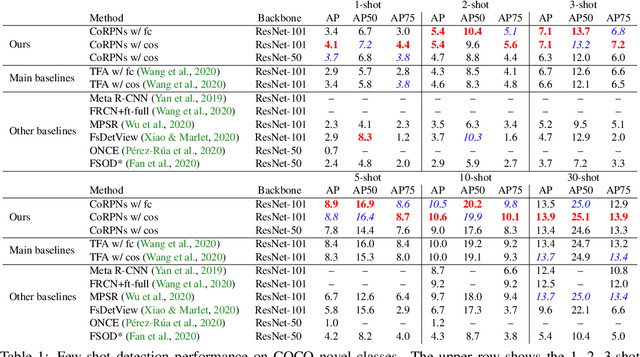

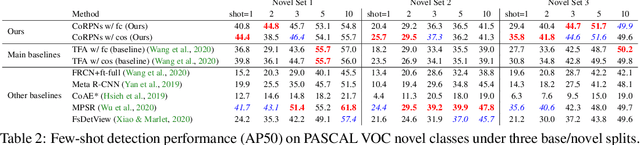
Learning to detect an object in an image from very few training examples - few-shot object detection - is challenging, because the classifier that sees proposal boxes has very little training data. A particularly challenging training regime occurs when there are one or two training examples. In this case, if the region proposal network (RPN) misses even one high intersection-over-union (IOU) training box, the classifier's model of how object appearance varies can be severely impacted. We use multiple distinct yet cooperating RPN's. Our RPN's are trained to be different, but not too different; doing so yields significant performance improvements over state of the art for COCO and PASCAL VOC in the very few-shot setting. This effect appears to be independent of the choice of classifier or dataset.
Cut-and-Paste Neural Rendering
Oct 12, 2020



Cut-and-paste methods take an object from one image and insert it into another. Doing so often results in unrealistic looking images because the inserted object's shading is inconsistent with the target scene's shading. Existing reshading methods require a geometric and physical model of the inserted object, which is then rendered using environment parameters. Accurately constructing such a model only from a single image is beyond the current understanding of computer vision. We describe an alternative procedure -- cut-and-paste neural rendering, to render the inserted fragment's shading field consistent with the target scene. We use a Deep Image Prior (DIP) as a neural renderer trained to render an image with consistent image decomposition inferences. The resulting rendering from DIP should have an albedo consistent with composite albedo; it should have a shading field that, outside the inserted fragment, is the same as the target scene's shading field; and composite surface normals are consistent with the final rendering's shading field. The result is a simple procedure that produces convincing and realistic shading. Moreover, our procedure does not require rendered images or image-decomposition from real images in the training or labeled annotations. In fact, our only use of simulated ground truth is our use of a pre-trained normal estimator. Qualitative results are strong, supported by a user study comparing against the state-of-the-art image harmonization baseline.
Big but Imperceptible Adversarial Perturbations via Semantic Manipulation
Apr 12, 2019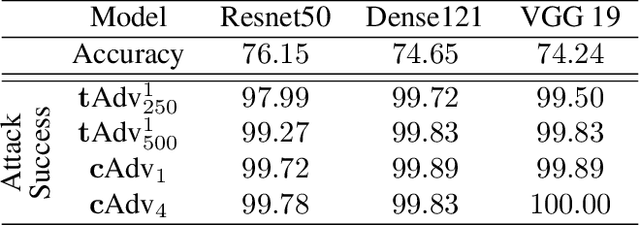

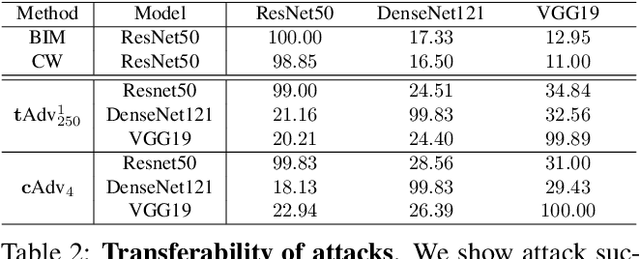

Machine learning, especially deep learning, is widely applied to a range of applications including computer vision, robotics and natural language processing. However, it has been shown that machine learning models are vulnerable to adversarial examples, carefully crafted samples that deceive learning models. In-depth studies on adversarial examples can help better understand potential vulnerabilities and therefore improve model robustness. Recent works have introduced various methods which generate adversarial examples. However, all require the perturbation to be of small magnitude ($\mathcal{L}_p$ norm) for them to be imperceptible to humans, which is hard to deploy in practice. In this paper we propose two novel methods, tAdv and cAdv, which leverage texture transfer and colorization to generate natural perturbation with a large $\mathcal{L}_p$ norm. We conduct extensive experiments to show that the proposed methods are general enough to attack both image classification and image captioning tasks on ImageNet and MSCOCO dataset. In addition, we conduct comprehensive user studies under various conditions to show that our generated adversarial examples are imperceptible to humans even when the perturbations are large. We also evaluate the transferability and robustness of the proposed attacks against several state-of-the-art defenses.