 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on Neural Routing Solvers
Feb 25, 2026Neural routing solvers (NRSs) that leverage deep learning to tackle vehicle routing problems have demonstrated notable potential for practical applications. By learning implicit heuristic rules from data, NRSs replace the handcrafted counterparts in classic heuristic frameworks, thereby reducing reliance on costly manual design and trial-and-error adjustments. This survey makes two main contributions: (1) The heuristic nature of NRSs is highlighted, and existing NRSs are reviewed from the perspective of heuristics. A hierarchical taxonomy based on heuristic principles is further introduced. (2) A generalization-focused evaluation pipeline is proposed to address limitations of the conventional pipeline. Comparative benchmarking of representative NRSs across both pipelines uncovers a series of previously unreported gaps in current research.
Adversarial Graph Fusion for Incomplete Multi-view Semi-supervised Learning with Tensorial Imputation
Sep 19, 2025



View missing remains a significant challenge in graph-based multi-view semi-supervised learning, hindering their real-world applications. To address this issue, traditional methods introduce a missing indicator matrix and focus on mining partial structure among existing samples in each view for label propagation (LP). However, we argue that these disregarded missing samples sometimes induce discontinuous local structures, i.e., sub-clusters, breaking the fundamental smoothness assumption in LP. Consequently, such a Sub-Cluster Problem (SCP) would distort graph fusion and degrade classification performance. To alleviate SCP, we propose a novel incomplete multi-view semi-supervised learning method, termed AGF-TI. Firstly, we design an adversarial graph fusion scheme to learn a robust consensus graph against the distorted local structure through a min-max framework. By stacking all similarity matrices into a tensor, we further recover the incomplete structure from the high-order consistency information based on the low-rank tensor learning. Additionally, the anchor-based strategy is incorporated to reduce the computational complexity. An efficient alternative optimization algorithm combining a reduced gradient descent method is developed to solve the formulated objective, with theoretical convergence. Extensive experimental results on various datasets validate the superiority of our proposed AGF-TI as compared to state-of-the-art methods. Code is available at https://github.com/ZhangqiJiang07/AGF_TI.
Logic could be learned from images
Aug 06, 2019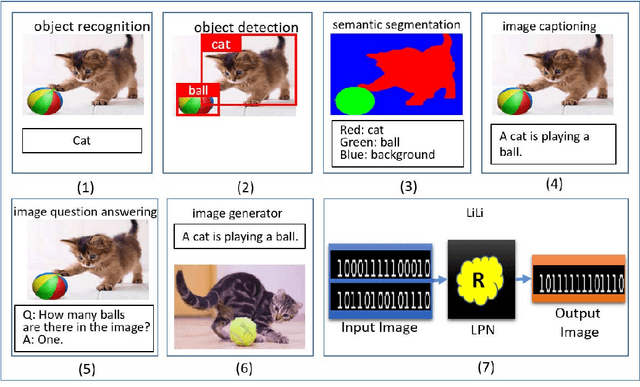

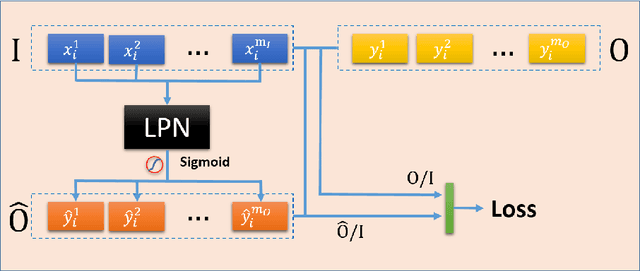
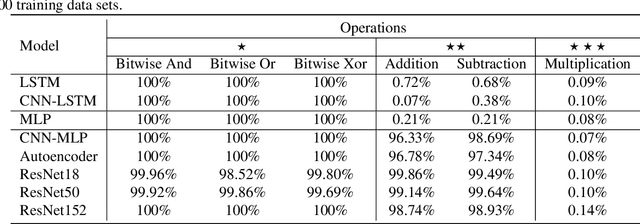
Logic reasoning is a significant ability of human intelligence and also an important task in artificial intelligence. The existing logic reasoning methods, quite often, need to design some reasoning patterns beforehand. This has led to an interesting question: can logic reasoning patterns be directly learned from given data? The problem is termed as a data concept logic (DCL). In this study, a learning logic task from images, just a LiLi task, first is proposed. This task is to learn and reason the relation between two input images and one output image, without presetting any reasoning patterns. As a preliminary exploration, we design six LiLi data sets (Bitwise And, Bitwise Or, Bitwise Xor, Addition, Subtraction and Multiplication), in which each image is embedded with a n-digit number. It is worth noting that a learning model beforehand does not know the meaning of the n-digit number embedded in images and relation between the input images and the output image. In order to tackle the task, in this work we use many typical neural network models and produce fruitful results. However, these models have the poor performances on the difficult logic task. For furthermore addressing this task, a novel network framework called a divide and conquer model (DCM) by adding some prior information is designed, achieving a high testing accuracy.
RGB-T Object Tracking:Benchmark and Baseline
May 23, 2018
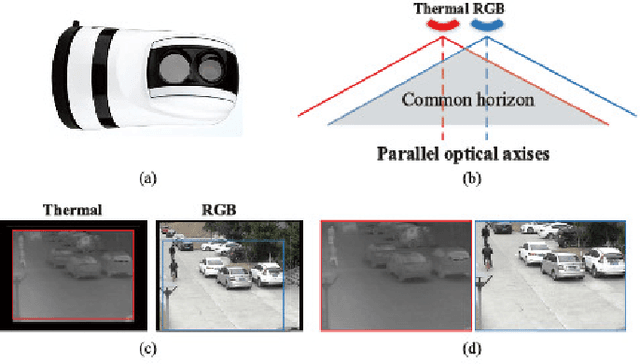
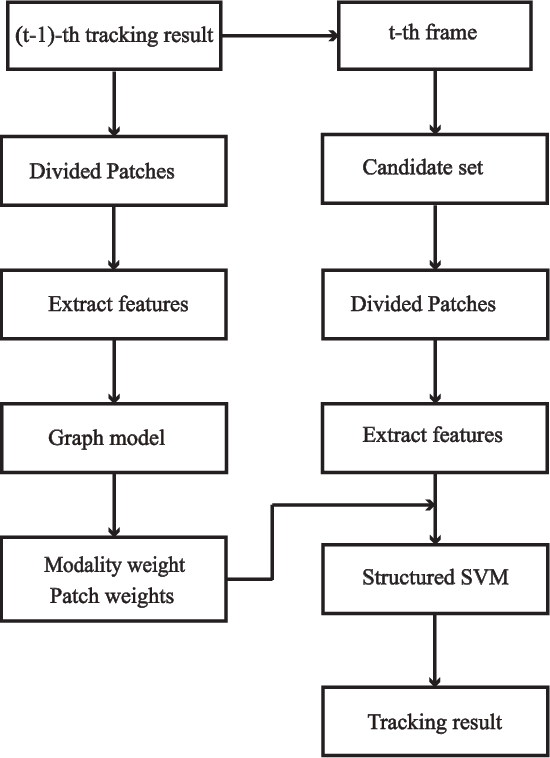

RGB-Thermal (RGB-T) object tracking receives more and more attention due to the strongly complementary benefits of thermal information to visible data. However, RGB-T research is limited by lacking a comprehensive evaluation platform. In this paper, we propose a large-scale video benchmark dataset for RGB-T tracking.It has three major advantages over existing ones: 1) Its size is sufficiently large for large-scale performance evaluation (total frame number: 234K, maximum frame per sequence: 8K). 2) The alignment between RGB-T sequence pairs is highly accurate, which does not need pre- or post-processing. 3) The occlusion levels are annotated for occlusion-sensitive performance analysis of different tracking algorithms.Moreover, we propose a novel graph-based approach to learn a robust object representation for RGB-T tracking. In particular, the tracked object is represented with a graph with image patches as nodes. This graph including graph structure, node weights and edge weights is dynamically learned in a unified ADMM (alternating direction method of multipliers)-based optimization framework, in which the modality weights are also incorporated for adaptive fusion of multiple source data.Extensive experiments on the large-scale dataset are executed to demonstrate the effectiveness of the proposed tracker against other state-of-the-art tracking methods. We also provide new insights and potential research directions to the field of RGB-T object tracking.