 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on Neural Routing Solvers
Feb 25, 2026Neural routing solvers (NRSs) that leverage deep learning to tackle vehicle routing problems have demonstrated notable potential for practical applications. By learning implicit heuristic rules from data, NRSs replace the handcrafted counterparts in classic heuristic frameworks, thereby reducing reliance on costly manual design and trial-and-error adjustments. This survey makes two main contributions: (1) The heuristic nature of NRSs is highlighted, and existing NRSs are reviewed from the perspective of heuristics. A hierarchical taxonomy based on heuristic principles is further introduced. (2) A generalization-focused evaluation pipeline is proposed to address limitations of the conventional pipeline. Comparative benchmarking of representative NRSs across both pipelines uncovers a series of previously unreported gaps in current research.
Hybrid Causal Identification and Causal Mechanism Clustering
Jul 29, 2025Bivariate causal direction identification is a fundamental and vital problem in the causal inference field. Among binary causal methods, most methods based on additive noise only use one single causal mechanism to construct a causal model. In the real world, observations are always collected in different environments with heterogeneous causal relationships. Therefore, on observation data, this paper proposes a Mixture Conditional Variational Causal Inference model (MCVCI) to infer heterogeneous causality. Specifically, according to the identifiability of the Hybrid Additive Noise Model (HANM), MCVCI combines the superior fitting capabilities of the Gaussian mixture model and the neural network and elegantly uses the likelihoods obtained from the probabilistic bounds of the mixture conditional variational auto-encoder as causal decision criteria. Moreover, we model the casual heterogeneity into cluster numbers and propose the Mixture Conditional Variational Causal Clustering (MCVCC) method, which can reveal causal mechanism expression. Compared with state-of-the-art methods, the comprehensive best performance demonstrates the effectiveness of the methods proposed in this paper on several simulated and real data.
Sharper Error Bounds in Late Fusion Multi-view Clustering Using Eigenvalue Proportion
Dec 24, 2024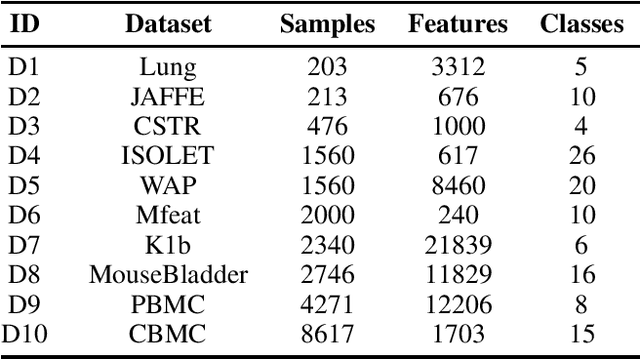

Multi-view clustering (MVC) aims to integrate complementary information from multiple views to enhance clustering performance. Late Fusion Multi-View Clustering (LFMVC) has shown promise by synthesizing diverse clustering results into a unified consensus. However, current LFMVC methods struggle with noisy and redundant partitions and often fail to capture high-order correlations across views. To address these limitations, we present a novel theoretical framework for analyzing the generalization error bounds of multiple kernel $k$-means, leveraging local Rademacher complexity and principal eigenvalue proportions. Our analysis establishes a convergence rate of $\mathcal{O}(1/n)$, significantly improving upon the existing rate in the order of $\mathcal{O}(\sqrt{k/n})$. Building on this insight, we propose a low-pass graph filtering strategy within a multiple linear $k$-means framework to mitigate noise and redundancy, further refining the principal eigenvalue proportion and enhancing clustering accuracy. Experimental results on benchmark datasets confirm that our approach outperforms state-of-the-art methods in clustering performance and robustness. The related codes is available at https://github.com/csliangdu/GMLKM .
k-HyperEdge Medoids for Clustering Ensemble
Dec 11, 2024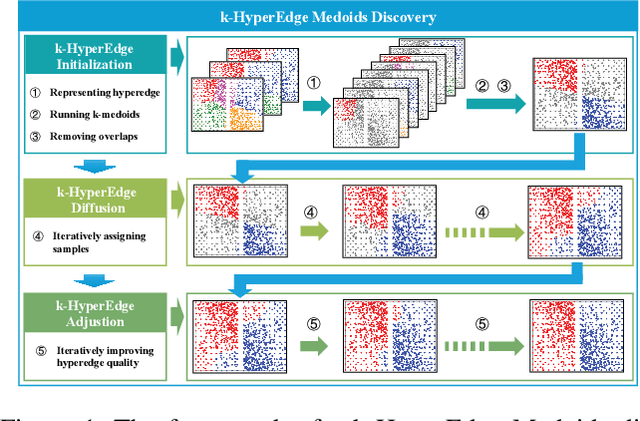
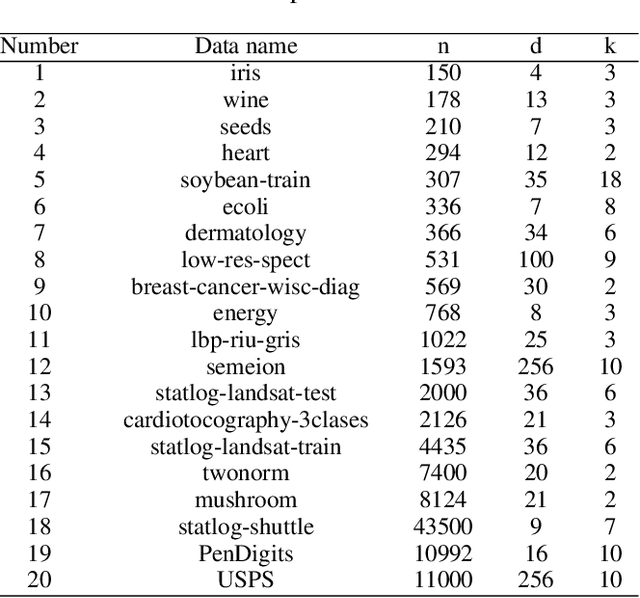
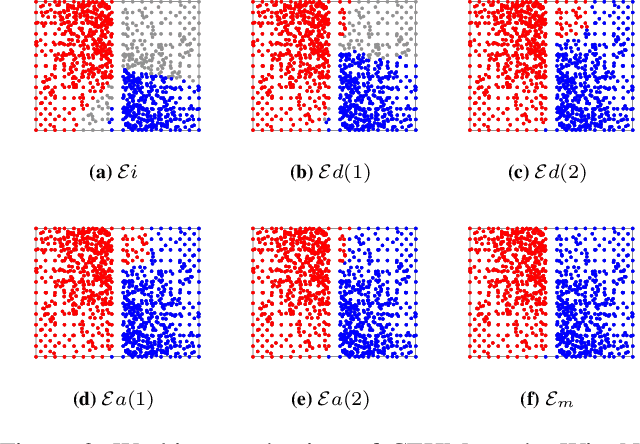
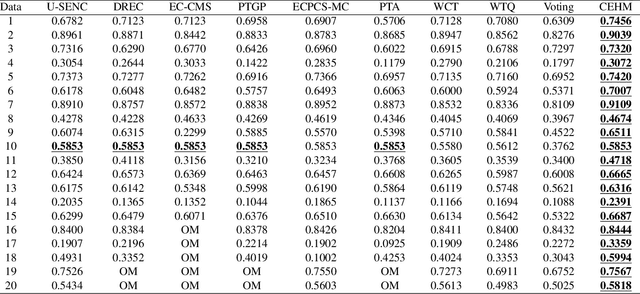
Clustering ensemble has been a popular research topic in data science due to its ability to improve the robustness of the single clustering method. Many clustering ensemble methods have been proposed, most of which can be categorized into clustering-view and sample-view methods. The clustering-view method is generally efficient, but it could be affected by the unreliability that existed in base clustering results. The sample-view method shows good performance, while the construction of the pairwise sample relation is time-consuming. In this paper, the clustering ensemble is formulated as a k-HyperEdge Medoids discovery problem and a clustering ensemble method based on k-HyperEdge Medoids that considers the characteristics of the above two types of clustering ensemble methods is proposed. In the method, a set of hyperedges is selected from the clustering view efficiently, then the hyperedges are diffused and adjusted from the sample view guided by a hyperedge loss function to construct an effective k-HyperEdge Medoid set. The loss function is mainly reduced by assigning samples to the hyperedge with the highest degree of belonging. Theoretical analyses show that the solution can approximate the optimal, the assignment method can gradually reduce the loss function, and the estimation of the belonging degree is statistically reasonable. Experiments on artificial data show the working mechanism of the proposed method. The convergence of the method is verified by experimental analysis of twenty data sets. The effectiveness and efficiency of the proposed method are also verified on these data, with nine representative clustering ensemble algorithms as reference.
Theory-inspired Label Shift Adaptation via Aligned Distribution Mixture
Nov 05, 2024



As a prominent challenge in addressing real-world issues within a dynamic environment, label shift, which refers to the learning setting where the source (training) and target (testing) label distributions do not match, has recently received increasing attention. Existing label shift methods solely use unlabeled target samples to estimate the target label distribution, and do not involve them during the classifier training, resulting in suboptimal utilization of available information. One common solution is to directly blend the source and target distributions during the training of the target classifier. However, we illustrate the theoretical deviation and limitations of the direct distribution mixture in the label shift setting. To tackle this crucial yet unexplored issue, we introduce the concept of aligned distribution mixture, showcasing its theoretical optimality and generalization error bounds. By incorporating insights from generalization theory, we propose an innovative label shift framework named as Aligned Distribution Mixture (ADM). Within this framework, we enhance four typical label shift methods by introducing modifications to the classifier training process. Furthermore, we also propose a one-step approach that incorporates a pioneering coupling weight estimation strategy. Considering the distinctiveness of the proposed one-step approach, we develop an efficient bi-level optimization strategy. Experimental results demonstrate the effectiveness of our approaches, together with their effectiveness in COVID-19 diagnosis applications.
Theoretically Guaranteed Distribution Adaptable Learning
Nov 05, 2024In many open environment applications, data are collected in the form of a stream, which exhibits an evolving distribution over time. How to design algorithms to track these evolving data distributions with provable guarantees, particularly in terms of the generalization ability, remains a formidable challenge. To handle this crucial but rarely studied problem and take a further step toward robust artificial intelligence, we propose a novel framework called Distribution Adaptable Learning (DAL). It enables the model to effectively track the evolving data distributions. By Encoding Feature Marginal Distribution Information (EFMDI), we broke the limitations of optimal transport to characterize the environmental changes and enable model reuse across diverse data distributions. It can enhance the reusable and evolvable properties of DAL in accommodating evolving distributions. Furthermore, to obtain the model interpretability, we not only analyze the generalization error bound of the local step in the evolution process, but also investigate the generalization error bound associated with the entire classifier trajectory of the evolution based on the Fisher-Rao distance. For demonstration, we also present two special cases within the framework, together with their optimizations and convergence analyses. Experimental results over both synthetic and real-world data distribution evolving tasks validate the effectiveness and practical utility of the proposed framework.
TSC: A Simple Two-Sided Constraint against Over-Smoothing
Aug 06, 2024



Graph Convolutional Neural Network (GCN), a widely adopted method for analyzing relational data, enhances node discriminability through the aggregation of neighboring information. Usually, stacking multiple layers can improve the performance of GCN by leveraging information from high-order neighbors. However, the increase of the network depth will induce the over-smoothing problem, which can be attributed to the quality and quantity of neighbors changing: (a) neighbor quality, node's neighbors become overlapping in high order, leading to aggregated information becoming indistinguishable, (b) neighbor quantity, the exponentially growing aggregated neighbors submerges the node's initial feature by recursively aggregating operations. Current solutions mainly focus on one of the above causes and seldom consider both at once. Aiming at tackling both causes of over-smoothing in one shot, we introduce a simple Two-Sided Constraint (TSC) for GCNs, comprising two straightforward yet potent techniques: random masking and contrastive constraint. The random masking acts on the representation matrix's columns to regulate the degree of information aggregation from neighbors, thus preventing the convergence of node representations. Meanwhile, the contrastive constraint, applied to the representation matrix's rows, enhances the discriminability of the nodes. Designed as a plug-in module, TSC can be easily coupled with GCN or SGC architectures. Experimental analyses on diverse real-world graph datasets verify that our approach markedly reduces the convergence of node's representation and the performance degradation in deeper GCN.
Deep Embedding Clustering Driven by Sample Stability
Jan 29, 2024


Deep clustering methods improve the performance of clustering tasks by jointly optimizing deep representation learning and clustering. While numerous deep clustering algorithms have been proposed, most of them rely on artificially constructed pseudo targets for performing clustering. This construction process requires some prior knowledge, and it is challenging to determine a suitable pseudo target for clustering. To address this issue, we propose a deep embedding clustering algorithm driven by sample stability (DECS), which eliminates the requirement of pseudo targets. Specifically, we start by constructing the initial feature space with an autoencoder and then learn the cluster-oriented embedding feature constrained by sample stability. The sample stability aims to explore the deterministic relationship between samples and all cluster centroids, pulling samples to their respective clusters and keeping them away from other clusters with high determinacy. We analyzed the convergence of the loss using Lipschitz continuity in theory, which verifies the validity of the model. The experimental results on five datasets illustrate that the proposed method achieves superior performance compared to state-of-the-art clustering approaches.
2D Human Pose Estimation with Explicit Anatomical Keypoints Structure Constraints
Dec 05, 2022Recently, human pose estimation mainly focuses on how to design a more effective and better deep network structure as human features extractor, and most designed feature extraction networks only introduce the position of each anatomical keypoint to guide their training process. However, we found that some human anatomical keypoints kept their topology invariance, which can help to localize them more accurately when detecting the keypoints on the feature map. But to the best of our knowledge, there is no literature that has specifically studied it. Thus, in this paper, we present a novel 2D human pose estimation method with explicit anatomical keypoints structure constraints, which introduces the topology constraint term that consisting of the differences between the distance and direction of the keypoint-to-keypoint and their groundtruth in the loss object. More importantly, our proposed model can be plugged in the most existing bottom-up or top-down human pose estimation methods and improve their performance. The extensive experiments on the benchmark dataset: COCO keypoint dataset, show that our methods perform favorably against the most existing bottom-up and top-down human pose estimation methods, especially for Lite-HRNet, when our model is plugged into it, its AP scores separately raise by 2.9\% and 3.3\% on COCO val2017 and test-dev2017 datasets.
Sparse Regularized Correlation Filter for UAV Object Tracking with adaptive Contextual Learning and Keyfilter Selection
May 07, 2022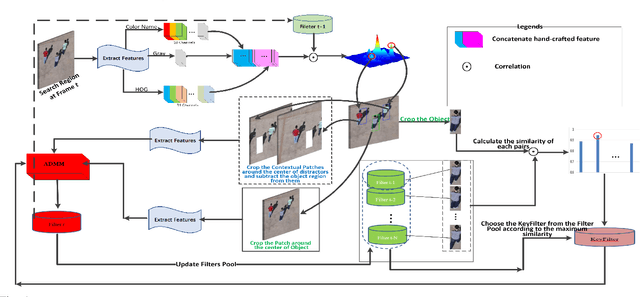
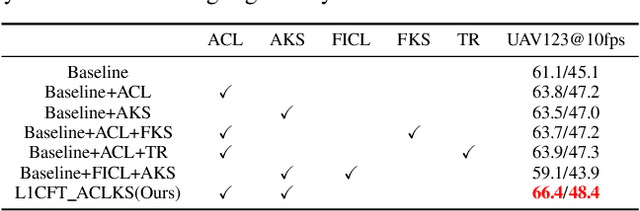
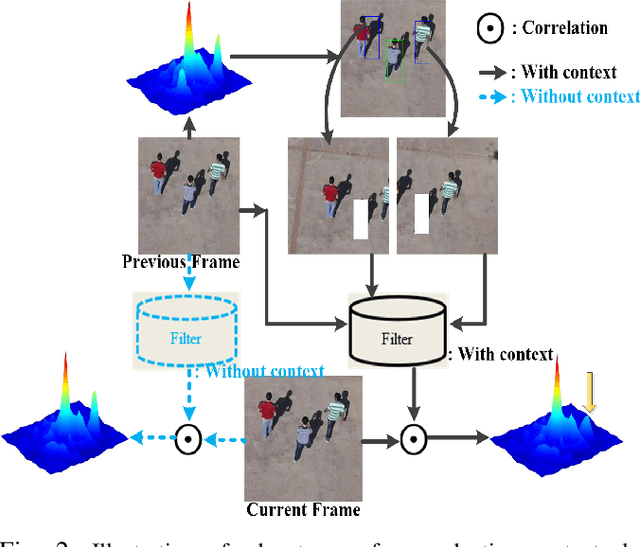

Recently, correlation filter has been widely applied in unmanned aerial vehicle (UAV) tracking due to its high frame rates, robustness and low calculation resources. However, it is fragile because of two inherent defects, i.e, boundary effect and filter corruption. Some methods by enlarging the search area can mitigate the boundary effect, yet introducing the undesired background distractors. Another approaches can alleviate the temporal degeneration of learned filters by introducing the temporal regularizer, which depends on the assumption that the filers between consecutive frames should be coherent. In fact, sometimes the filers at the ($t-1$)th frame is vulnerable to heavy occlusion from backgrounds, which causes that the assumption does not hold. To handle them, in this work, we propose a novel $\ell_{1}$ regularization correlation filter with adaptive contextual learning and keyfilter selection for UAV tracking. Firstly, we adaptively detect the positions of effective contextual distractors by the aid of the distribution of local maximum values on the response map of current frame which is generated by using the previous correlation filter model. Next, we eliminate inconsistent labels for the tracked target by removing one on each distractor and develop a new score scheme for each distractor. Then, we can select the keyfilter from the filters pool by finding the maximal similarity between the target at the current frame and the target template corresponding to each filter in the filters pool. Finally, quantitative and qualitative experiments on three authoritative UAV datasets show that the proposed method is superior to the state-of-the-art tracking methods based on correlation filter framework.