 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
AdaTT: Adaptive Task-to-Task Fusion Network for Multitask Learning in Recommendations
Apr 11, 2023



Multi-task learning (MTL) aims at enhancing the performance and efficiency of machine learning models by training them on multiple tasks simultaneously. However, MTL research faces two challenges: 1) modeling the relationships between tasks to effectively share knowledge between them, and 2) jointly learning task-specific and shared knowledge. In this paper, we present a novel model Adaptive Task-to-Task Fusion Network (AdaTT) to address both challenges. AdaTT is a deep fusion network built with task specific and optional shared fusion units at multiple levels. By leveraging a residual mechanism and gating mechanism for task-to-task fusion, these units adaptively learn shared knowledge and task specific knowledge. To evaluate the performance of AdaTT, we conduct experiments on a public benchmark and an industrial recommendation dataset using various task groups. Results demonstrate AdaTT can significantly outperform existing state-of-the-art baselines.
MolMiner: You only look once for chemical structure recognition
May 23, 2022
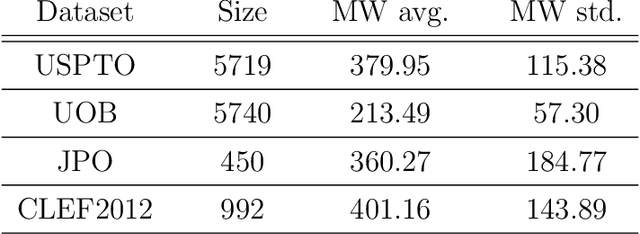
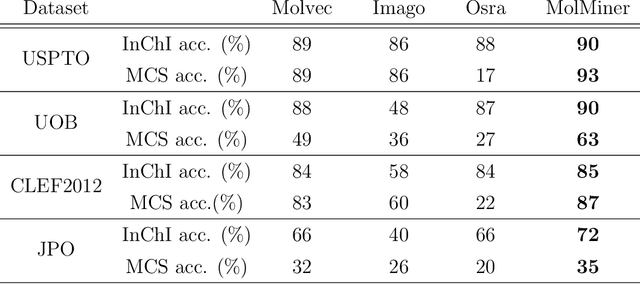
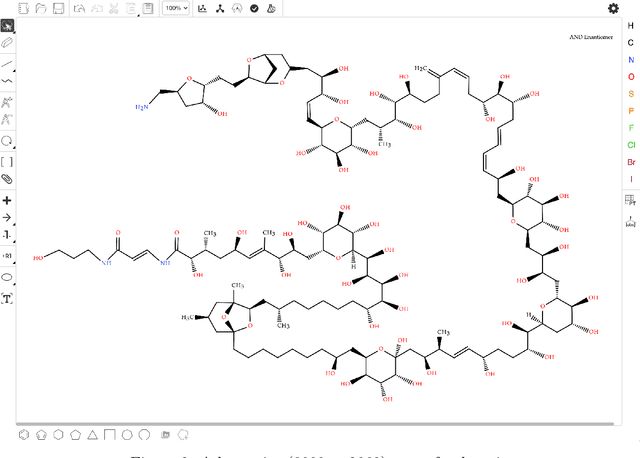
Molecular structures are always depicted as 2D printed form in scientific documents like journal papers and patents. However, these 2D depictions are not machine-readable. Due to a backlog of decades and an increasing amount of these printed literature, there is a high demand for the translation of printed depictions into machine-readable formats, which is known as Optical Chemical Structure Recognition (OCSR). Most OCSR systems developed over the last three decades follow a rule-based approach where the key step of vectorization of the depiction is based on the interpretation of vectors and nodes as bonds and atoms. Here, we present a practical software MolMiner, which is primarily built up using deep neural networks originally developed for semantic segmentation and object detection to recognize atom and bond elements from documents. These recognized elements can be easily connected as a molecular graph with distance-based construction algorithm. We carefully evaluate our software on four benchmark datasets with the state-of-the-art performance. Various real application scenarios are also tested, yielding satisfactory outcomes. The free download links of Mac and Windows versions are available: Mac: https://molminer-cdn.iipharma.cn/pharma-mind/artifact/latest/mac/PharmaMind-mac-latest-setup.dmg and Windows: https://molminer-cdn.iipharma.cn/pharma-mind/artifact/latest/win/PharmaMind-win-latest-setup.exe
DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction
Mar 11, 2022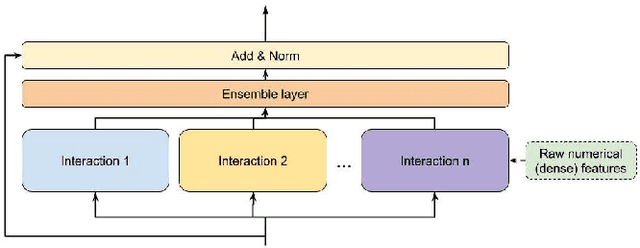
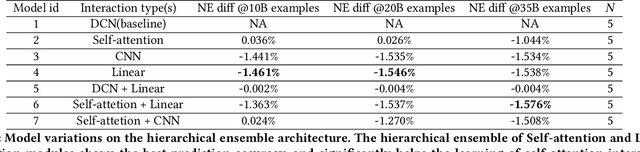
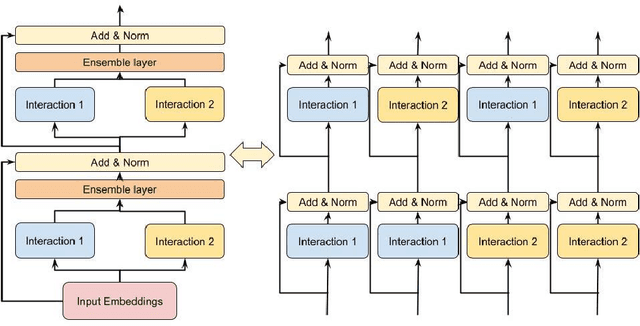

Learning feature interactions is important to the model performance of online advertising services. As a result, extensive efforts have been devoted to designing effective architectures to learn feature interactions. However, we observe that the practical performance of those designs can vary from dataset to dataset, even when the order of interactions claimed to be captured is the same. That indicates different designs may have different advantages and the interactions captured by them have non-overlapping information. Motivated by this observation, we propose DHEN - a deep and hierarchical ensemble architecture that can leverage strengths of heterogeneous interaction modules and learn a hierarchy of the interactions under different orders. To overcome the challenge brought by DHEN's deeper and multi-layer structure in training, we propose a novel co-designed training system that can further improve the training efficiency of DHEN. Experiments of DHEN on large-scale dataset from CTR prediction tasks attained 0.27\% improvement on the Normalized Entropy (NE) of prediction and 1.2x better training throughput than state-of-the-art baseline, demonstrating their effectiveness in practice.
Hallucination Improves Few-Shot Object Detection
May 04, 2021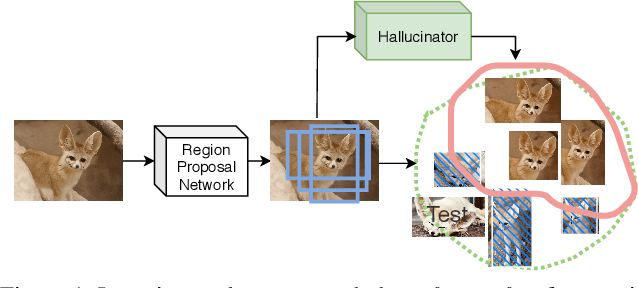



Learning to detect novel objects from few annotated examples is of great practical importance. A particularly challenging yet common regime occurs when there are extremely limited examples (less than three). One critical factor in improving few-shot detection is to address the lack of variation in training data. We propose to build a better model of variation for novel classes by transferring the shared within-class variation from base classes. To this end, we introduce a hallucinator network that learns to generate additional, useful training examples in the region of interest (RoI) feature space, and incorporate it into a modern object detection model. Our approach yields significant performance improvements on two state-of-the-art few-shot detectors with different proposal generation procedures. In particular, we achieve new state of the art in the extremely-few-shot regime on the challenging COCO benchmark.
Cooperating RPN's Improve Few-Shot Object Detection
Nov 19, 2020
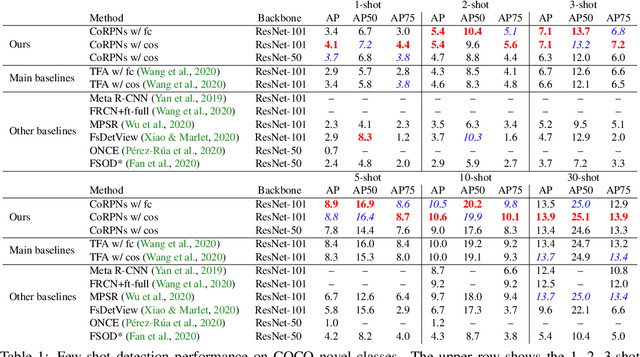

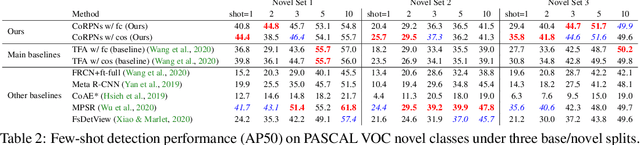
Learning to detect an object in an image from very few training examples - few-shot object detection - is challenging, because the classifier that sees proposal boxes has very little training data. A particularly challenging training regime occurs when there are one or two training examples. In this case, if the region proposal network (RPN) misses even one high intersection-over-union (IOU) training box, the classifier's model of how object appearance varies can be severely impacted. We use multiple distinct yet cooperating RPN's. Our RPN's are trained to be different, but not too different; doing so yields significant performance improvements over state of the art for COCO and PASCAL VOC in the very few-shot setting. This effect appears to be independent of the choice of classifier or dataset.
The Effect of Explicit Structure Encoding of Deep Neural Networks for Symbolic Music Generation
Nov 20, 2018
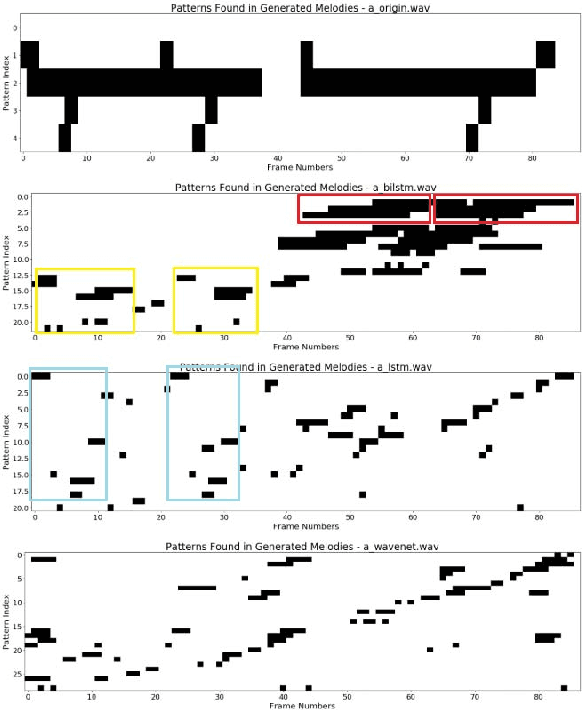
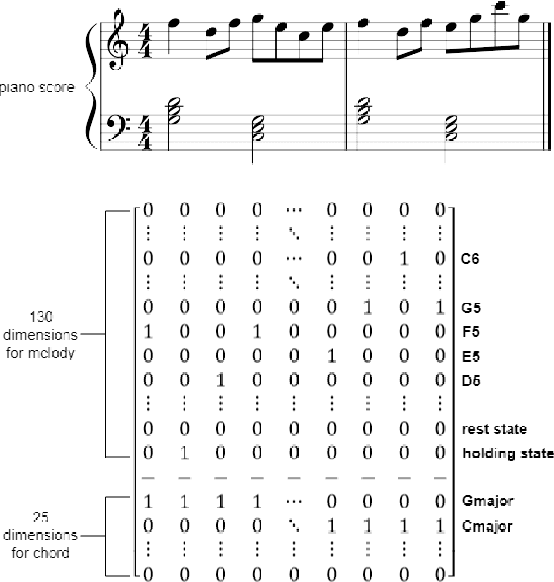
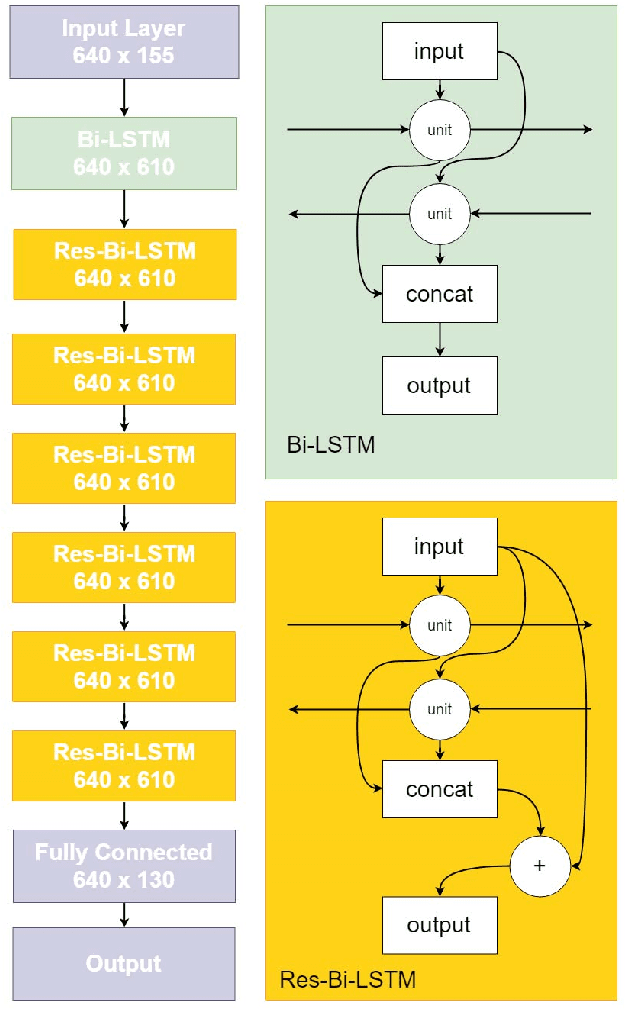
With recent breakthroughs in artificial neural networks, deep generative models have become one of the leading techniques for computational creativity. Despite very promising progress on image and short sequence generation, symbolic music generation remains a challenging problem since the structure of compositions are usually complicated. In this study, we attempt to solve the melody generation problem constrained by the given chord progression. This music meta-creation problem can also be incorporated into a plan recognition system with user inputs and predictive structural outputs. In particular, we explore the effect of explicit architectural encoding of musical structure via comparing two sequential generative models: LSTM (a type of RNN) and WaveNet (dilated temporal-CNN). As far as we know, this is the first study of applying WaveNet to symbolic music generation, as well as the first systematic comparison between temporal-CNN and RNN for music generation. We conduct a survey for evaluation in our generations and implemented Variable Markov Oracle in music pattern discovery. Experimental results show that to encode structure more explicitly using a stack of dilated convolution layers improved the performance significantly, and a global encoding of underlying chord progression into the generation procedure gains even more.