 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive residual learning for single image dehazing
Mar 14, 2021



The recent physical model-free dehazing methods have achieved state-of-the-art performances. However, without the guidance of physical models, the performances degrade rapidly when applied to real scenarios due to the unavailable or insufficient data problems. On the other hand, the physical model-based methods have better interpretability but suffer from multi-objective optimizations of parameters, which may lead to sub-optimal dehazing results. In this paper, a progressive residual learning strategy has been proposed to combine the physical model-free dehazing process with reformulated scattering model-based dehazing operations, which enjoys the merits of dehazing methods in both categories. Specifically, the global atmosphere light and transmission maps are interactively optimized with the aid of accurate residual information and preliminary dehazed restorations from the initial physical model-free dehazing process. The proposed method performs favorably against the state-of-the-art methods on public dehazing benchmarks with better model interpretability and adaptivity for complex hazy data.
Progressive Depth Learning for Single Image Dehazing
Feb 21, 2021

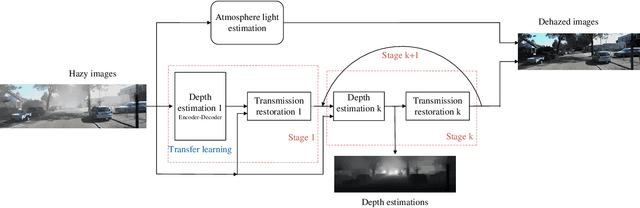

The formulation of the hazy image is mainly dominated by the reflected lights and ambient airlight. Existing dehazing methods often ignore the depth cues and fail in distant areas where heavier haze disturbs the visibility. However, we note that the guidance of the depth information for transmission estimation could remedy the decreased visibility as distances increase. In turn, the good transmission estimation could facilitate the depth estimation for hazy images. In this paper, a deep end-to-end model that iteratively estimates image depths and transmission maps is proposed to perform an effective depth prediction for hazy images and improve the dehazing performance with the guidance of depth information. The image depth and transmission map are progressively refined to better restore the dehazed image. Our approach benefits from explicitly modeling the inner relationship of image depth and transmission map, which is especially effective for distant hazy areas. Extensive results on the benchmarks demonstrate that our proposed network performs favorably against the state-of-the-art dehazing methods in terms of depth estimation and haze removal.
Discriminative Feature Learning with Foreground Attention for Person Re-Identification
Jul 04, 2018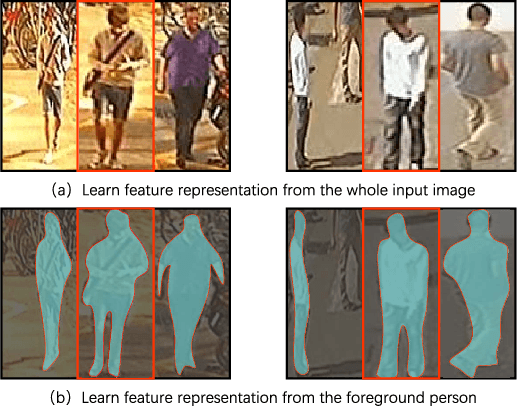
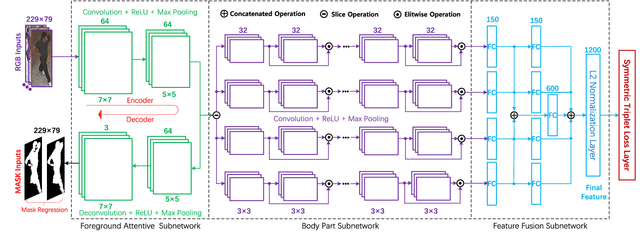
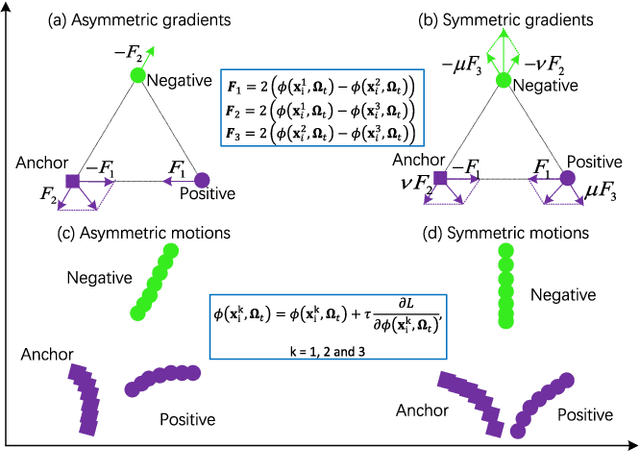
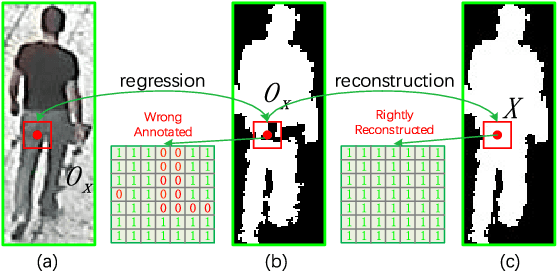
The performance of person re-identification (Re-ID) seriously depends on the camera environment, where the large cross-view appearance variations caused by mutual occlusions and background clutters have severely decreased the identification accuracy. Therefore, it is very essential to learn a feature representation that can adaptively emphasize the foreground of each input image. In this paper, we propose a simple yet effective deep neural network to solve the person Re-ID problem, which attempts to learn a discriminative feature representation by addressing the foreground of input images. Specifically, a novel foreground attentive neural network (FANN) is first built to strengthen the positive influence of foreground while weaken the side effect of background, in which an encoder and decoder subnetwork is carefully designed to drive the whole neural network to put its attention on the foreground of input images. Then, a novel symmetric triplet loss function is designed to enhance the feature learning capability by jointly minimizing the intra-class distance and maximizing the inter-class distance in each triplet unit. Training the deep neural network in an end-to-end fashion, a discriminative feature representation can be finally learned to find out the matched reference to the probe among various candidates in the gallery. Comprehensive experiments on several public benchmark datasets are conducted to evaluate the performance, which have shown clear improvements of our method as compared with the state-of-the-art approaches.
Single Image Super-resolution via a Lightweight Residual Convolutional Neural Network
Dec 06, 2017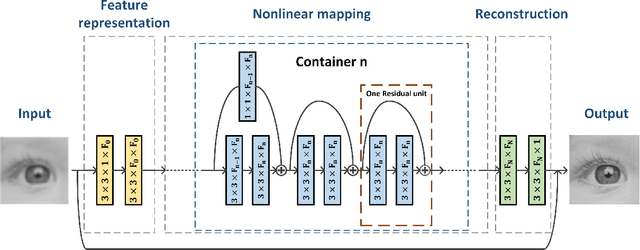



Recent years have witnessed great success of convolutional neural network (CNN) for various problems both in low and high level visions. Especially noteworthy is the residual network which was originally proposed to handle high-level vision problems and enjoys several merits. This paper aims to extend the merits of residual network, such as skip connection induced fast training, for a typical low-level vision problem, i.e., single image super-resolution. In general, the two main challenges of existing deep CNN for supper-resolution lie in the gradient exploding/vanishing problem and large numbers of parameters or computational cost as CNN goes deeper. Correspondingly, the skip connections or identity mapping shortcuts are utilized to avoid gradient exploding/vanishing problem. In addition, the skip connections have naturally centered the activation which led to better performance. To tackle with the second problem, a lightweight CNN architecture which has carefully designed width, depth and skip connections was proposed. In particular, a strategy of gradually varying the shape of network has been proposed for residual network. Different residual architectures for image super-resolution have also been compared. Experimental results have demonstrated that the proposed CNN model can not only achieve state-of-the-art PSNR and SSIM results for single image super-resolution but also produce visually pleasant results. This paper has extended the mmm 2017 oral conference paper with a considerable new analyses and more experiments especially from the perspective of centering activations and ensemble behaviors of residual network.
Single Image Super Resolution - When Model Adaptation Matters
Mar 31, 2017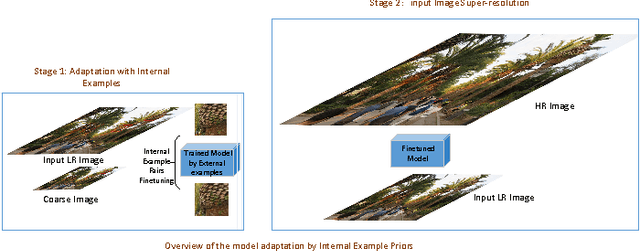
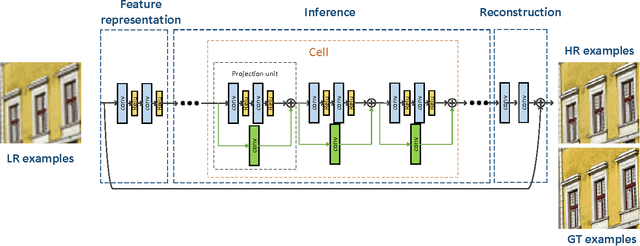


In the recent years impressive advances were made for single image super-resolution. Deep learning is behind a big part of this success. Deep(er) architecture design and external priors modeling are the key ingredients. The internal contents of the low resolution input image is neglected with deep modeling despite the earlier works showing the power of using such internal priors. In this paper we propose a novel deep convolutional neural network carefully designed for robustness and efficiency at both learning and testing. Moreover, we propose a couple of model adaptation strategies to the internal contents of the low resolution input image and analyze their strong points and weaknesses. By trading runtime and using internal priors we achieve 0.1 up to 0.3dB PSNR improvements over best reported results on standard datasets. Our adaptation especially favors images with repetitive structures or under large resolutions. Moreover, it can be combined with other simple techniques, such as back-projection or enhanced prediction, for further improvements.