 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRI-Loss: A Learnable Residual-Informed Loss for Time Series Forecasting
Nov 13, 2025



Time series forecasting relies on predicting future values from historical data, yet most state-of-the-art approaches-including transformer and multilayer perceptron-based models-optimize using Mean Squared Error (MSE), which has two fundamental weaknesses: its point-wise error computation fails to capture temporal relationships, and it does not account for inherent noise in the data. To overcome these limitations, we introduce the Residual-Informed Loss (RI-Loss), a novel objective function based on the Hilbert-Schmidt Independence Criterion (HSIC). RI-Loss explicitly models noise structure by enforcing dependence between the residual sequence and a random time series, enabling more robust, noise-aware representations. Theoretically, we derive the first non-asymptotic HSIC bound with explicit double-sample complexity terms, achieving optimal convergence rates through Bernstein-type concentration inequalities and Rademacher complexity analysis. This provides rigorous guarantees for RI-Loss optimization while precisely quantifying kernel space interactions. Empirically, experiments across eight real-world benchmarks and five leading forecasting models demonstrate improvements in predictive performance, validating the effectiveness of our approach. Code will be made publicly available to ensure reproducibility.
ReCUT: Balancing Reasoning Length and Accuracy in LLMs via Stepwise Trails and Preference Optimization
Jun 12, 2025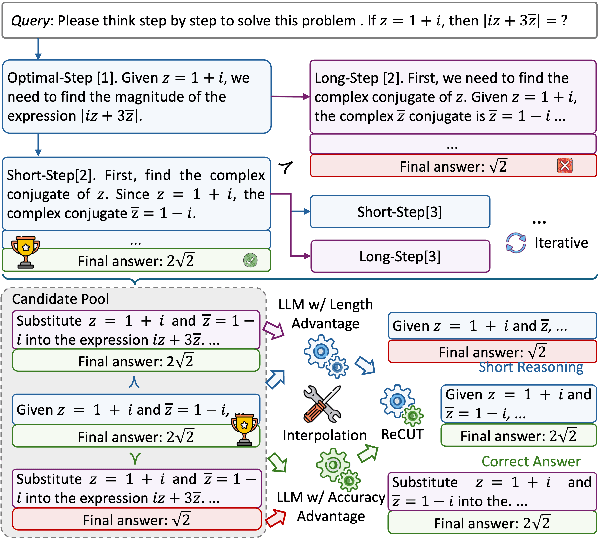
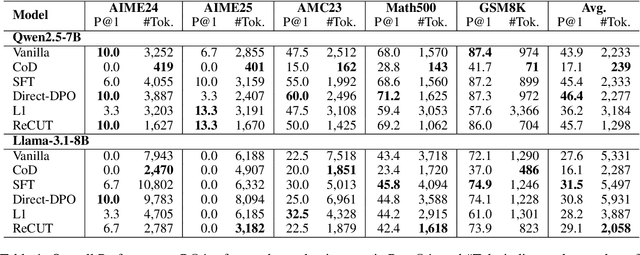
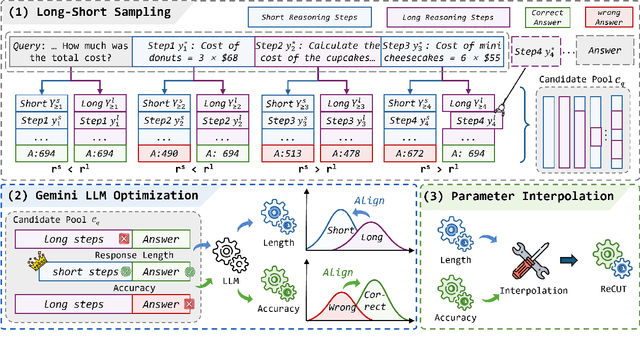
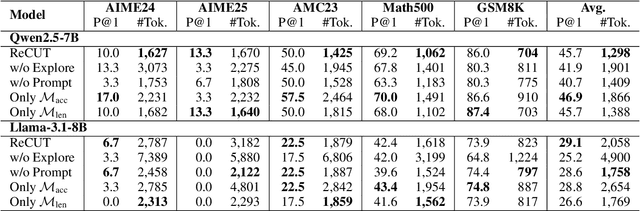
Recent advances in Chain-of-Thought (CoT) prompting have substantially improved the reasoning capabilities of Large Language Models (LLMs). However, these methods often suffer from overthinking, leading to unnecessarily lengthy or redundant reasoning traces. Existing approaches attempt to mitigate this issue through curating multiple reasoning chains for training LLMs, but their effectiveness is often constrained by the quality of the generated data and prone to overfitting. To address the challenge, we propose Reasoning Compression ThroUgh Stepwise Trials (ReCUT), a novel method aimed at balancing the accuracy and length of reasoning trajectory. Specifically, ReCUT employs a stepwise exploration mechanism and a long-short switched sampling strategy, enabling LLMs to incrementally generate diverse reasoning paths. These paths are evaluated and used to construct preference pairs to train two specialized models (Gemini LLMs)-one optimized for reasoning accuracy, the other for shorter reasoning. A final integrated model is obtained by interpolating the parameters of these two models. Experimental results across multiple math reasoning datasets and backbone models demonstrate that ReCUT significantly reduces reasoning lengths by approximately 30-50%, while maintaining or improving reasoning accuracy compared to various baselines. All codes and data will be released via https://github.com/NEUIR/ReCUT.
TSC: A Simple Two-Sided Constraint against Over-Smoothing
Aug 06, 2024



Graph Convolutional Neural Network (GCN), a widely adopted method for analyzing relational data, enhances node discriminability through the aggregation of neighboring information. Usually, stacking multiple layers can improve the performance of GCN by leveraging information from high-order neighbors. However, the increase of the network depth will induce the over-smoothing problem, which can be attributed to the quality and quantity of neighbors changing: (a) neighbor quality, node's neighbors become overlapping in high order, leading to aggregated information becoming indistinguishable, (b) neighbor quantity, the exponentially growing aggregated neighbors submerges the node's initial feature by recursively aggregating operations. Current solutions mainly focus on one of the above causes and seldom consider both at once. Aiming at tackling both causes of over-smoothing in one shot, we introduce a simple Two-Sided Constraint (TSC) for GCNs, comprising two straightforward yet potent techniques: random masking and contrastive constraint. The random masking acts on the representation matrix's columns to regulate the degree of information aggregation from neighbors, thus preventing the convergence of node representations. Meanwhile, the contrastive constraint, applied to the representation matrix's rows, enhances the discriminability of the nodes. Designed as a plug-in module, TSC can be easily coupled with GCN or SGC architectures. Experimental analyses on diverse real-world graph datasets verify that our approach markedly reduces the convergence of node's representation and the performance degradation in deeper GCN.
Hybrid Self-Attention Network for Machine Translation
Nov 01, 2018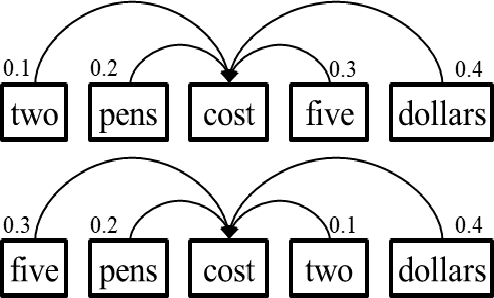
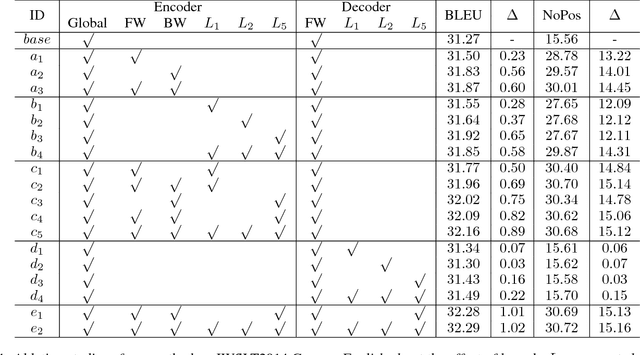
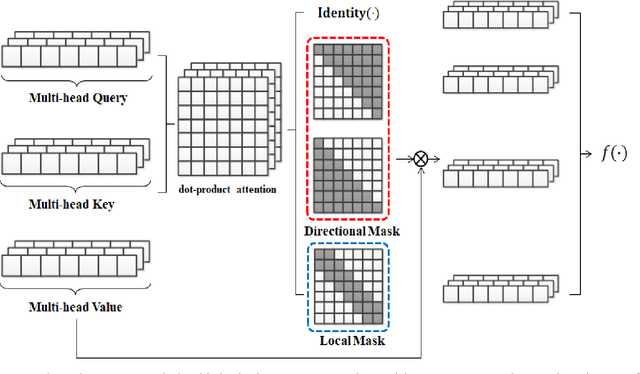

The encoder-decoder is the typical framework for Neural Machine Translation (NMT), and different structures have been developed for improving the translation performance. Transformer is one of the most promising structures, which can leverage the self-attention mechanism to capture the semantic dependency from global view. However, it cannot distinguish the relative position of different tokens very well, such as the tokens located at the left or right of the current token, and cannot focus on the local information around the current token either. To alleviate these problems, we propose a novel attention mechanism named Hybrid Self-Attention Network (HySAN) which accommodates some specific-designed masks for self-attention network to extract various semantic, such as the global/local information, the left/right part context. Finally, a squeeze gate is introduced to combine different kinds of SANs for fusion. Experimental results on three machine translation tasks show that our proposed framework outperforms the Transformer baseline significantly and achieves superior results over state-of-the-art NMT systems.