 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Capsule-Sized Multi-Wavelength Wireless Optical System for Edge-AI-Based Classification of Gastrointestinal Bleeding Flow Rate
Jan 25, 2026Post-endoscopic gastrointestinal (GI) rebleeding frequently occurs within the first 72 hours after therapeutic hemostasis and remains a major cause of early morbidity and mortality. Existing non-invasive monitoring approaches primarily provide binary blood detection and lack quantitative assessment of bleeding severity or flow dynamic, limiting their ability to support timely clinical decision-making during this high-risk period. In this work, we developed a capsule-sized, multi-wavelength optical sensing wireless platform for order-of-magnitude-level classification of GI bleeding flow rate, leveraging transmission spectroscopy and low-power edge artificial intelligence. The system performs time-resolved, multi-spectral measurements and employs a lightweight two-dimensional convolutional neural network for on-device flow-rate classification, with physics-based validation confirming consistency with wavelength-dependent hemoglobin absorption behavior. In controlled in vitro experiments under simulated gastric conditions, the proposed approach achieved an overall classification accuracy of 98.75% across multiple bleeding flow-rate levels while robustly distinguishing diverse non-blood gastrointestinal interference. By performing embedded inference directly on the capsule electronics, the system reduced overall energy consumption by approximately 88% compared with continuous wireless transmission of raw data, making prolonged, battery-powered operation feasible. Extending capsule-based diagnostics beyond binary blood detection toward continuous, site-specific assessment of bleeding severity, this platform has the potential to support earlier identification of clinically significant rebleeding and inform timely re-intervention during post-endoscopic surveillance.
EMemBench: Interactive Benchmarking of Episodic Memory for VLM Agents
Jan 23, 2026We introduce EMemBench, a programmatic benchmark for evaluating long-term memory of agents through interactive games. Rather than using a fixed set of questions, EMemBench generates questions from each agent's own trajectory, covering both text and visual game environments. Each template computes verifiable ground truth from underlying game signals, with controlled answerability and balanced coverage over memory skills: single/multi-hop recall, induction, temporal, spatial, logical, and adversarial. We evaluate memory agents with strong LMs/VLMs as backbones, using in-context prompting as baselines. Across 15 text games and multiple visual seeds, results are far from saturated: induction and spatial reasoning are persistent bottlenecks, especially in visual setting. Persistent memory yields clear gains for open backbones on text games, but improvements are less consistent for VLM agents, suggesting that visually grounded episodic memory remains an open challenge. A human study further confirms the difficulty of EMemBench.
Graph-Anchored Knowledge Indexing for Retrieval-Augmented Generation
Jan 23, 2026Retrieval-Augmented Generation (RAG) has emerged as a dominant paradigm for mitigating hallucinations in Large Language Models (LLMs) by incorporating external knowledge. Nevertheless, effectively integrating and interpreting key evidence scattered across noisy documents remains a critical challenge for existing RAG systems. In this paper, we propose GraphAnchor, a novel Graph-Anchored Knowledge Indexing approach that reconceptualizes graph structures from static knowledge representations into active, evolving knowledge indices. GraphAnchor incrementally updates a graph during iterative retrieval to anchor salient entities and relations, yielding a structured index that guides the LLM in evaluating knowledge sufficiency and formulating subsequent subqueries. The final answer is generated by jointly leveraging all retrieved documents and the final evolved graph. Experiments on four multi-hop question answering benchmarks demonstrate the effectiveness of GraphAnchor, and reveal that GraphAnchor modulates the LLM's attention to more effectively associate key information distributed in retrieved documents. All code and data are available at https://github.com/NEUIR/GraphAnchor.
Long-Chain Reasoning Distillation via Adaptive Prefix Alignment
Jan 15, 2026Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities, particularly in solving complex mathematical problems. Recent studies show that distilling long reasoning trajectories can effectively enhance the reasoning performance of small-scale student models. However, teacher-generated reasoning trajectories are often excessively long and structurally complex, making them difficult for student models to learn. This mismatch leads to a gap between the provided supervision signal and the learning capacity of the student model. To address this challenge, we propose Prefix-ALIGNment distillation (P-ALIGN), a framework that fully exploits teacher CoTs for distillation through adaptive prefix alignment. Specifically, P-ALIGN adaptively truncates teacher-generated reasoning trajectories by determining whether the remaining suffix is concise and sufficient to guide the student model. Then, P-ALIGN leverages the teacher-generated prefix to supervise the student model, encouraging effective prefix alignment. Experiments on multiple mathematical reasoning benchmarks demonstrate that P-ALIGN outperforms all baselines by over 3%. Further analysis indicates that the prefixes constructed by P-ALIGN provide more effective supervision signals, while avoiding the negative impact of redundant and uncertain reasoning components. All code is available at https://github.com/NEUIR/P-ALIGN.
Structured Knowledge Representation through Contextual Pages for Retrieval-Augmented Generation
Jan 14, 2026Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by incorporating external knowledge. Recently, some works have incorporated iterative knowledge accumulation processes into RAG models to progressively accumulate and refine query-related knowledge, thereby constructing more comprehensive knowledge representations. However, these iterative processes often lack a coherent organizational structure, which limits the construction of more comprehensive and cohesive knowledge representations. To address this, we propose PAGER, a page-driven autonomous knowledge representation framework for RAG. PAGER first prompts an LLM to construct a structured cognitive outline for a given question, which consists of multiple slots representing a distinct knowledge aspect. Then, PAGER iteratively retrieves and refines relevant documents to populate each slot, ultimately constructing a coherent page that serves as contextual input for guiding answer generation. Experiments on multiple knowledge-intensive benchmarks and backbone models show that PAGER consistently outperforms all RAG baselines. Further analyses demonstrate that PAGER constructs higher-quality and information-dense knowledge representations, better mitigates knowledge conflicts, and enables LLMs to leverage external knowledge more effectively. All code is available at https://github.com/OpenBMB/PAGER.
What Do LLM Agents Know About Their World? Task2Quiz: A Paradigm for Studying Environment Understanding
Jan 14, 2026Large language model (LLM) agents have demonstrated remarkable capabilities in complex decision-making and tool-use tasks, yet their ability to generalize across varying environments remains a under-examined concern. Current evaluation paradigms predominantly rely on trajectory-based metrics that measure task success, while failing to assess whether agents possess a grounded, transferable model of the environment. To address this gap, we propose Task-to-Quiz (T2Q), a deterministic and automated evaluation paradigm designed to decouple task execution from world-state understanding. We instantiate this paradigm in T2QBench, a suite comprising 30 environments and 1,967 grounded QA pairs across multiple difficulty levels. Our extensive experiments reveal that task success is often a poor proxy for environment understanding, and that current memory machanism can not effectively help agents acquire a grounded model of the environment. These findings identify proactive exploration and fine-grained state representation as primary bottlenecks, offering a robust foundation for developing more generalizable autonomous agents.
ReCUT: Balancing Reasoning Length and Accuracy in LLMs via Stepwise Trails and Preference Optimization
Jun 12, 2025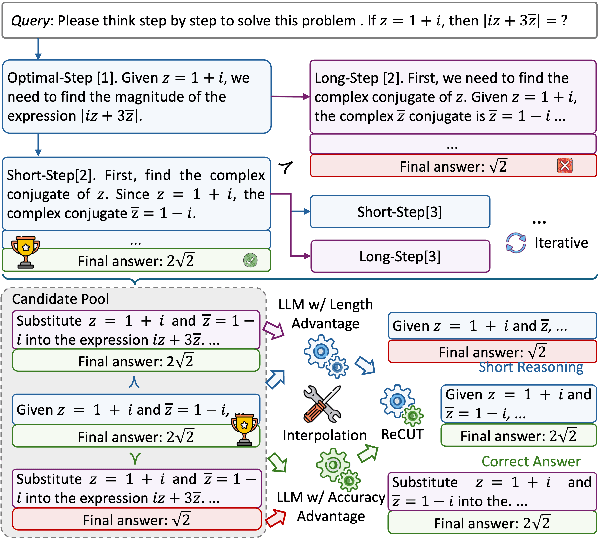
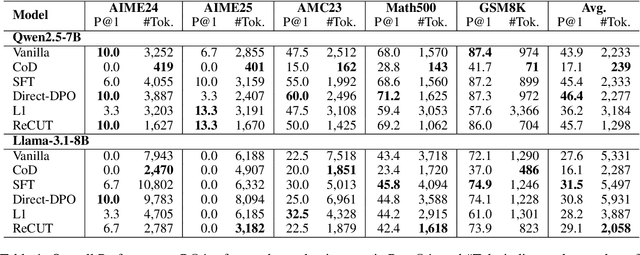
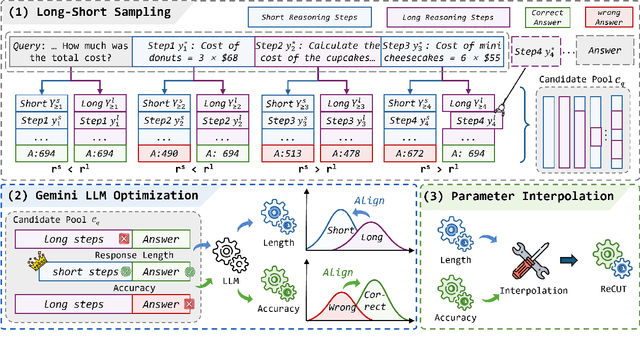
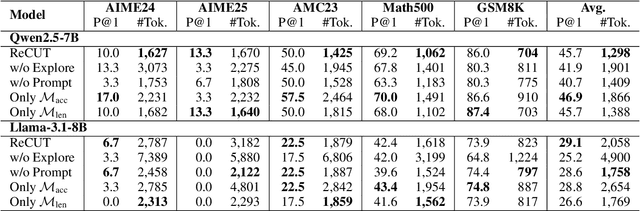
Recent advances in Chain-of-Thought (CoT) prompting have substantially improved the reasoning capabilities of Large Language Models (LLMs). However, these methods often suffer from overthinking, leading to unnecessarily lengthy or redundant reasoning traces. Existing approaches attempt to mitigate this issue through curating multiple reasoning chains for training LLMs, but their effectiveness is often constrained by the quality of the generated data and prone to overfitting. To address the challenge, we propose Reasoning Compression ThroUgh Stepwise Trials (ReCUT), a novel method aimed at balancing the accuracy and length of reasoning trajectory. Specifically, ReCUT employs a stepwise exploration mechanism and a long-short switched sampling strategy, enabling LLMs to incrementally generate diverse reasoning paths. These paths are evaluated and used to construct preference pairs to train two specialized models (Gemini LLMs)-one optimized for reasoning accuracy, the other for shorter reasoning. A final integrated model is obtained by interpolating the parameters of these two models. Experimental results across multiple math reasoning datasets and backbone models demonstrate that ReCUT significantly reduces reasoning lengths by approximately 30-50%, while maintaining or improving reasoning accuracy compared to various baselines. All codes and data will be released via https://github.com/NEUIR/ReCUT.
ClueAnchor: Clue-Anchored Knowledge Reasoning Exploration and Optimization for Retrieval-Augmented Generation
May 30, 2025Retrieval-Augmented Generation (RAG) augments Large Language Models (LLMs) with external knowledge to improve factuality. However, existing RAG systems frequently underutilize the retrieved documents, failing to extract and integrate the key clues needed to support faithful and interpretable reasoning, especially in cases where relevant evidence is implicit, scattered, or obscured by noise. To address this issue, we propose ClueAnchor, a novel framework for enhancing RAG via clue-anchored reasoning exploration and optimization. ClueAnchor extracts key clues from retrieved content and generates multiple reasoning paths based on different knowledge configurations, optimizing the model by selecting the most effective one through reward-based preference optimization. Experiments show that ClueAnchor significantly outperforms prior RAG baselines in reasoning completeness and robustness. Further analysis confirms its strong resilience to noisy or partially relevant retrieved content, as well as its capability to identify supporting evidence even in the absence of explicit clue supervision during inference.
EULER: Enhancing the Reasoning Ability of Large Language Models through Error-Induced Learning
May 28, 2025Large Language Models (LLMs) have demonstrated strong reasoning capabilities and achieved promising results in mathematical problem-solving tasks. Learning from errors offers the potential to further enhance the performance of LLMs during Supervised Fine-Tuning (SFT). However, the errors in synthesized solutions are typically gathered from sampling trails, making it challenging to generate solution errors for each mathematical problem. This paper introduces the Error-IndUced LEaRning (EULER) model, which aims to develop an error exposure model that generates high-quality solution errors to enhance the mathematical reasoning capabilities of LLMs. Specifically, EULER optimizes the error exposure model to increase the generation probability of self-made solution errors while utilizing solutions produced by a superior LLM to regularize the generation quality. Our experiments across various mathematical problem datasets demonstrate the effectiveness of the EULER model, achieving an improvement of over 4% compared to all baseline models. Further analysis reveals that EULER is capable of synthesizing more challenging and educational solution errors, which facilitate both the training and inference processes of LLMs. All codes are available at https://github.com/NEUIR/EULER.
PoseX: AI Defeats Physics Approaches on Protein-Ligand Cross Docking
May 03, 2025Recently, significant progress has been made in protein-ligand docking, especially in modern deep learning methods, and some benchmarks were proposed, e.g., PoseBench, Plinder. However, these benchmarks suffer from less practical evaluation setups (e.g., blind docking, self docking), or heavy framework that involves training, raising challenges to assess docking methods efficiently. To fill this gap, we proposed PoseX, an open-source benchmark focusing on self-docking and cross-docking, to evaluate the algorithmic advances practically and comprehensively. Specifically, first, we curate a new evaluation dataset with 718 entries for self docking and 1,312 for cross docking; second, we incorporate 22 docking methods across three methodological categories, including (1) traditional physics-based methods (e.g., Schr\"odinger Glide), (2) AI docking methods (e.g., DiffDock), (3) AI co-folding methods (e.g., AlphaFold3); third, we design a relaxation method as post-processing to minimize conformation energy and refine binding pose; fourth, we released a leaderboard to rank submitted models in real time. We draw some key insights via extensive experiments: (1) AI-based approaches have already surpassed traditional physics-based approaches in overall docking accuracy (RMSD). The longstanding generalization issues that have plagued AI molecular docking have been significantly alleviated in the latest models. (2) The stereochemical deficiencies of AI-based approaches can be greatly alleviated with post-processing relaxation. Combining AI docking methods with the enhanced relaxation method achieves the best performance to date. (3) AI co-folding methods commonly face ligand chirality issues, which cannot be resolved by relaxation. The code, curated dataset and leaderboard are released at https://github.com/CataAI/PoseX.