 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseX: AI Defeats Physics Approaches on Protein-Ligand Cross Docking
May 03, 2025Recently, significant progress has been made in protein-ligand docking, especially in modern deep learning methods, and some benchmarks were proposed, e.g., PoseBench, Plinder. However, these benchmarks suffer from less practical evaluation setups (e.g., blind docking, self docking), or heavy framework that involves training, raising challenges to assess docking methods efficiently. To fill this gap, we proposed PoseX, an open-source benchmark focusing on self-docking and cross-docking, to evaluate the algorithmic advances practically and comprehensively. Specifically, first, we curate a new evaluation dataset with 718 entries for self docking and 1,312 for cross docking; second, we incorporate 22 docking methods across three methodological categories, including (1) traditional physics-based methods (e.g., Schr\"odinger Glide), (2) AI docking methods (e.g., DiffDock), (3) AI co-folding methods (e.g., AlphaFold3); third, we design a relaxation method as post-processing to minimize conformation energy and refine binding pose; fourth, we released a leaderboard to rank submitted models in real time. We draw some key insights via extensive experiments: (1) AI-based approaches have already surpassed traditional physics-based approaches in overall docking accuracy (RMSD). The longstanding generalization issues that have plagued AI molecular docking have been significantly alleviated in the latest models. (2) The stereochemical deficiencies of AI-based approaches can be greatly alleviated with post-processing relaxation. Combining AI docking methods with the enhanced relaxation method achieves the best performance to date. (3) AI co-folding methods commonly face ligand chirality issues, which cannot be resolved by relaxation. The code, curated dataset and leaderboard are released at https://github.com/CataAI/PoseX.
MolMiner: You only look once for chemical structure recognition
May 23, 2022
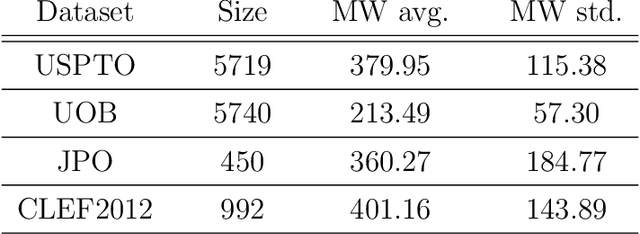
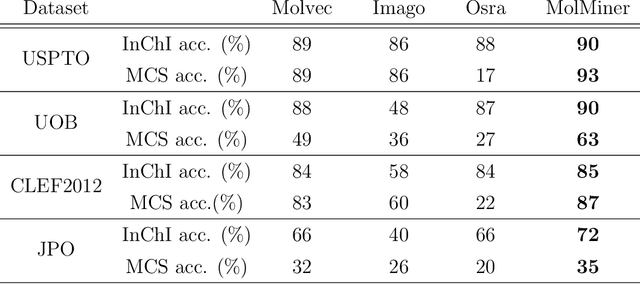
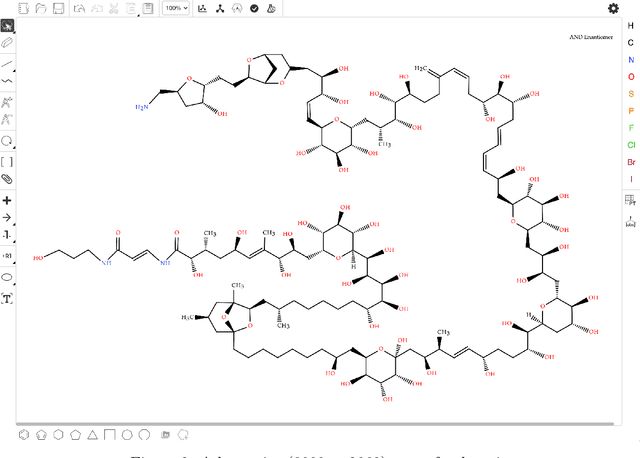
Molecular structures are always depicted as 2D printed form in scientific documents like journal papers and patents. However, these 2D depictions are not machine-readable. Due to a backlog of decades and an increasing amount of these printed literature, there is a high demand for the translation of printed depictions into machine-readable formats, which is known as Optical Chemical Structure Recognition (OCSR). Most OCSR systems developed over the last three decades follow a rule-based approach where the key step of vectorization of the depiction is based on the interpretation of vectors and nodes as bonds and atoms. Here, we present a practical software MolMiner, which is primarily built up using deep neural networks originally developed for semantic segmentation and object detection to recognize atom and bond elements from documents. These recognized elements can be easily connected as a molecular graph with distance-based construction algorithm. We carefully evaluate our software on four benchmark datasets with the state-of-the-art performance. Various real application scenarios are also tested, yielding satisfactory outcomes. The free download links of Mac and Windows versions are available: Mac: https://molminer-cdn.iipharma.cn/pharma-mind/artifact/latest/mac/PharmaMind-mac-latest-setup.dmg and Windows: https://molminer-cdn.iipharma.cn/pharma-mind/artifact/latest/win/PharmaMind-win-latest-setup.exe