 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig but Imperceptible Adversarial Perturbations via Semantic Manipulation
Paper and Code
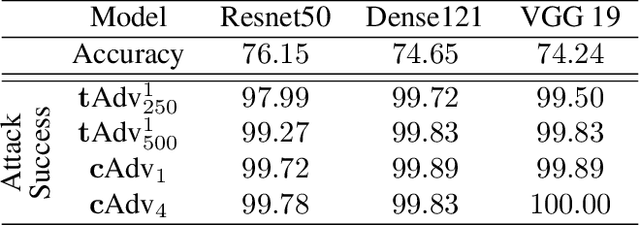

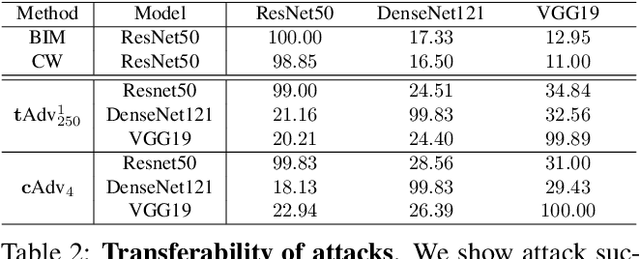

Machine learning, especially deep learning, is widely applied to a range of applications including computer vision, robotics and natural language processing. However, it has been shown that machine learning models are vulnerable to adversarial examples, carefully crafted samples that deceive learning models. In-depth studies on adversarial examples can help better understand potential vulnerabilities and therefore improve model robustness. Recent works have introduced various methods which generate adversarial examples. However, all require the perturbation to be of small magnitude ($\mathcal{L}_p$ norm) for them to be imperceptible to humans, which is hard to deploy in practice. In this paper we propose two novel methods, tAdv and cAdv, which leverage texture transfer and colorization to generate natural perturbation with a large $\mathcal{L}_p$ norm. We conduct extensive experiments to show that the proposed methods are general enough to attack both image classification and image captioning tasks on ImageNet and MSCOCO dataset. In addition, we conduct comprehensive user studies under various conditions to show that our generated adversarial examples are imperceptible to humans even when the perturbations are large. We also evaluate the transferability and robustness of the proposed attacks against several state-of-the-art defenses.