 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMy Words Imply Your Opinion: Reader Agent-Based Propagation Enhancement for Personalized Implicit Emotion Analysis
Dec 10, 2024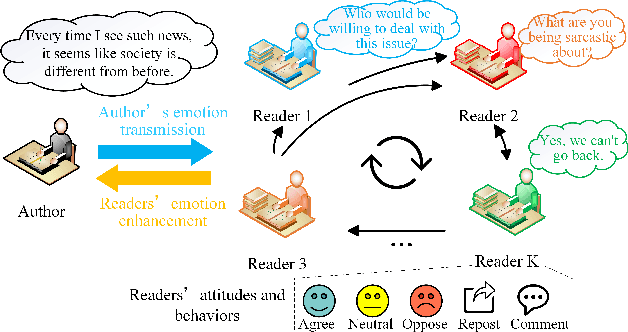
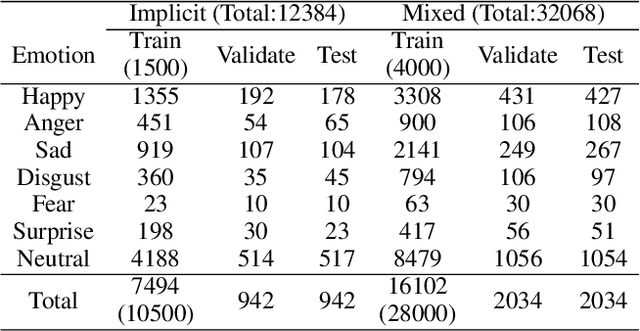
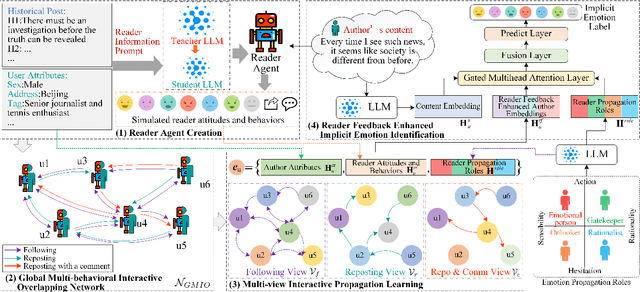
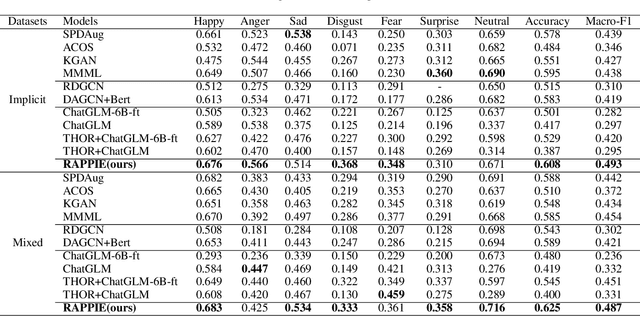
In implicit emotion analysis (IEA), the subtlety of emotional expressions makes it particularly sensitive to user-specific characteristics. Existing studies often inject personalization into the analysis by focusing on the authorial dimension of the emotional text. However, these methods overlook the potential influence of the intended reader on the reaction of implicit emotions. In this paper, we refine the IEA task to Personalized Implicit Emotion Analysis (PIEA) and introduce the RAPPIE model, a novel framework designed to address the issue of missing user information within this task. In particular, 1) we create reader agents based on the Large Language Model to simulate reader reactions, to address challenges of the spiral of silence and data incompleteness encountered when acquiring reader feedback information. 2) We establish a reader propagation role system and develop a role-aware emotion propagation multi-view graph learning model, which effectively deals with the sparsity of reader information by utilizing the distribution of propagation roles. 3) We annotate two Chinese PIEA datasets with detailed user metadata, thereby addressing the limitation of prior datasets that primarily focus on textual content annotation. Extensive experiments on these datasets indicate that the RAPPIE model outperforms current state-of-the-art baselines, highlighting the significance and efficacy of incorporating reader feedback into the PIEA process.
A Noncontact Technique for Wave Measurement Based on Thermal Stereography and Deep Learning
Aug 20, 2024
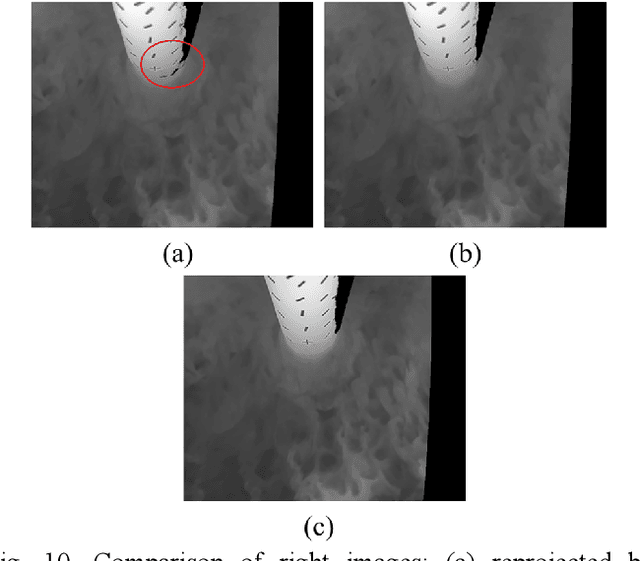

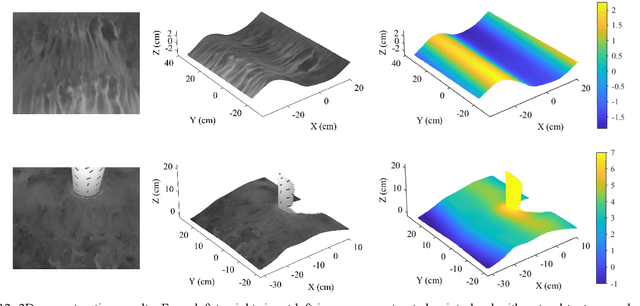
The accurate measurement of the wave field and its spatiotemporal evolution is essential in many hydrodynamic experiments and engineering applications. The binocular stereo imaging technique has been widely used to measure waves. However, the optical properties of indoor water surfaces, including transparency, specular reflection, and texture absence, pose challenges for image processing and stereo reconstruction. This study proposed a novel technique that combined thermal stereography and deep learning to achieve fully noncontact wave measurements. The optical imaging properties of water in the long-wave infrared spectrum were found to be suitable for stereo matching, effectively avoiding the issues in the visible-light spectrum. After capturing wave images using thermal stereo cameras, a reconstruction strategy involving deep learning techniques was proposed to improve stereo matching performance. A generative approach was employed to synthesize a dataset with ground-truth disparity from unannotated infrared images. This dataset was then fed to a pretrained stereo neural network for fine-tuning to achieve domain adaptation. Wave flume experiments were conducted to validate the feasibility and accuracy of the proposed technique. The final reconstruction results indicated great agreement and high accuracy with a mean bias of less than 2.1% compared with the measurements obtained using wave probes, suggesting that the novel technique effectively measures the spatiotemporal distribution of wave surface in hydrodynamic experiments.
Progressive residual learning for single image dehazing
Mar 14, 2021



The recent physical model-free dehazing methods have achieved state-of-the-art performances. However, without the guidance of physical models, the performances degrade rapidly when applied to real scenarios due to the unavailable or insufficient data problems. On the other hand, the physical model-based methods have better interpretability but suffer from multi-objective optimizations of parameters, which may lead to sub-optimal dehazing results. In this paper, a progressive residual learning strategy has been proposed to combine the physical model-free dehazing process with reformulated scattering model-based dehazing operations, which enjoys the merits of dehazing methods in both categories. Specifically, the global atmosphere light and transmission maps are interactively optimized with the aid of accurate residual information and preliminary dehazed restorations from the initial physical model-free dehazing process. The proposed method performs favorably against the state-of-the-art methods on public dehazing benchmarks with better model interpretability and adaptivity for complex hazy data.
Progressive Depth Learning for Single Image Dehazing
Feb 21, 2021

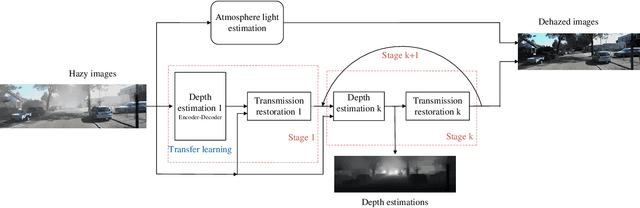

The formulation of the hazy image is mainly dominated by the reflected lights and ambient airlight. Existing dehazing methods often ignore the depth cues and fail in distant areas where heavier haze disturbs the visibility. However, we note that the guidance of the depth information for transmission estimation could remedy the decreased visibility as distances increase. In turn, the good transmission estimation could facilitate the depth estimation for hazy images. In this paper, a deep end-to-end model that iteratively estimates image depths and transmission maps is proposed to perform an effective depth prediction for hazy images and improve the dehazing performance with the guidance of depth information. The image depth and transmission map are progressively refined to better restore the dehazed image. Our approach benefits from explicitly modeling the inner relationship of image depth and transmission map, which is especially effective for distant hazy areas. Extensive results on the benchmarks demonstrate that our proposed network performs favorably against the state-of-the-art dehazing methods in terms of depth estimation and haze removal.
Interpretable Machine Learning Model for Early Prediction of Mortality in Elderly Patients with Multiple Organ Dysfunction Syndrome (MODS): a Multicenter Retrospective Study and Cross Validation
Jan 28, 2020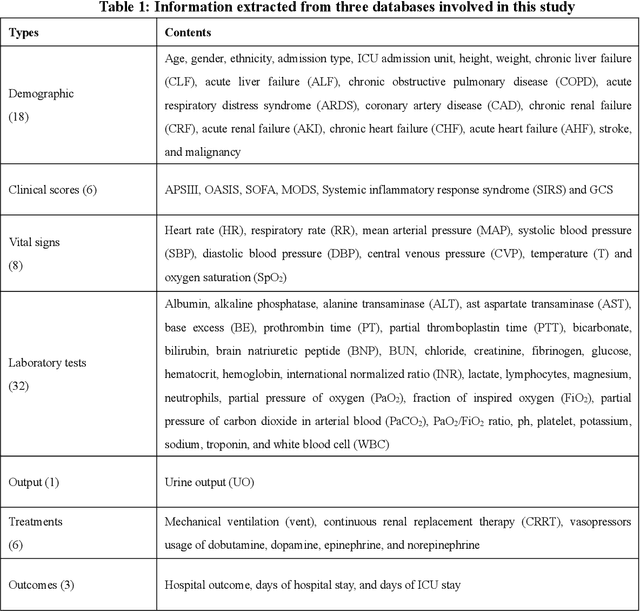
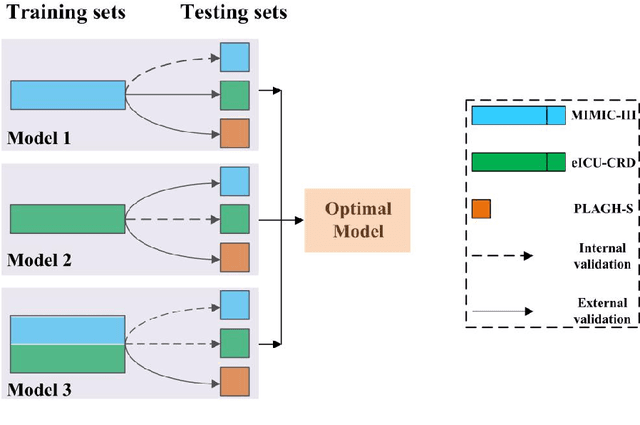
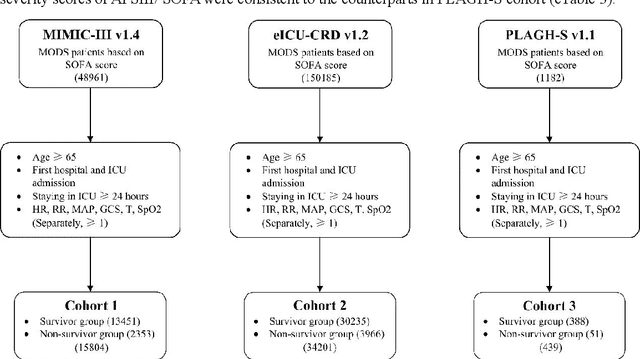
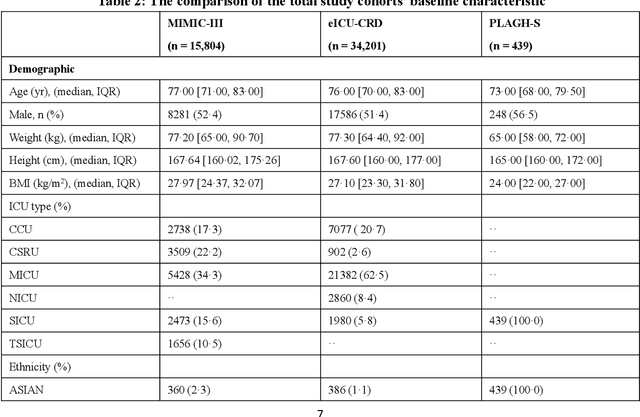
Background: Elderly patients with MODS have high risk of death and poor prognosis. The performance of current scoring systems assessing the severity of MODS and its mortality remains unsatisfactory. This study aims to develop an interpretable and generalizable model for early mortality prediction in elderly patients with MODS. Methods: The MIMIC-III, eICU-CRD and PLAGH-S databases were employed for model generation and evaluation. We used the eXtreme Gradient Boosting model with the SHapley Additive exPlanations method to conduct early and interpretable predictions of patients' hospital outcome. Three types of data source combinations and five typical evaluation indexes were adopted to develop a generalizable model. Findings: The interpretable model, with optimal performance developed by using MIMIC-III and eICU-CRD datasets, was separately validated in MIMIC-III, eICU-CRD and PLAGH-S datasets (no overlapping with training set). The performances of the model in predicting hospital mortality as validated by the three datasets were: AUC of 0.858, sensitivity of 0.834 and specificity of 0.705; AUC of 0.849, sensitivity of 0.763 and specificity of 0.784; and AUC of 0.838, sensitivity of 0.882 and specificity of 0.691, respectively. Comparisons of AUC between this model and baseline models with MIMIC-III dataset validation showed superior performances of this model; In addition, comparisons in AUC between this model and commonly used clinical scores showed significantly better performance of this model. Interpretation: The interpretable machine learning model developed in this study using fused datasets with large sample sizes was robust and generalizable. This model outperformed the baseline models and several clinical scores for early prediction of mortality in elderly ICU patients. The interpretative nature of this model provided clinicians with the ranking of mortality risk features.
Logic could be learned from images
Aug 06, 2019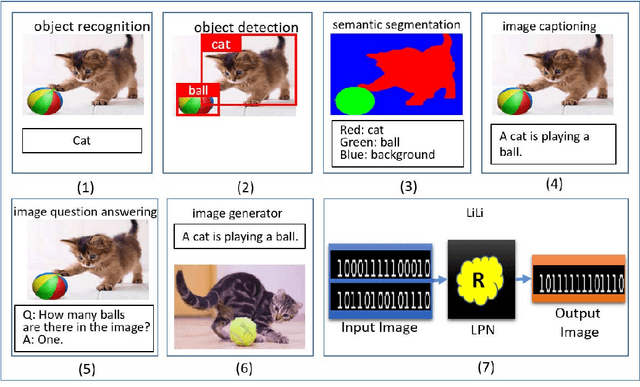

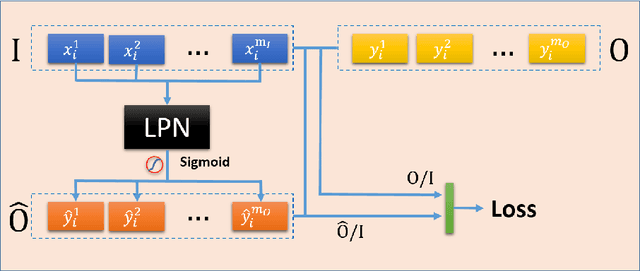
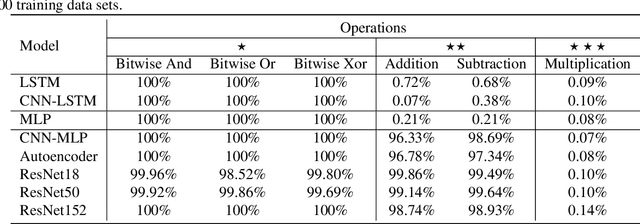
Logic reasoning is a significant ability of human intelligence and also an important task in artificial intelligence. The existing logic reasoning methods, quite often, need to design some reasoning patterns beforehand. This has led to an interesting question: can logic reasoning patterns be directly learned from given data? The problem is termed as a data concept logic (DCL). In this study, a learning logic task from images, just a LiLi task, first is proposed. This task is to learn and reason the relation between two input images and one output image, without presetting any reasoning patterns. As a preliminary exploration, we design six LiLi data sets (Bitwise And, Bitwise Or, Bitwise Xor, Addition, Subtraction and Multiplication), in which each image is embedded with a n-digit number. It is worth noting that a learning model beforehand does not know the meaning of the n-digit number embedded in images and relation between the input images and the output image. In order to tackle the task, in this work we use many typical neural network models and produce fruitful results. However, these models have the poor performances on the difficult logic task. For furthermore addressing this task, a novel network framework called a divide and conquer model (DCM) by adding some prior information is designed, achieving a high testing accuracy.