 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Emotion Understanding of Synthesized Speech
Mar 17, 2026Emotion is a core paralinguistic feature in voice interaction. It is widely believed that emotion understanding models learn fundamental representations that transfer to synthesized speech, making emotion understanding results a plausible reward or evaluation metric for assessing emotional expressiveness in speech synthesis. In this work, we critically examine this assumption by systematically evaluating Speech Emotion Recognition (SER) on synthesized speech across datasets, discriminative and generative SER models, and diverse synthesis models. We find that current SER models can not generalize to synthesized speech, largely because speech token prediction during synthesis induces a representation mismatch between synthesized and human speech. Moreover, generative Speech Language Models (SLMs) tend to infer emotion from textual semantics while ignoring paralinguistic cues. Overall, our findings suggest that existing SER models often exploit non-robust shortcuts rather than capturing fundamental features, and paralinguistic understanding in SLMs remains challenging.
MolMiner: You only look once for chemical structure recognition
May 23, 2022
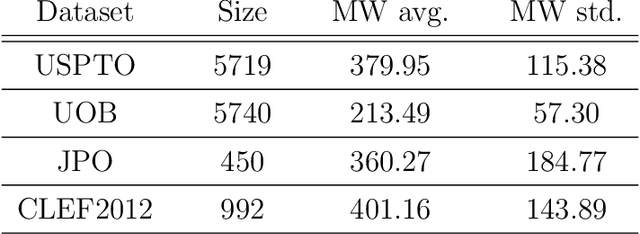
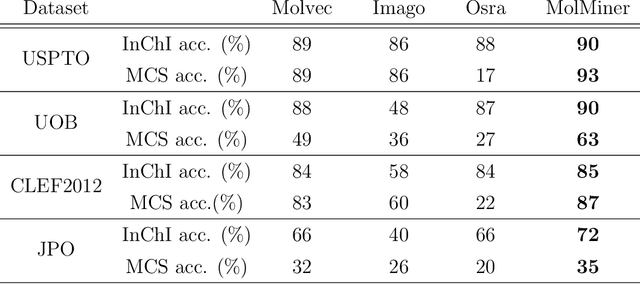
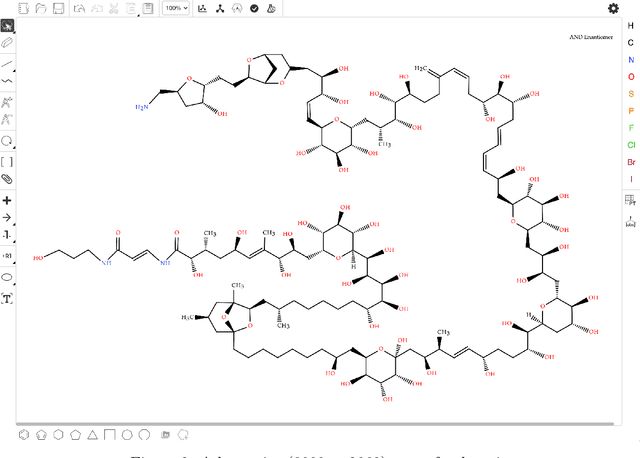
Molecular structures are always depicted as 2D printed form in scientific documents like journal papers and patents. However, these 2D depictions are not machine-readable. Due to a backlog of decades and an increasing amount of these printed literature, there is a high demand for the translation of printed depictions into machine-readable formats, which is known as Optical Chemical Structure Recognition (OCSR). Most OCSR systems developed over the last three decades follow a rule-based approach where the key step of vectorization of the depiction is based on the interpretation of vectors and nodes as bonds and atoms. Here, we present a practical software MolMiner, which is primarily built up using deep neural networks originally developed for semantic segmentation and object detection to recognize atom and bond elements from documents. These recognized elements can be easily connected as a molecular graph with distance-based construction algorithm. We carefully evaluate our software on four benchmark datasets with the state-of-the-art performance. Various real application scenarios are also tested, yielding satisfactory outcomes. The free download links of Mac and Windows versions are available: Mac: https://molminer-cdn.iipharma.cn/pharma-mind/artifact/latest/mac/PharmaMind-mac-latest-setup.dmg and Windows: https://molminer-cdn.iipharma.cn/pharma-mind/artifact/latest/win/PharmaMind-win-latest-setup.exe
A New Weakly Supervised Learning Approach for Real-time Iron Ore Feed Load Estimation
Oct 06, 2021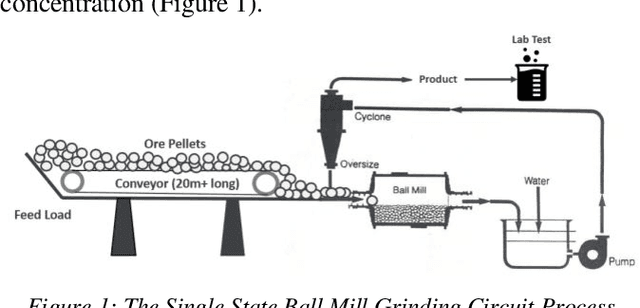

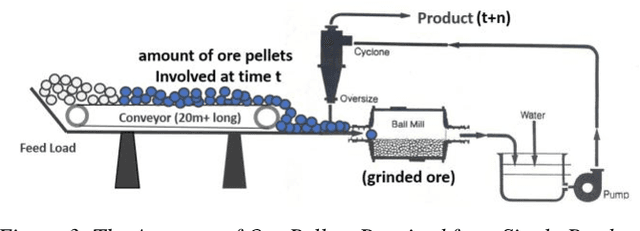
Iron ore feed load control is one of the most critical settings in a mineral grinding process, directly impacting the quality of final products. The setting of the feed load is mainly determined by the characteristics of the ore pellets. However, the characterisation of ore is challenging to acquire in many production environments, leading to poor feed load settings and inefficient production processes. This paper presents our work using deep learning models for direct ore feed load estimation from ore pellet images. To address the challenges caused by the large size of a full ore pellets image and the shortage of accurately annotated data, we treat the whole modelling process as a weakly supervised learning problem. A two-stage model training algorithm and two neural network architectures are proposed. The experiment results show competitive model performance, and the trained models can be used for real-time feed load estimation for grind process optimisation.
Selective Pseudo-Labeling with Reinforcement Learning for Semi-Supervised Domain Adaptation
Dec 07, 2020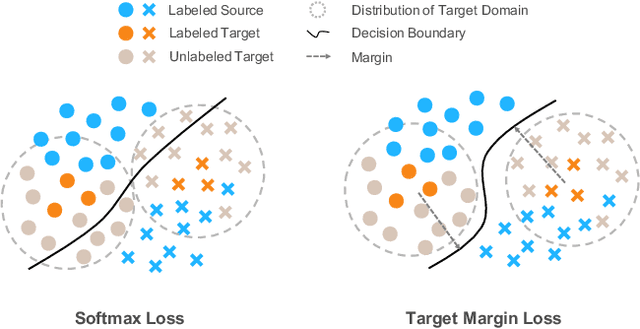
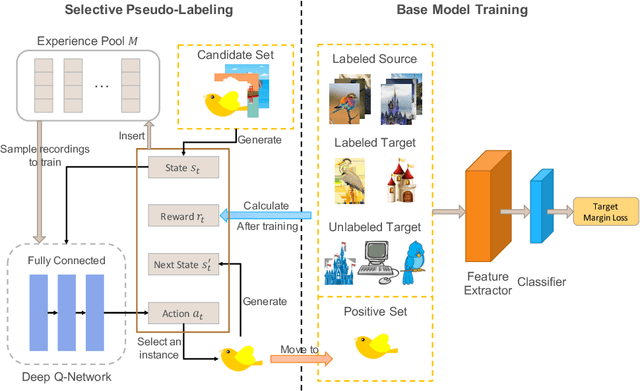
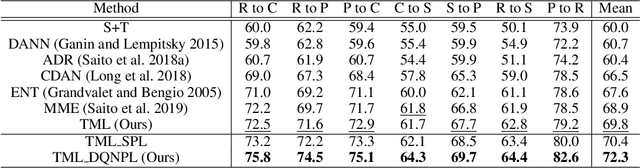
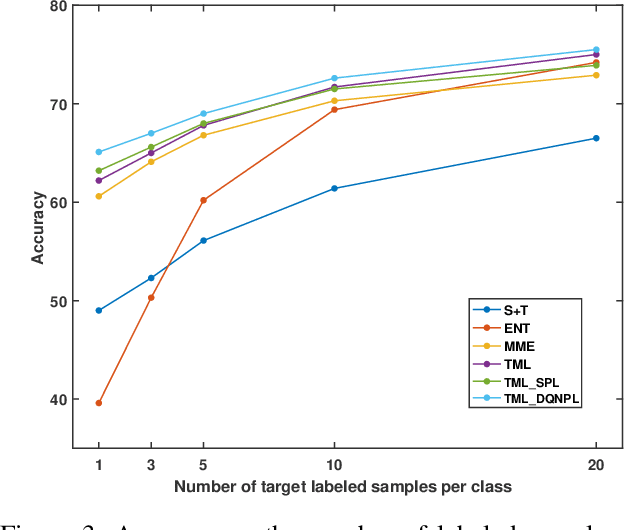
Recent domain adaptation methods have demonstrated impressive improvement on unsupervised domain adaptation problems. However, in the semi-supervised domain adaptation (SSDA) setting where the target domain has a few labeled instances available, these methods can fail to improve performance. Inspired by the effectiveness of pseudo-labels in domain adaptation, we propose a reinforcement learning based selective pseudo-labeling method for semi-supervised domain adaptation. It is difficult for conventional pseudo-labeling methods to balance the correctness and representativeness of pseudo-labeled data. To address this limitation, we develop a deep Q-learning model to select both accurate and representative pseudo-labeled instances. Moreover, motivated by large margin loss's capacity on learning discriminative features with little data, we further propose a novel target margin loss for our base model training to improve its discriminability. Our proposed method is evaluated on several benchmark datasets for SSDA, and demonstrates superior performance to all the comparison methods.
Ensemble Model with Batch Spectral Regularization and Data Blending for Cross-Domain Few-Shot Learning with Unlabeled Data
Jun 09, 2020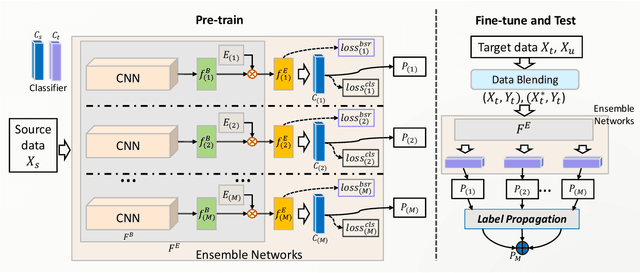
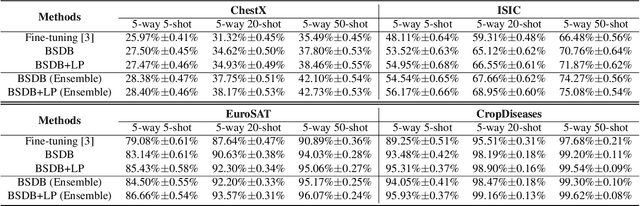
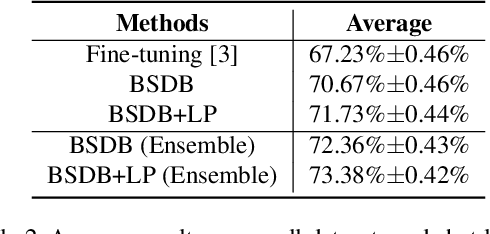
In this paper, we present our proposed ensemble model with batch spectral regularization and data blending mechanisms for the Track 2 problem of the cross-domain few-shot learning (CD-FSL) challenge. We build a multi-branch ensemble framework by using diverse feature transformation matrices, while deploying batch spectral feature regularization on each branch to improve the model's transferability. Moreover, we propose a data blending method to exploit the unlabeled data and augment the sparse support set in the target domain. Our proposed model demonstrates effective performance on the CD-FSL benchmark tasks.
Feature Transformation Ensemble Model with Batch Spectral Regularization for Cross-Domain Few-Shot Classification
May 21, 2020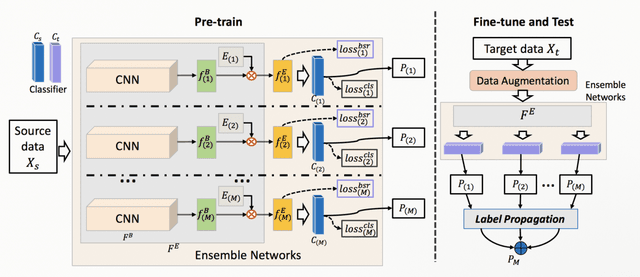
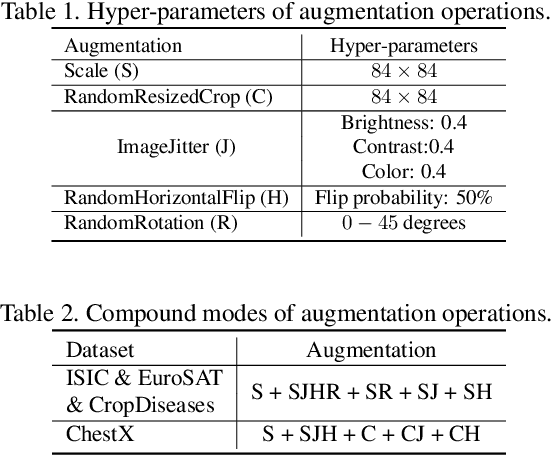
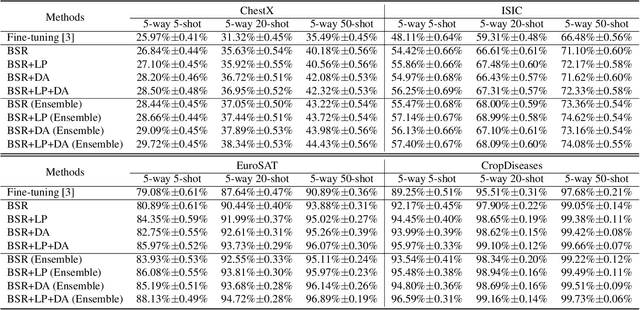
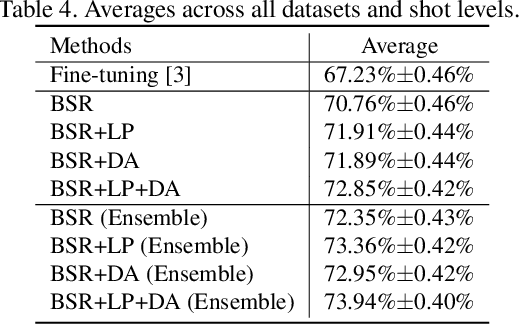
In this paper, we propose a feature transformation ensemble model with batch spectral regularization for the Cross-domain few-shot learning (CD-FSL) challenge. Specifically, we proposes to construct an ensemble prediction model by performing diverse feature transformations after a feature extraction network. On each branch prediction network of the model we use a batch spectral regularization term to suppress the singular values of the feature matrix during pre-training to improve the generalization ability of the model. The proposed model can then be fine tuned in the target domain to address few-shot classification. We also further apply label propagation, entropy minimization and data augmentation to mitigate the shortage of labeled data in target domains. Experiments are conducted on a number of CD-FSL benchmark tasks with four target domains and the results demonstrate the superiority of our proposed model.