 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciCustom: A Framework for Custom Evaluation of Scientific Capabilities in Large Language Models
May 19, 2026Large language models (LLMs) are increasingly applied to scientific research, yet existing evaluations often fail to reflect the fine-grained capabilities required in practice. Most benchmarks are manually curated or domain-generic, limiting scalability and alignment with real scientific use cases. In this paper, we propose a new framework named SciCustom to address the problem. It enables the custom construction of benchmarks from large-scale scientific data to evaluate application-specific scientific capabilities in LLMs. SciCustom first organizes scientific knowledge into ontology-grounded knowledge units with controlled granularity and trains a tagger to map large-scale data instances into this knowledge space. Given a custom requirement, relevant knowledge units are identified via voting-based multi-model consensus. These units enable relevance-aware benchmark retrieval via binary search, followed by proxy subset selection and data-grounded benchmark generation for efficient evaluation. Experiments in chemistry and healthcare demonstrate that SciCustom reveals fine-grained differences in LLM scientific capabilities that standard benchmarks overlook, while requiring neither expert annotation nor synthetic question generation. This work provides a scalable and application-aware foundation for benchmarking scientific capabilities in LLMs. The source code is available at https://github.com/yjwtheonly/SciCustom.
Privacy-Preserving EHR Data Transformation via Geometric Operators: A Human-AI Co-Design Technical Report
Mar 24, 2026Electronic health records (EHRs) and other real-world clinical data are essential for clinical research, medical artificial intelligence, and life science, but their sharing is severely limited by privacy, governance, and interoperability constraints. These barriers create persistent data silos that hinder multi-center studies, large-scale model development, and broader biomedical discovery. Existing privacy-preserving approaches, including multi-party computation and related cryptographic techniques, provide strong protection but often introduce substantial computational overhead, reducing the efficiency of large-scale machine learning and foundation-model training. In addition, many such methods make data usable for restricted computation while leaving them effectively invisible to clinicians and researchers, limiting their value in workflows that still require direct inspection, exploratory analysis, and human interpretation. We propose a real-world-data transformation framework for privacy-preserving sharing of structured clinical records. Instead of converting data into opaque representations, our approach constructs transformed numeric views that preserve medical semantics and major statistical properties while, under a clearly specified threat model, provably breaking direct linkage between those views and protected patient-level attributes. Through collaboration between computer scientists and the AI agent \textbf{SciencePal}, acting as a constrained tool inventor under human guidance, we design three transformation operators that are non-reversible within this threat model, together with an additional mixing strategy for high-risk scenarios, supported by theoretical analysis and empirical evaluation under reconstruction, record linkage, membership inference, and attribute inference attacks.
VeriAgent: A Tool-Integrated Multi-Agent System with Evolving Memory for PPA-Aware RTL Code Generation
Mar 18, 2026LLMs have recently demonstrated strong capabilities in automatic RTL code generation, achieving high syntactic and functional correctness. However, most methods focus on functional correctness while overlooking critical physical design objectives, including Power, Performance, and Area. In this work, we propose a PPA-aware, tool-integrated multi-agent framework for high-quality verilog code generation. Our framework explicitly incorporates EDA tools into a closed-loop workflow composed of a \textit{Programmer Agent}, a \textit{Correctness Agent}, and a \textit{PPA Agent}, enabling joint optimization of functional correctness and physical metrics. To support continuous improvement without model retraining, we introduce an \textit{Evolved Memory Mechanism} that externalizes optimization experience into structured memory nodes. A dedicated memory manager dynamically maintains the memory pool and allows the system to refine strategies based on historical execution trajectories. Extensive experiments demonstrate that our approach achieves strong functional correctness while delivering significant improvements in PPA metrics. By integrating tool-driven feedback with structured and evolvable memory, our framework transforms RTL generation from one-shot reasoning into a continual, feedback-driven optimization process, providing a scalable pathway for deploying LLMs in real-world hardware design flows.
Cheers: Decoupling Patch Details from Semantic Representations Enables Unified Multimodal Comprehension and Generation
Mar 13, 2026A recent cutting-edge topic in multimodal modeling is to unify visual comprehension and generation within a single model. However, the two tasks demand mismatched decoding regimes and visual representations, making it non-trivial to jointly optimize within a shared feature space. In this work, we present Cheers, a unified multimodal model that decouples patch-level details from semantic representations, thereby stabilizing semantics for multimodal understanding and improving fidelity for image generation via gated detail residuals. Cheers includes three key components: (i) a unified vision tokenizer that encodes and compresses image latent states into semantic tokens for efficient LLM conditioning, (ii) an LLM-based Transformer that unifies autoregressive decoding for text generation and diffusion decoding for image generation, and (iii) a cascaded flow matching head that decodes visual semantics first and then injects semantically gated detail residuals from the vision tokenizer to refine high-frequency content. Experiments on popular benchmarks demonstrate that Cheers matches or surpasses advanced UMMs in both visual understanding and generation. Cheers also achieves 4x token compression, enabling more efficient high-resolution image encoding and generation. Notably, Cheers outperforms the Tar-1.5B on the popular benchmarks GenEval and MMBench, while requiring only 20% of the training cost, indicating effective and efficient (i.e., 4x token compression) unified multimodal modeling. We will release all code and data for future research.
Alpha Discovery via Grammar-Guided Learning and Search
Jan 29, 2026Automatically discovering formulaic alpha factors is a central problem in quantitative finance. Existing methods often ignore syntactic and semantic constraints, relying on exhaustive search over unstructured and unbounded spaces. We present AlphaCFG, a grammar-based framework for defining and discovering alpha factors that are syntactically valid, financially interpretable, and computationally efficient. AlphaCFG uses an alpha-oriented context-free grammar to define a tree-structured, size-controlled search space, and formulates alpha discovery as a tree-structured linguistic Markov decision process, which is then solved using a grammar-aware Monte Carlo Tree Search guided by syntax-sensitive value and policy networks. Experiments on Chinese and U.S. stock market datasets show that AlphaCFG outperforms state-of-the-art baselines in both search efficiency and trading profitability. Beyond trading strategies, AlphaCFG serves as a general framework for symbolic factor discovery and refinement across quantitative finance, including asset pricing and portfolio construction.
MMCTOP: A Multimodal Textualization and Mixture-of-Experts Framework for Clinical Trial Outcome Prediction
Dec 26, 2025Addressing the challenge of multimodal data fusion in high-dimensional biomedical informatics, we propose MMCTOP, a MultiModal Clinical-Trial Outcome Prediction framework that integrates heterogeneous biomedical signals spanning (i) molecular structure representations, (ii) protocol metadata and long-form eligibility narratives, and (iii) disease ontologies. MMCTOP couples schema-guided textualization and input-fidelity validation with modality-aware representation learning, in which domain-specific encoders generate aligned embeddings that are fused by a transformer backbone augmented with a drug-disease-conditioned sparse Mixture-of-Experts (SMoE). This design explicitly supports specialization across therapeutic and design subspaces while maintaining scalable computation through top-k routing. MMCTOP achieves consistent improvements in precision, F1, and AUC over unimodal and multimodal baselines on benchmark datasets, and ablations show that schema-guided textualization and selective expert routing contribute materially to performance and stability. We additionally apply temperature scaling to obtain calibrated probabilities, ensuring reliable risk estimation for downstream decision support. Overall, MMCTOP advances multimodal trial modeling by combining controlled narrative normalization, context-conditioned expert fusion, and operational safeguards aimed at auditability and reproducibility in biomedical informatics.
A Graph-Theoretical Perspective on Law Design for Multiagent Systems
Nov 09, 2025A law in a multiagent system is a set of constraints imposed on agents' behaviours to avoid undesirable outcomes. The paper considers two types of laws: useful laws that, if followed, completely eliminate the undesirable outcomes and gap-free laws that guarantee that at least one agent can be held responsible each time an undesirable outcome occurs. In both cases, we study the problem of finding a law that achieves the desired result by imposing the minimum restrictions. We prove that, for both types of laws, the minimisation problem is NP-hard even in the simple case of one-shot concurrent interactions. We also show that the approximation algorithm for the vertex cover problem in hypergraphs could be used to efficiently approximate the minimum laws in both cases.
SpaceTrack-TimeSeries: Time Series Dataset towards Satellite Orbit Analysis
Jun 16, 2025With the rapid advancement of aerospace technology and the large-scale deployment of low Earth orbit (LEO) satellite constellations, the challenges facing astronomical observations and deep space exploration have become increasingly pronounced. As a result, the demand for high-precision orbital data on space objects-along with comprehensive analyses of satellite positioning, constellation configurations, and deep space satellite dynamics-has grown more urgent. However, there remains a notable lack of publicly accessible, real-world datasets to support research in areas such as space object maneuver behavior prediction and collision risk assessment. This study seeks to address this gap by collecting and curating a representative dataset of maneuvering behavior from Starlink satellites. The dataset integrates Two-Line Element (TLE) catalog data with corresponding high-precision ephemeris data, thereby enabling a more realistic and multidimensional modeling of space object behavior. It provides valuable insights into practical deployment of maneuver detection methods and the evaluation of collision risks in increasingly congested orbital environments.
ReCUT: Balancing Reasoning Length and Accuracy in LLMs via Stepwise Trails and Preference Optimization
Jun 12, 2025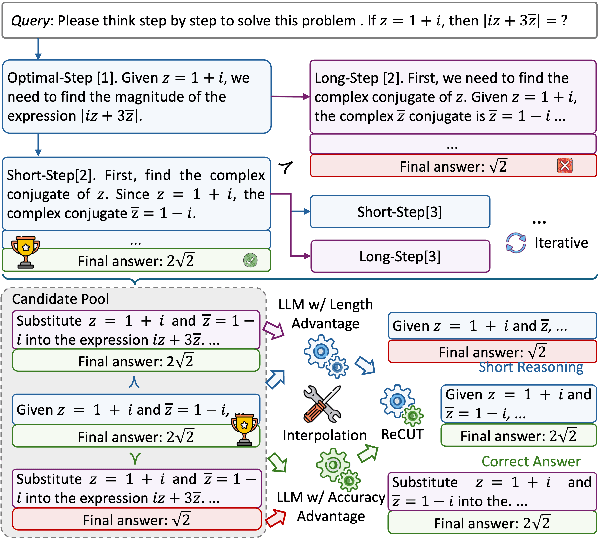
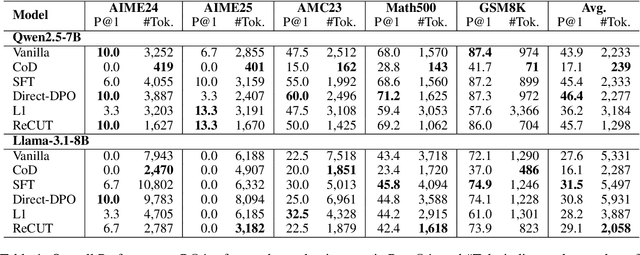
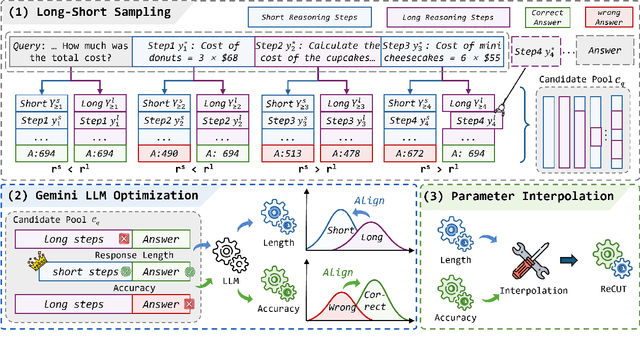
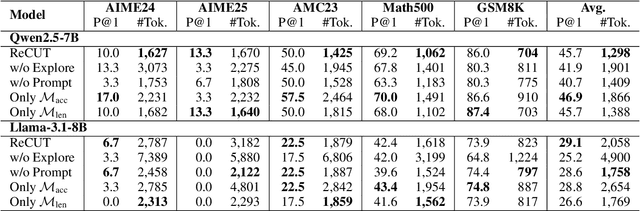
Recent advances in Chain-of-Thought (CoT) prompting have substantially improved the reasoning capabilities of Large Language Models (LLMs). However, these methods often suffer from overthinking, leading to unnecessarily lengthy or redundant reasoning traces. Existing approaches attempt to mitigate this issue through curating multiple reasoning chains for training LLMs, but their effectiveness is often constrained by the quality of the generated data and prone to overfitting. To address the challenge, we propose Reasoning Compression ThroUgh Stepwise Trials (ReCUT), a novel method aimed at balancing the accuracy and length of reasoning trajectory. Specifically, ReCUT employs a stepwise exploration mechanism and a long-short switched sampling strategy, enabling LLMs to incrementally generate diverse reasoning paths. These paths are evaluated and used to construct preference pairs to train two specialized models (Gemini LLMs)-one optimized for reasoning accuracy, the other for shorter reasoning. A final integrated model is obtained by interpolating the parameters of these two models. Experimental results across multiple math reasoning datasets and backbone models demonstrate that ReCUT significantly reduces reasoning lengths by approximately 30-50%, while maintaining or improving reasoning accuracy compared to various baselines. All codes and data will be released via https://github.com/NEUIR/ReCUT.
C-PATH: Conversational Patient Assistance and Triage in Healthcare System
Jun 07, 2025Navigating healthcare systems can be complex and overwhelming, creating barriers for patients seeking timely and appropriate medical attention. In this paper, we introduce C-PATH (Conversational Patient Assistance and Triage in Healthcare), a novel conversational AI system powered by large language models (LLMs) designed to assist patients in recognizing symptoms and recommending appropriate medical departments through natural, multi-turn dialogues. C-PATH is fine-tuned on medical knowledge, dialogue data, and clinical summaries using a multi-stage pipeline built on the LLaMA3 architecture. A core contribution of this work is a GPT-based data augmentation framework that transforms structured clinical knowledge from DDXPlus into lay-person-friendly conversations, allowing alignment with patient communication norms. We also implement a scalable conversation history management strategy to ensure long-range coherence. Evaluation with GPTScore demonstrates strong performance across dimensions such as clarity, informativeness, and recommendation accuracy. Quantitative benchmarks show that C-PATH achieves superior performance in GPT-rewritten conversational datasets, significantly outperforming domain-specific baselines. C-PATH represents a step forward in the development of user-centric, accessible, and accurate AI tools for digital health assistance and triage.